YOLOv11改进 – C3k2融合 C3k2融合MambaOut(CVPR 2025),简洁高效的视觉模型基线
# 前言
本文介绍了MambaOut模型,并将其集成到YOLOv11中。MambaOut由新加坡国立大学团队提出,旨在验证Mamba架构中状态空间模型(SSM)在视觉任务中的必要性。它移除了Mamba块中的SSM模块,仅保留基础的门控CNN结构。研究认为Mamba更适合长序列和自回归任务,图像分类无需Mamba,而目标检测和图像分割等长序列视觉任务有探索Mamba潜力的价值。实验构建MambaOut模型验证假设,结果显示其在图像分类任务上超越视觉Mamba模型,在检测与分割任务中无法达最先进水平。我们将MambaOut集成到YOLOv11,经注册和配置yaml文件后进行实验。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
介绍

摘要
Mamba 是一种采用类 RNN 的状态空间模型(SSM)作为 token 混合器的架构,最近被提出以解决注意力机制的平方复杂度问题,并被随后应用于视觉任务。然而,在视觉任务中,Mamba 的表现常常不如基于卷积和注意力机制的模型。
在本文中,我们深入剖析了 Mamba 的本质,并在概念上得出结论:Mamba 更适合具有长序列和自回归特性的任务。而对于视觉任务而言,图像分类既不具备长序列特性,也不具备自回归特性,因此我们假设在这一任务中并不需要 Mamba;尽管目标检测和图像分割任务也不具备自回归特性,但它们符合长序列的特点,因此我们认为仍有探索 Mamba 在这些任务中潜力的价值。
为实证验证我们的假设,我们构建了一系列名为 MambaOut 的模型,这些模型通过堆叠 Mamba 块构成,但去除了其核心 token 混合器——SSM。实验结果强烈支持我们的假设:具体而言,MambaOut 模型在 ImageNet 图像分类任务上超越了所有视觉 Mamba 模型,表明 Mamba 确实在该任务中并非必要。而在检测与分割任务中,MambaOut 无法达到当前最先进视觉 Mamba 模型的性能,进一步说明了 Mamba 在长序列视觉任务中的潜力。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
MambaOut是由新加坡国立大学团队提出的一系列视觉模型,核心目标是验证Mamba架构的核心组件——状态空间模型(SSM)在视觉任务中的必要性。它通过移除Mamba块中的SSM模块,仅保留基础的门控CNN(Gated CNN)结构,构建出更简洁的模型,进而通过实验对比,揭示Mamba在不同视觉任务中的适用边界。
一、MambaOut的核心设计逻辑:从Mamba到“去SSM”
要理解MambaOut,首先需要明确它与Mamba的关联——MambaOut本质是Mamba的“简化对照版”,两者的核心差异在于是否包含SSM模块,具体设计逻辑如下:
1. 与Mamba的结构关联:移除SSM,保留基础框架
Mamba的核心模块是“Mamba块”,而Mamba块的基础是门控CNN块(Gated CNN Block),只是在门控CNN的基础上额外增加了SSM(状态空间模型)作为token混合器(Token Mixer),以实现长序列和自回归任务的高效处理(如图1(a)所示)。
MambaOut的设计思路则是“回归基础”:完全移除Mamba块中的SSM模块,仅堆叠门控CNN块构建完整模型。这种设计的目的是通过“控制变量”验证:Mamba在视觉任务中的性能,究竟是来自SSM的贡献,还是其基础门控CNN结构本身的能力。
2. 门控CNN块:MambaOut的核心组件
门控CNN块是MambaOut的“最小功能单元”,其结构和实现遵循简洁高效的原则,具体细节如下:
-
核心功能:通过“归一化→线性拆分→深度卷积→门控融合→残差连接”的流程,完成特征提取和token混合,无需依赖SSM的复杂状态空间计算。
-
关键设计细节:
- 归一化:采用LayerNorm对输入特征进行归一化,稳定训练过程;
- 通道拆分:通过全连接层将输入特征拆分为三个分支——门控分支(g)、普通分支(i)、卷积分支(c),其中卷积分支仅占部分通道(参考InceptionNeXt的设计,提升计算效率);
- 深度卷积:卷积分支采用7×7大小的深度卷积(Depthwise Conv,参考ConvNeXt),仅在局部通道内进行空间特征提取,平衡性能与计算量;
- 门控融合:将激活后的门控分支与“普通分支+卷积分支”的拼接结果逐元素相乘,实现特征的选择性融合;
- 残差连接:保留残差路径,避免深层网络的梯度消失问题。
核心代码
class GatedCNNBlock(nn.Module):
def __init__(self, dim, expansion_ratio=8/3, kernel_size=7, conv_ratio=1.0,
norm_layer=partial(nn.LayerNorm,eps=1e-6),
act_layer=nn.GELU,
drop_path=0.,
**kwargs):
super().__init__()
self.norm = norm_layer(dim)
hidden = int(expansion_ratio * dim)
self.fc1 = nn.Linear(dim, hidden * 2)
self.act = act_layer()
conv_channels = int(conv_ratio * dim)
self.split_indices = (hidden, hidden - conv_channels, conv_channels)
self.conv = nn.Conv2d(conv_channels, conv_channels, kernel_size=kernel_size, padding=kernel_size//2, groups=conv_channels)
self.fc2 = nn.Linear(hidden, dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
shortcut = x # [B, H, W, C]
x = self.norm(x)
g, i, c = torch.split(self.fc1(x), self.split_indices, dim=-1)
c = c.permute(0, 3, 1, 2) # [B, H, W, C] -> [B, C, H, W]
c = self.conv(c)
c = c.permute(0, 2, 3, 1) # [B, C, H, W] -> [B, H, W, C]
x = self.fc2(self.act(g) * torch.cat((i, c), dim=-1))
x = self.drop_path(x)
return x + shortcut
class LayerNormGeneral(nn.Module):
def __init__(self, affine_shape=None, normalized_dim=(-1, ), scale=True,
bias=True, eps=1e-5):
super().__init__()
self.normalized_dim = normalized_dim
self.use_scale = scale
self.use_bias = bias
self.weight = nn.Parameter(torch.ones(affine_shape)) if scale else None
self.bias = nn.Parameter(torch.zeros(affine_shape)) if bias else None
self.eps = eps
def forward(self, x):
c = x - x.mean(self.normalized_dim, keepdim=True)
s = c.pow(2).mean(self.normalized_dim, keepdim=True)
x = c / torch.sqrt(s + self.eps)
if self.use_scale:
x = x * self.weight
if self.use_bias:
x = x + self.bias
return x
class GatedCNNBlock_BCHW(nn.Module):
r""" Our implementation of Gated CNN Block: https://arxiv.org/pdf/1612.08083
Args:
conv_ratio: control the number of channels to conduct depthwise convolution.
Conduct convolution on partial channels can improve practical efficiency.
The idea of partial channels is from ShuffleNet V2 (https://arxiv.org/abs/1807.11164) and
also used by InceptionNeXt (https://arxiv.org/abs/2303.16900) and FasterNet (https://arxiv.org/abs/2303.03667)
"""
def __init__(self, dim, expansion_ratio=8/3, kernel_size=7, conv_ratio=1.0,
norm_layer=partial(LayerNormGeneral,eps=1e-6,normalized_dim=(1, 2, 3)),
act_layer=nn.GELU,
drop_path=0.,
**kwargs):
super().__init__()
self.norm = norm_layer((dim, 1, 1))
hidden = int(expansion_ratio * dim)
self.fc1 = nn.Conv2d(dim, hidden * 2, 1)
self.act = act_layer()
conv_channels = int(conv_ratio * dim)
self.split_indices = (hidden, hidden - conv_channels, conv_channels)
self.conv = nn.Conv2d(conv_channels, conv_channels, kernel_size=kernel_size, padding=kernel_size//2, groups=conv_channels)
self.fc2 = nn.Conv2d(hidden, dim, 1)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
shortcut = x # [B, H, W, C]
x = self.norm(x)
g, i, c = torch.split(self.fc1(x), self.split_indices, dim=1)
# c = c.permute(0, 3, 1, 2) # [B, H, W, C] -> [B, C, H, W]
c = self.conv(c)
# c = c.permute(0, 2, 3, 1) # [B, C, H, W] -> [B, H, W, C]
x = self.fc2(self.act(g) * torch.cat((i, c), dim=1))
x = self.drop_path(x)
return x + shortcut
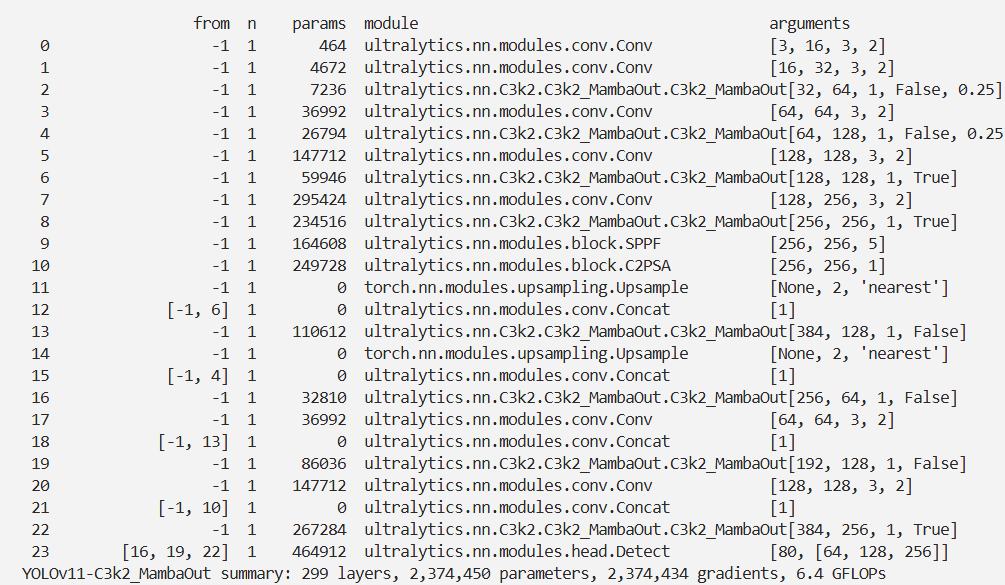
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
#
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/11/yolov11-C3k2_MambaOut.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='SGD',
amp=True,
project='runs/train',
name='C3k2_MambaOut',
)
结果