YOLOv11改进 – Mamba ASSG (Attentive State Space Group) 注意力状态空间组:增强全局上下文感知 CVPR 2025
# 前言
本文介绍了MambaIRv2,它赋予Mamba非因果建模能力以实现注意力状态空间恢复模型。Mamba架构在图像恢复中存在因果建模局限,MambaIRv2提出注意力状态空间方程,还引入语义引导的邻域机制。实验表明,在轻量级和经典超分辨率任务中,MambaIRv2比其他模型有更好的峰值信噪比表现。我们将其核心组件Attentive State Space Group(ASSG)引入YOLOv11,该组件整合局部与全局特征建模,通过多个基础功能块实现特征层级建模。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
介绍

摘要
基于曼巴(Mamba)的图像恢复主干网络最近在平衡全局感知和计算效率方面展现出了巨大潜力。然而,曼巴固有的因果建模局限性——即扫描序列中的每个标记仅依赖于其前序标记,限制了对图像中所有像素的充分利用,从而给图像恢复带来了新的挑战。在这项工作中,我们提出了 MambaIRv2,它赋予了曼巴类似于视觉变换器(ViTs)的非因果建模能力,以实现注意力状态空间恢复模型。具体而言,所提出的注意力状态空间方程允许关注扫描序列之外的内容,并仅通过一次扫描就促进图像展开。此外,我们还引入了一种语义引导的邻域机制,以促进相距较远但相似的像素之间的交互。大量实验表明,对于轻量级超分辨率(SR)任务,即使 MambaIRv2 的参数减少了 9.3%,其峰值信噪比(PSNR)仍比 SRFormer 高出 0.35dB;在经典超分辨率任务中,它比 HAT 模型的 PSNR 最多可高出 0.29dB。代码可在 https://github.com/csguoh/MambaIR 获取。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
Attentive State Space Group(ASSG,注意力状态空间组) 是MambaIRv2网络架构的核心中层组件,主要功能是整合“局部特征交互”与“全局特征建模”,为低质量图像到高质量图像的修复提供关键的特征加工能力,是实现“Attentive State Space Restoration(注意力状态空间修复)”框架的核心执行单元。
一、核心定位:连接浅层特征与任务重建的“中间处理器”
MambaIRv2的整体流程是“浅层特征提取→特征递进加工→任务专属重建”,而ASSG正处于“特征递进加工”环节,是承接“3×3卷积提取的基础特征”与“超分/去噪等重建模块”的关键桥梁。
它的核心目标是:通过组合多个基础功能块,实现“从局部细节到全局依赖”的特征层级建模,既保留Mamba模型“计算高效”的优势,又补充ViT模型“全局感知”的能力,最终为后续重建提供高质量的特征表示。
二、内部构成:以“块”为单位的模块化组合
ASSG并非单一结构,而是由多个Attentive State Space Block(ASSB,注意力状态空间块) 堆叠而成,每个ASSB遵循“标准化→特征混合→标准化→前馈网络”的基础模板,具体拆解如下:
| 组件层级 | 核心构成 | 功能分工 |
|---|---|---|
| ASSG(组) | 多个ASSB + 残差连接 | 整体负责多轮特征递进加工,逐步优化全局与局部特征的融合效果 |
| ASSB(块) | Norm → Token Mixer → Norm → FFN | 单轮特征处理的基础单元,其中“Token Mixer”是核心,分“局部”和“全局”两部分 |
| Token Mixer | 1. 窗口多头自注意力(MHSA) | 负责局部特征交互:在固定窗口内强化相邻像素的细节关联(如边缘、纹理) |
| 2. 注意力状态空间模块(ASSM) | 负责全局特征建模:整合ASE(注意力状态空间方程)和SGN(语义引导邻域),捕捉全图像素依赖 | |
| FFN(前馈网络) | 线性层 + 激活函数 | 对混合后的特征进行非线性变换,增强模型的表达能力 |
| 残差连接 | 带可学习尺度的残差路径 | 避免梯度消失,确保浅层特征能有效传递到深层,提升训练稳定性 |
YOLO11引入代码
在根目录下的ultralytics/nn/目录,新建一个mamba目录,然后新建一个以 ASSG为文件名的py文件, 把代码拷贝进去。
"""
NOTE: the ConvFFN in Line should be replaced with the GatedMLP class if one want to test on lightSR
"""
import math
import numpy as np
import torch
import torch.nn as nn
import torch.utils.checkpoint as checkpoint
import torch.nn.functional as F
from basicsr.archs.arch_util import to_2tuple, trunc_normal_
from mamba_ssm.ops.selective_scan_interface import selective_scan_fn, selective_scan_ref
from einops import rearrange, repeat
def index_reverse(index):
index_r = torch.zeros_like(index)
ind = torch.arange(0, index.shape[-1]).to(index.device)
for i in range(index.shape[0]):
index_r[i, index[i, :]] = ind
return index_r
def semantic_neighbor(x, index):
dim = index.dim()
assert x.shape[:dim] == index.shape, "x ({:}) and index ({:}) shape incompatible".format(x.shape, index.shape)
for _ in range(x.dim() - index.dim()):
index = index.unsqueeze(-1)
index = index.expand(x.shape)
shuffled_x = torch.gather(x, dim=dim - 1, index=index)
return shuffled_x
class dwconv(nn.Module):
def __init__(self, hidden_features, kernel_size=5):
super(dwconv, self).__init__()
self.depthwise_conv = nn.Sequential(
nn.Conv2d(hidden_features, hidden_features, kernel_size=kernel_size, stride=1,
padding=(kernel_size - 1) // 2, dilation=1,
groups=hidden_features), nn.GELU())
self.hidden_features = hidden_features
def forward(self, x, x_size):
x = x.transpose(1, 2).view(x.shape[0], self.hidden_features, x_size[0], x_size[1]).contiguous() # b Ph*Pw c
x = self.depthwise_conv(x)
x = x.flatten(2).transpose(1, 2).contiguous()
return x
class ConvFFN(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, kernel_size=5, act_layer=nn.GELU):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.dwconv = dwconv(hidden_features=hidden_features, kernel_size=kernel_size)
self.fc2 = nn.Linear(hidden_features, out_features)
def forward(self, x, x_size):
x = self.fc1(x)
x = self.act(x)
x = x + self.dwconv(x, x_size)
x = self.fc2(x)
return x
class Gate(nn.Module):
def __init__(self, dim):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.conv = nn.Conv2d(dim, dim, kernel_size=5, stride=1, padding=2, groups=dim) # DW Conv
def forward(self, x, H, W):
# Split
x1, x2 = x.chunk(2, dim = -1)
B, N, C = x.shape
x2 = self.conv(self.norm(x2).transpose(1, 2).contiguous().view(B, C//2, H, W)).flatten(2).transpose(-1, -2).contiguous()
return x1 * x2
class GatedMLP(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.sg = Gate(hidden_features//2)
self.fc2 = nn.Linear(hidden_features//2, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x, x_size):
"""
Input: x: (B, H*W, C), H, W
Output: x: (B, H*W, C)
"""
H,W = x_size
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.sg(x, H, W)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
def window_partition(x, window_size):
"""
Args:
x: (b, h, w, c)
window_size (int): window size
Returns:
windows: (num_windows*b, window_size, window_size, c)
"""
b, h, w, c = x.shape
x = x.view(b, h // window_size, window_size, w // window_size, window_size, c)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, c)
return windows
def window_reverse(windows, window_size, h, w):
"""
Args:
windows: (num_windows*b, window_size, window_size, c)
window_size (int): Window size
h (int): Height of image
w (int): Width of image
Returns:
x: (b, h, w, c)
"""
b = int(windows.shape[0] / (h * w / window_size / window_size))
x = windows.view(b, h // window_size, w // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(b, h, w, -1)
return x
class WindowAttention(nn.Module):
r"""
Shifted Window-based Multi-head Self-Attention
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
self.qkv_bias = qkv_bias
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
self.proj = nn.Linear(dim, dim)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, qkv, rpi, mask=None):
r"""
Args:
qkv: Input query, key, and value tokens with shape of (num_windows*b, n, c*3)
rpi: Relative position index
mask (0/-inf): Mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
b_, n, c3 = qkv.shape
c = c3 // 3
qkv = qkv.reshape(b_, n, 3, self.num_heads, c // self.num_heads).permute(2, 0, 3, 1, 4).contiguous()
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[rpi.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nw = mask.shape[0]
attn = attn.view(b_ // nw, nw, self.num_heads, n, n) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, n, n)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
x = (attn @ v).transpose(1, 2).reshape(b_, n, c)
x = self.proj(x)
return x
def extra_repr(self) -> str:
return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}, qkv_bias={self.qkv_bias}'
class ASSM(nn.Module):
def __init__(self, dim, d_state, num_tokens=64, inner_rank=128, mlp_ratio=2.):
super().__init__()
self.dim = dim
self.num_tokens = num_tokens
self.inner_rank = inner_rank
# Mamba params
self.expand = mlp_ratio
hidden = int(self.dim * self.expand)
self.d_state = d_state
self.selectiveScan = Selective_Scan(d_model=hidden, d_state=self.d_state, expand=1)
self.out_norm = nn.LayerNorm(hidden)
self.act = nn.SiLU()
self.out_proj = nn.Linear(hidden, dim, bias=True)
self.in_proj = nn.Sequential(
nn.Conv2d(self.dim, hidden, 1, 1, 0),
)
self.CPE = nn.Sequential(
nn.Conv2d(hidden, hidden, 3, 1, 1, groups=hidden),
)
self.embeddingB = nn.Embedding(self.num_tokens, self.inner_rank) # [64,32] [32, 48] = [64,48]
self.embeddingB.weight.data.uniform_(-1 / self.num_tokens, 1 / self.num_tokens)
self.route = nn.Sequential(
nn.Linear(self.dim, self.dim // 3),
nn.GELU(),
nn.Linear(self.dim // 3, self.num_tokens),
nn.LogSoftmax(dim=-1)
)
def forward(self, x, x_size, token):
B, n, C = x.shape
H, W = x_size
full_embedding = self.embeddingB.weight @ token.weight # [128, C]
pred_route = self.route(x) # [B, HW, num_token]
cls_policy = F.gumbel_softmax(pred_route, hard=True, dim=-1) # [B, HW, num_token]
prompt = torch.matmul(cls_policy, full_embedding).view(B, n, self.d_state)
detached_index = torch.argmax(cls_policy.detach(), dim=-1, keepdim=False).view(B, n) # [B, HW]
x_sort_values, x_sort_indices = torch.sort(detached_index, dim=-1, stable=False)
x_sort_indices_reverse = index_reverse(x_sort_indices)
x = x.permute(0, 2, 1).reshape(B, C, H, W).contiguous()
x = self.in_proj(x)
x = x * torch.sigmoid(self.CPE(x))
cc = x.shape[1]
x = x.view(B, cc, -1).contiguous().permute(0, 2, 1) # b,n,c
semantic_x = semantic_neighbor(x, x_sort_indices)
y = self.selectiveScan(semantic_x, prompt).to(x.dtype)
y = self.out_proj(self.out_norm(y))
x = semantic_neighbor(y, x_sort_indices_reverse)
return x
class Selective_Scan(nn.Module):
def __init__(
self,
d_model,
d_state=16,
expand=2.,
dt_rank="auto",
dt_min=0.001,
dt_max=0.1,
dt_init="random",
dt_scale=1.0,
dt_init_floor=1e-4,
device=None,
dtype=None,
**kwargs,
):
factory_kwargs = {"device": device, "dtype": dtype}
super().__init__()
self.d_model = d_model
self.d_state = d_state
self.expand = expand
self.d_inner = int(self.expand * self.d_model)
self.dt_rank = math.ceil(self.d_model / 16) if dt_rank == "auto" else dt_rank
self.x_proj = (
nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs),
)
self.x_proj_weight = nn.Parameter(torch.stack([t.weight for t in self.x_proj], dim=0)) # (K=4, N, inner)
del self.x_proj
self.dt_projs = (
self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor,
**factory_kwargs),
)
self.dt_projs_weight = nn.Parameter(torch.stack([t.weight for t in self.dt_projs], dim=0)) # (K=4, inner, rank)
self.dt_projs_bias = nn.Parameter(torch.stack([t.bias for t in self.dt_projs], dim=0)) # (K=4, inner)
del self.dt_projs
self.A_logs = self.A_log_init(self.d_state, self.d_inner, copies=1, merge=True) # (K=4, D, N)
self.Ds = self.D_init(self.d_inner, copies=1, merge=True) # (K=4, D, N)
self.selective_scan = selective_scan_fn
@staticmethod
def dt_init(dt_rank, d_inner, dt_scale=1.0, dt_init="random", dt_min=0.001, dt_max=0.1, dt_init_floor=1e-4,
**factory_kwargs):
dt_proj = nn.Linear(dt_rank, d_inner, bias=True, **factory_kwargs)
# Initialize special dt projection to preserve variance at initialization
dt_init_std = dt_rank ** -0.5 * dt_scale
if dt_init == "constant":
nn.init.constant_(dt_proj.weight, dt_init_std)
elif dt_init == "random":
nn.init.uniform_(dt_proj.weight, -dt_init_std, dt_init_std)
else:
raise NotImplementedError
# Initialize dt bias so that F.softplus(dt_bias) is between dt_min and dt_max
dt = torch.exp(
torch.rand(d_inner, **factory_kwargs) * (math.log(dt_max) - math.log(dt_min))
+ math.log(dt_min)
).clamp(min=dt_init_floor)
# Inverse of softplus: https://github.com/pytorch/pytorch/issues/72759
inv_dt = dt + torch.log(-torch.expm1(-dt))
with torch.no_grad():
dt_proj.bias.copy_(inv_dt)
# Our initialization would set all Linear.bias to zero, need to mark this one as _no_reinit
dt_proj.bias._no_reinit = True
return dt_proj
@staticmethod
def A_log_init(d_state, d_inner, copies=1, device=None, merge=True):
# S4D real initialization
A = repeat(
torch.arange(1, d_state + 1, dtype=torch.float32, device=device),
"n -> d n",
d=d_inner,
).contiguous()
A_log = torch.log(A) # Keep A_log in fp32
if copies > 1:
A_log = repeat(A_log, "d n -> r d n", r=copies)
if merge:
A_log = A_log.flatten(0, 1)
A_log = nn.Parameter(A_log)
A_log._no_weight_decay = True
return A_log
@staticmethod
def D_init(d_inner, copies=1, device=None, merge=True):
# D "skip" parameter
D = torch.ones(d_inner, device=device)
if copies > 1:
D = repeat(D, "n1 -> r n1", r=copies)
if merge:
D = D.flatten(0, 1)
D = nn.Parameter(D) # Keep in fp32
D._no_weight_decay = True
return D
def forward_core(self, x: torch.Tensor, prompt):
B, L, C = x.shape
K = 1 # mambairV2 needs noly 1 scan
xs = x.permute(0,2,1).view(B,1,C,L).contiguous() # B, 1, C ,L
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs.view(B, K, -1, L), self.x_proj_weight)
dts, Bs, Cs = torch.split(x_dbl, [self.dt_rank, self.d_state, self.d_state], dim=2)
dts = torch.einsum("b k r l, k d r -> b k d l", dts.view(B, K, -1, L), self.dt_projs_weight)
xs = xs.float().view(B, -1, L)
dts = dts.contiguous().float().view(B, -1, L) # (b, k * d, l)
Bs = Bs.float().view(B, K, -1, L)
Cs = Cs.float().view(B, K, -1, L) + prompt # (b, k, d_state, l) our ASE here!
Ds = self.Ds.float().view(-1)
As = -torch.exp(self.A_logs.float()).view(-1, self.d_state)
dt_projs_bias = self.dt_projs_bias.float().view(-1) # (k * d)
out_y = self.selective_scan(
xs, dts,
As, Bs, Cs, Ds, z=None,
delta_bias=dt_projs_bias,
delta_softplus=True,
return_last_state=False,
).view(B, K, -1, L)
assert out_y.dtype == torch.float
return out_y[:, 0]
def forward(self, x: torch.Tensor, prompt, **kwargs):
b, l, c = prompt.shape
prompt = prompt.permute(0, 2, 1).contiguous().view(b, 1, c, l)
y = self.forward_core(x, prompt) # [B, L, C]
y = y.permute(0, 2, 1).contiguous()
return y
class ASSG(nn.Module):
def __init__(self,
dim,
d_state=8,
num_heads=4,
window_size=4,
shift_size=2,
inner_rank=32,
num_tokens=64,
convffn_kernel_size=5,
mlp_ratio=1,
qkv_bias=True,
norm_layer=nn.LayerNorm,
):
super().__init__()
dim = int(dim) if not isinstance(dim, int) else dim
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
self.convffn_kernel_size = convffn_kernel_size
self.num_tokens = num_tokens
self.softmax = nn.Softmax(dim=-1)
self.lrelu = nn.LeakyReLU()
self.sigmoid = nn.Sigmoid()
self.inner_rank = inner_rank
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
self.norm3 = norm_layer(dim)
self.norm4 = norm_layer(dim)
layer_scale = 1e-4
self.scale1 = nn.Parameter(layer_scale * torch.ones(dim), requires_grad=True)
self.scale2 = nn.Parameter(layer_scale * torch.ones(dim), requires_grad=True)
self.wqkv = nn.Linear(dim, 3 * dim, bias=qkv_bias)
self.win_mhsa = WindowAttention(
self.dim,
window_size=to_2tuple(self.window_size),
num_heads=num_heads,
qkv_bias=qkv_bias,
)
self.assm = ASSM(
self.dim,
d_state,
num_tokens=num_tokens,
inner_rank=inner_rank,
mlp_ratio=mlp_ratio
)
mlp_hidden_dim = int(dim * self.mlp_ratio)
self.convffn1 = GatedMLP(in_features=dim, hidden_features=mlp_hidden_dim, out_features=dim)
self.convffn2 = GatedMLP(in_features=dim, hidden_features=mlp_hidden_dim, out_features=dim)
self.embeddingA = nn.Embedding(self.inner_rank, d_state)
self.embeddingA.weight.data.uniform_(-1 / self.inner_rank, 1 / self.inner_rank)
def calculate_rpi_sa(self):
# calculate relative position index for SW-MSA
coords_h = torch.arange(self.window_size)
coords_w = torch.arange(self.window_size)
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size - 1
relative_coords[:, :, 0] *= 2 * self.window_size - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
return relative_position_index
def calculate_mask(self, x_size):
# calculate attention mask for SW-MSA
h, w = x_size
img_mask = torch.zeros((1, h, w, 1)) # 1 h w 1
h_slices = (slice(0, -self.window_size), slice(-self.window_size,
-(self.window_size // 2)), slice(-(self.window_size // 2), None))
w_slices = (slice(0, -self.window_size), slice(-self.window_size,
-(self.window_size // 2)), slice(-(self.window_size // 2), None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nw, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
def forward(self, x):
b, c, h, w = x.size()
x_size = (h, w)
n = h * w
x = x.flatten(2).permute(0, 2, 1).contiguous() # b h*w c
c3 = 3 * c
# Calculate attention mask and relative position index dynamically
attn_mask = self.calculate_mask((h, w)).to(x.device)
rpi = self.calculate_rpi_sa().to(x.device)
# part1: Window-MHSA
shortcut = x
x = self.norm1(x)
qkv = self.wqkv(x)
qkv = qkv.reshape(b, h, w, c3)
if self.shift_size > 0:
shifted_qkv = torch.roll(qkv, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_qkv = qkv
attn_mask = None
x_windows = window_partition(shifted_qkv, self.window_size)
x_windows = x_windows.view(-1, self.window_size * self.window_size, c3)
attn_windows = self.win_mhsa(x_windows, rpi=rpi, mask=attn_mask)
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, c)
shifted_x = window_reverse(attn_windows, self.window_size, h, w) # b h' w' c
if self.shift_size > 0:
attn_x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
attn_x = shifted_x
x_win = attn_x.view(b,n,c) + shortcut
x_win = self.convffn1(self.norm2(x_win), x_size) + x_win
x = shortcut * self.scale1 + x_win
# part2: Attentive State Space
shortcut = x
x_aca = self.assm(self.norm3(x), x_size, self.embeddingA) + x
x = x_aca + self.convffn2(self.norm4(x_aca), x_size)
x = shortcut * self.scale2 + x
return x.permute(0, 2, 1).reshape(b, c, h, w).contiguous()注册
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.mamba.ASSG import ASSG步骤2
修改def parse_model(d, ch, verbose=True):
elif m is ASSG:
c2 = ch[f]
args = [c2, *args]配置yolo11-ASSG.yaml
ultralytics/cfg/models/11/yolo11-ASSG.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
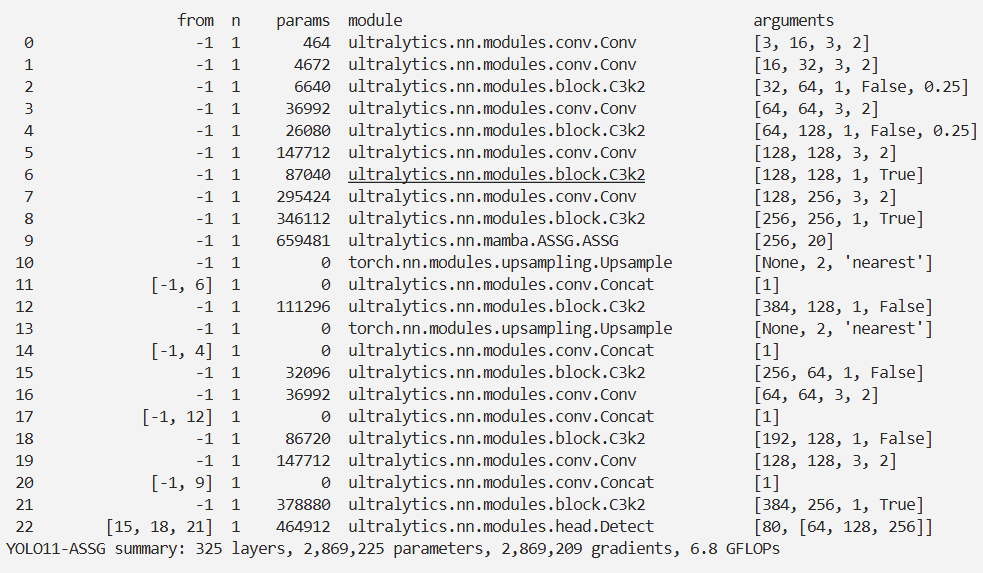
- [-1, 1, ASSG, [20]] # 9 这里可以修改 状态空间维度 增大:会增加模型的表达能力,但也会增加计算量和内存占用 ,减小:会减少计算量,但可能降低模型性能
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('/root/ultralytics-main/ultralytics/cfg/models/11/yolo11-ASSG.yaml')
# 修改为自己的数据集地址
model.train(data='/root/ultralytics-main/ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='SGD',
amp=True,
project='runs/train',
name='ASSG',
)
结果