YOLOv11改进 – C3k2融合 C3k2融合MBRConv 多分支重参数化卷积,MBRConv33用于深层特征提取
# 前言
本文介绍了超轻量化卷积神经网络(CNN)框架中的MBRConv相关模块及其在YOLOv11中的结合。为实现移动设备实时图像增强,该框架将重参数化与IWO策略结合,通过FST模块和HDPA机制提升性能。MBRConv是多分支重参数化卷积,有MBRConv3和MBRConv5两种变体,分别用于深层和浅层特征提取,能高效捕捉不同尺度特征。我们将MBRConv3集成进YOLOv11的C3k2模块,形成C3k2_MBRConv3,实验显示其有助于提升模型性能,适配移动设备资源约束。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总-CSDN博客
专栏链接: YOLOv11改进专栏
介绍

摘要
深度神经网络的最新进展推动了图像增强(IE)领域的重大突破。然而,由于深度学习模型对计算量和内存的高需求,在移动设备等资源受限平台上部署这类模型仍面临挑战。为应对这些问题并实现移动设备上的实时图像增强,我们提出了一种超轻量化卷积神经网络(CNN)框架,仅含约4K个参数。该方法将重参数化与增量权重优化(IWO)策略相结合,以保证模型效率;同时,通过特征自变换(FST)模块和分层双路径注意力(HDPA)机制提升性能,并采用局部方差加权(LVW)损失进行优化。借助这一高效框架,我们首次实现了高达1100帧/秒(FPS)的实时图像增强推理,同时提供具有竞争力的图像质量,在多个图像增强任务中达成了速度与性能的最佳平衡。相关代码将开源于https://github.com/AVC2-UESTC/MobileIE.git。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
一、MBRConv(Multi-Branch Reparameterized Convolution)
核心定义
MBRConv 是 MobileIE 中提出的多分支重参数化卷积,专门针对图像增强(IE)任务设计,核心目标是在轻量化前提下捕捉多尺度特征,同时通过重参数化平衡训练性能与推理效率。
核心设计与特性
- 多分支结构:包含多个不同卷积核大小的并行分支(如 1×1、3×1、1×3、3×3、5×5 等),可同时捕捉不同尺度的图像特征(局部细节与全局结构)。
- 并行 Batch Norm(BN)层:每个分支均配有独立 BN 层,虽 BN 在 IE 任务中效果有限,但能增强特征非线性表达,且训练后可与卷积核合并,不增加推理阶段开销。
- 训练-推理解耦:
- 训练时:多分支并行计算,通过不同分支的互补性提升特征提取能力;
- 推理时:所有分支通过重参数化(融合权重与偏置)转化为单个标准卷积,大幅降低计算复杂度和内存占用。
- 与传统重参数化的差异:相比 RepVGG 等方法,MBRConv 针对 IE 任务优化了分支组合(适配图像增强的特征需求),且保留 BN 层的非线性增益,提升模型对多样化图像退化场景的鲁棒性。
核心作用
- 高效捕捉多尺度特征,解决轻量化模型特征表达能力不足的问题;
- 重参数化后推理效率极高,适配移动设备的资源约束;
- 配合 Incremental Weight Optimization(IWO)策略,融合“冻结先验权重”与“可学习权重”,提升跨层特征整合能力。
二、MBRConv3(MBRConv3×3)
核心定义
MBRConv3 是 MBRConv 的3×3 核变体,即核心分支基于 3×3 及衍生小核(1×3、3×1、1×1),是 MobileIE 中用于深层特征提取的核心模块。
具体结构(基于文档图 3(a))
分支组成(以 MBRConv3×3 为例):
- 主分支:3×3 卷积 + BN 层(捕捉局部核心特征);
- 辅助分支:3×1 卷积 + BN 层、1×3 卷积 + BN 层(捕捉轴向特征,补充局部细节);
- 压缩分支:1×1 卷积 + BN 层(通道维度压缩与特征融合);
- 输出融合:所有分支特征经通道拼接(Channel-Wise Concatenation)后,通过 1×1 卷积(conv_out)整合为统一维度特征。
训练与推理机制
- 训练阶段:各分支独立计算,BN 层平滑特征分布,减少极端像素干扰;
- 推理阶段:通过重参数化将多分支(含 BN 参数)融合为单个 3×3 标准卷积,仅保留核心计算, latency 极低。
核心作用与应用
- 用于 MobileIE 的深层特征提取阶段(2 个 MBRConv3×3 串联),配合 FST 模块增强非线性特征交互;
- 聚焦中尺度特征捕捉,精准提取图像细节(如边缘、纹理),为后续 HDPA 注意力机制提供高质量特征输入;
- 经 IWO 策略优化后,核权重强化中心行/列特征,提升结构完整性恢复能力(文档图 8 验证)。
三、MBRConv5(MBRConv5×5)
核心定义
MBRConv5 是 MBRConv 的5×5 核变体,核心分支基于 5×5 及衍生核,是 MobileIE 中用于浅层特征提取的模块,专注于捕捉大尺度全局结构特征。
具体结构与特性
- 分支设计:延续 MBRConv 多分支逻辑,核心分支为 5×5 卷积 + BN 层,辅以 1×5、5×1、1×1 等衍生分支(文档未明确画出,但根据 MBRConv3×3 推导,保持多分支互补性);
- 核心差异:相比 MBRConv3×3,5×5 核的感受野更大,更适合捕捉图像全局结构(如整体轮廓、大尺度亮度差异);
- 训练-推理机制:与 MBRConv3×3 一致,训练时多分支并行,推理时重参数化为单个 5×5 标准卷积,无额外开销。
核心作用与应用
- 用于 MobileIE 的浅层特征提取第一步(文档 3.1 节):输入退化图像先经 MBRConv5×5 + PReLU 激活,快速捕捉全局结构特征,为深层特征提取奠定基础;
- 适配低光照、水下等退化场景的全局信息恢复(如整体亮度调整、大尺度色彩失真修正);
- 与 MBRConv3×3 形成“浅层大尺度捕捉 + 深层细节 refinement”的层级特征提取链路。
三者核心关系总结
| 模块 | 核心差异 | 应用阶段 | 核心功能 | 感受野/特征尺度 |
|---|---|---|---|---|
| MBRConv | 通用多分支重参数化框架 | 训练-推理全流程 | 多尺度特征提取+重参数化优化 | 灵活适配 |
| MBRConv3×3 | 3×3 及衍生小核分支 | 深层特征提取 | 中尺度细节捕捉与特征 refinement | 小(聚焦局部) |
| MBRConv5×5 | 5×5 及衍生大核分支 | 浅层特征提取 | 大尺度全局结构与全局信息捕捉 | 大(覆盖全局) |
核心代码
class MBRConv3(nn.Module):
def __init__(self, in_channels, out_channels, rep_scale=4):
super(MBRConv3, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.rep_scale = rep_scale
self.conv = nn.Conv2d(in_channels, out_channels * rep_scale, 3, 1, 1)
self.conv_bn = nn.Sequential(
nn.BatchNorm2d(out_channels * rep_scale)
)
self.conv1 = nn.Conv2d(in_channels, out_channels * rep_scale, 1)
self.conv1_bn = nn.Sequential(
nn.BatchNorm2d(out_channels * rep_scale)
)
self.conv_crossh = nn.Conv2d(in_channels, out_channels * rep_scale, (3, 1), 1, (1, 0))
self.conv_crossh_bn = nn.Sequential(
nn.BatchNorm2d(out_channels * rep_scale)
)
self.conv_crossv = nn.Conv2d(in_channels, out_channels * rep_scale, (1, 3), 1, (0, 1))
self.conv_crossv_bn = nn.Sequential(
nn.BatchNorm2d(out_channels * rep_scale)
)
self.conv_out = nn.Conv2d(out_channels * rep_scale * 8, out_channels, 1)
def forward(self, inp):
x0 = self.conv(inp)
x1 = self.conv1(inp)
x2 = self.conv_crossh(inp)
x3 = self.conv_crossv(inp)
x = torch.cat(
[ x0,x1,x2,x3,
self.conv_bn(x0),
self.conv1_bn(x1),
self.conv_crossh_bn(x2),
self.conv_crossv_bn(x3)],
1
)
out = self.conv_out(x)
return out
def slim(self):
conv_weight = self.conv.weight
conv_bias = self.conv.bias
conv1_weight = self.conv1.weight
conv1_bias = self.conv1.bias
conv1_weight = F.pad(conv1_weight, (1, 1, 1, 1))
conv_crossh_weight = self.conv_crossh.weight
conv_crossh_bias = self.conv_crossh.bias
conv_crossh_weight = F.pad(conv_crossh_weight, (1, 1, 0, 0))
conv_crossv_weight = self.conv_crossv.weight
conv_crossv_bias = self.conv_crossv.bias
conv_crossv_weight = F.pad(conv_crossv_weight, (0, 0, 1, 1))
# conv_bn
bn = self.conv_bn[0]
k = 1 / torch.sqrt(bn.running_var + bn.eps)
conv_bn_weight = self.conv.weight * k.unsqueeze(-1).unsqueeze(-1).unsqueeze(-1)
conv_bn_weight = conv_bn_weight * bn.weight.unsqueeze(-1).unsqueeze(-1).unsqueeze(-1)
conv_bn_bias = self.conv.bias * k + (-bn.running_mean * k)
conv_bn_bias = conv_bn_bias * bn.weight + bn.bias
# conv1_bn
bn = self.conv1_bn[0]
k = 1 / torch.sqrt(bn.running_var + bn.eps)
conv1_bn_weight = self.conv1.weight * k.unsqueeze(-1).unsqueeze(-1).unsqueeze(-1)
conv1_bn_weight = conv1_bn_weight * bn.weight.unsqueeze(-1).unsqueeze(-1).unsqueeze(-1)
conv1_bn_weight = F.pad(conv1_bn_weight, (1, 1, 1, 1))
conv1_bn_bias = self.conv1.bias * k + (-bn.running_mean * k)
conv1_bn_bias = conv1_bn_bias * bn.weight + bn.bias
# conv_crossh_bn
bn = self.conv_crossh_bn[0]
k = 1 / torch.sqrt(bn.running_var + bn.eps)
conv_crossh_bn_weight = self.conv_crossh.weight * k.unsqueeze(-1).unsqueeze(-1).unsqueeze(-1)
conv_crossh_bn_weight = conv_crossh_bn_weight * bn.weight.unsqueeze(-1).unsqueeze(-1).unsqueeze(-1)
conv_crossh_bn_weight = F.pad(conv_crossh_bn_weight, (1, 1, 0, 0))
conv_crossh_bn_bias = self.conv_crossh.bias * k + (-bn.running_mean * k)
conv_crossh_bn_bias = conv_crossh_bn_bias * bn.weight + bn.bias
# conv_crossv_bn
bn = self.conv_crossv_bn[0]
k = 1 / torch.sqrt(bn.running_var + bn.eps)
conv_crossv_bn_weight = self.conv_crossv.weight * k.unsqueeze(-1).unsqueeze(-1).unsqueeze(-1)
conv_crossv_bn_weight = conv_crossv_bn_weight * bn.weight.unsqueeze(-1).unsqueeze(-1).unsqueeze(-1)
conv_crossv_bn_weight = F.pad(conv_crossv_bn_weight, (0, 0, 1, 1))
conv_crossv_bn_bias = self.conv_crossv.bias * k + (-bn.running_mean * k)
conv_crossv_bn_bias = conv_crossv_bn_bias * bn.weight + bn.bias
weight = torch.cat([
conv_weight,
conv1_weight,
conv_crossh_weight,
conv_crossv_weight,
conv_bn_weight,
conv1_bn_weight,
conv_crossh_bn_weight,
conv_crossv_bn_weight
], dim=0)
bias = torch.cat([
conv_bias,
conv1_bias,
conv_crossh_bias,
conv_crossv_bias,
conv_bn_bias,
conv1_bn_bias,
conv_crossh_bn_bias,
conv_crossv_bn_bias
], dim=0)
weight_compress = self.conv_out.weight.squeeze()
weight = torch.matmul(weight_compress, weight.view(weight.size(0), -1))
weight = weight.view(self.conv_out.out_channels, self.in_channels, 3, 3)
bias = torch.matmul(weight_compress, bias.unsqueeze(-1)).squeeze(-1)
if self.conv_out.bias is not None:
bias += self.conv_out.bias
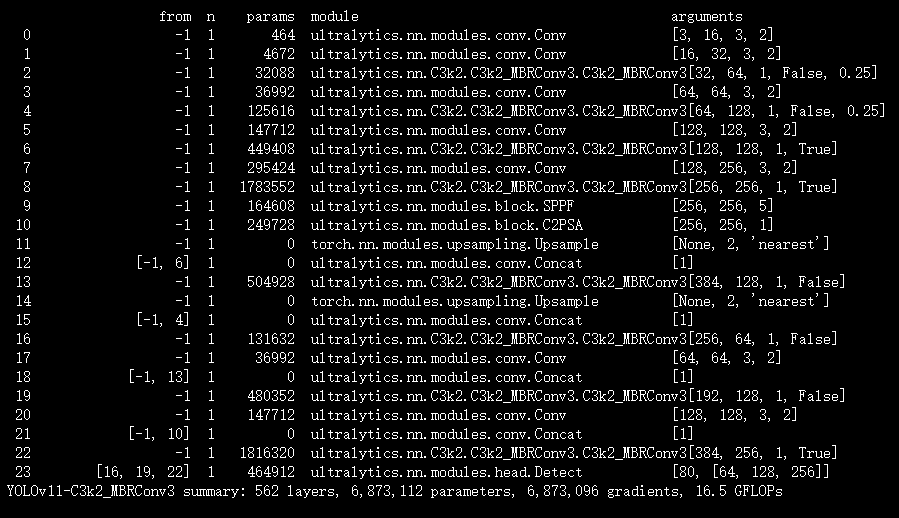
return weight, bias实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('/root/ultralytics-main/ultralytics/cfg/models/11/yolov11-C3k2_MBRConv3.yaml')
# 修改为自己的数据集地址
model.train(data='/root/ultralytics-main/ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='SGD',
amp=True,
project='runs/train',
name='C3k2_MBRConv3',
)
结果