YOLO26改进 – 卷积Conv SAConv可切换空洞卷积:自适应融合多尺度特征,优化小目标与遮挡目标感知
# 前言
本文介绍了Switchable Atrous Convolution(SAConv)及其在YOLO26中的结合。SAConv是DetectoRS目标检测系统关键组件,将输入特征与不同空洞率卷积,用开关函数组合结果。空洞卷积可扩大滤波器视野,SAC能适应不同对象尺度,开关函数具有空间相关性。在宏观和微观层面分别采用递归特征金字塔和可切换空洞卷积,实现双重观察机制。我们将骨干网络中的标准卷积层转换为SAConv集成进YOLO26,实验表明这显著提升了目标检测性能。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
介绍

摘要
许多现代目标检测器通过采用二次观察和思考机制展示了卓越的性能。在本文中,我们在目标检测的主干设计中探索了这一机制。在宏观层面上,我们提出了递归特征金字塔(Recursive Feature Pyramid),该金字塔将特征金字塔网络(Feature Pyramid Networks)的额外反馈连接融入到底层的自下而上主干层中。在微观层面上,我们提出了可切换空洞卷积(Switchable Atrous Convolution),该卷积通过不同的空洞率卷积特征,并使用切换函数汇集结果。结合这些方法,我们提出了DetectoRS,它显著提升了目标检测的性能。在COCO test-dev数据集上,DetectoRS实现了最先进的55.7%的目标检测框AP、48.5%的实例分割掩码AP和50.0%的全景分割PQ。代码已公开发布。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
Switchable Atrous Convolution(SAC)是DetectoRS目标检测系统的关键组件之一。它涉及将输入特征与不同的空洞率进行卷积,并利用开关函数将结果组合在一起。
-
空洞卷积:空洞卷积用于扩大滤波器的视野,而不增加参数或计算量。它根据空洞率𝑟在滤波器值之间引入零,从而扩大有效的核大小。
-
Switchable Atrous Convolution(SAC):
- 功能:SAC将输入特征与不同的空洞率进行卷积,并利用开关函数将结果组合在一起。
- 空间依赖性:开关函数是空间相关的,允许特征图上的不同位置具有不同的开关,控制SAC的输出。
- 转换:将骨干网络中的标准3x3卷积层转换为SAC,显著提高检测器性能。
- 示例:SAC的概念在图4中有所说明,显示了如何在不同的空洞率之间软切换卷积计算。
-
优势:
- 适应性:SAC通过为较大的对象使用较大的空洞率,适应不同的对象尺度。
- 性能:通过将SAC纳入检测器中,实现了目标检测性能的显著提升。
原理
Switchable Atrous Convolution(SAC)结合了双重观察机制和开关函数
-
双重观察机制的技术原理:
- 宏观层面:通过在特征金字塔网络(FPN)的输出和底层骨干网络之间添加反馈连接,实现了对特征的多次增强和迭代处理。这种反馈机制使得特征能够在不同层级上进行多次观察和处理,从而提高了特征的表征能力和鲁棒性。
- 微观层面:在微观层面,SAC通过在卷积过程中使用不同的空洞率和开关函数来实现“看两次”的概念。不同空洞率的卷积操作能够捕获不同尺度的特征信息,而开关函数则动态地选择不同空洞率下的卷积结果,以适应不同位置和尺度的特征需求。
-
开关函数的应用技术原理:
- 空间适应性:开关函数在空间上是位置相关的,允许不同位置的特征图有不同的开关控制,以实现对特征的精细调节和整合。
- 特征融合:开关函数动态地选择不同空洞率下的卷积结果,并将它们组合在一起,以获得更丰富和准确的特征表示。
- 性能提升:通过开关函数的应用,SAC能够适应不同尺度的对象,并在目标检测任务中提升性能,使系统更具鲁棒性和泛化能力。
核心代码
import torch
import torch.nn as nn
# 定义自动填充函数,以保证输出尺寸与输入尺寸相同
def autopad(k, p=None, d=1):
"""自动填充,确保卷积输出尺寸与输入尺寸相同。"""
# 如果使用了膨胀率,则重新计算实际的卷积核大小
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]
# 如果未指定填充,则自动计算填充大小
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
# ConvAWS2d类,继承自nn.Conv2d,添加了自适应权重标准化功能
class ConvAWS2d(nn.Conv2d):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True):
super().__init__(
in_channels, out_channels, kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
# 注册两个缓存参数,用于权重的标准化处理
self.register_buffer('weight_gamma', torch.ones(self.out_channels, 1, 1, 1))
self.register_buffer('weight_beta', torch.zeros(self.out_channels, 1, 1, 1))
# 权重处理函数,实现权重标准化
def _get_weight(self, weight):
# 计算权重的均值,并进行中心化
weight_mean = weight.mean(dim=1, keepdim=True).mean(dim=2, keepdim=True).mean(dim=3, keepdim=True)
weight = weight - weight_mean
# 计算标准化后的权重
std = torch.sqrt(weight.view(weight.size(0), -1).var(dim=1) + 1e-5).view(-1, 1, 1, 1)
weight = weight / std
weight = self.weight_gamma * weight + self.weight_beta
return weight
# 重写前向传播,使用标准化后的权重进行卷积
def forward(self, x):
weight = self._get_weight(self.weight)
return super()._conv_forward(x, weight, None)
# 从状态字典加载模型参数时的处理
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs):
# 此处初始化gamma为-1是为了在加载权重时进行特殊处理
self.weight_gamma.data.fill_(-1)
super()._load_from_state_dict(state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs)
# 检查gamma值,如果为正则跳过,否则重新初始化gamma和beta
if self.weight_gamma.data.mean() > 0:
return
weight = self.weight.data
weight_mean = weight.data.mean(dim=1, keepdim=True).mean(dim=2, keepdim=True).mean(dim=3, keepdim=True)
self.weight_beta.data.copy_(weight_mean)
std = torch.sqrt(weight.view(weight.size(0), -1).var(dim=1) + 1e-5).view(-1, 1, 1, 1)
self.weight_gamma.data.copy_(std)
# SAConv2d类,继承自ConvAWS2d,实现自适应开关卷积功能
class SAConv2d(ConvAWS2d):
def __init__(self, in_channels, out_channels, kernel_size, s=1, p=None, g=1, d=1, act=True, bias=True):
super().__init__(
in_channels, out_channels, kernel_size, stride=s, padding=autopad(kernel_size, p), dilation=d, groups=g, bias=bias)
# 定义一个1x1卷积作为开关机制
self.switch = torch.nn.Conv2d(
self.in_channels, 1, kernel_size=1, stride=s, bias=True)
self.switch.weight.data.fill_(0)
self.switch.bias.data.fill_(1)
# 参数,用于调整权重差异
self.weight_diff = torch.nn.Parameter(torch.Tensor(self.weight.size()))
self.weight_diff.data.zero_()
# 预先和后续的1x1卷积,用于实现上下文依赖
self.pre_context = torch.nn.Conv2d(
self.in_channels, self.in_channels, kernel_size=1, bias=True)
self.pre_context.weight.data.fill_(0)
self.pre_context.bias.data.fill_(0)
self.post_context = torch.nn.Conv2d(
self.out_channels, self.out_channels, kernel_size=1, bias=True)
self.post_context.weight.data.fill_(0)
self.post_context.bias.data.fill_(0)
# 批归一化和激活函数
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
# 前置上下文模块,增强输入特征
avg_x = torch.nn.functional.adaptive_avg_pool2d(x, output_size=1)
avg_x = self.pre_context(avg_x)
avg_x = avg_x.expand_as(x)
x = x + avg_x
# 使用开关控制不同的卷积核
avg_x = torch.nn.functional.pad(x, pad=(2, 2, 2, 2), mode="reflect")
avg_x = torch.nn.functional.avg_pool2d(avg_x, kernel_size=5, stride=1, padding=0)
switch = self.switch(avg_x)
# 标准化权重并进行卷积
weight = self._get_weight(self.weight)
out_s = super()._conv_forward(x, weight, None)
ori_p = self.padding
ori_d = self.dilation
self.padding = tuple(3 * p for p in self.padding)
self.dilation = tuple(3 * d for d in self.dilation)
weight = weight + self.weight_diff
out_l = super()._conv_forward(x, weight, None)
out = switch * out_s + (1 - switch) * out_l
self.padding = ori_p
self.dilation = ori_d
# 后置上下文模块,增强输出特征
avg_x = torch.nn.functional.adaptive_avg_pool2d(out, output_size=1)
avg_x = self.post_context(avg_x)
avg_x = avg_x.expand_as(out)
out = out + avg_x
return self.act(self.bn(out))实验
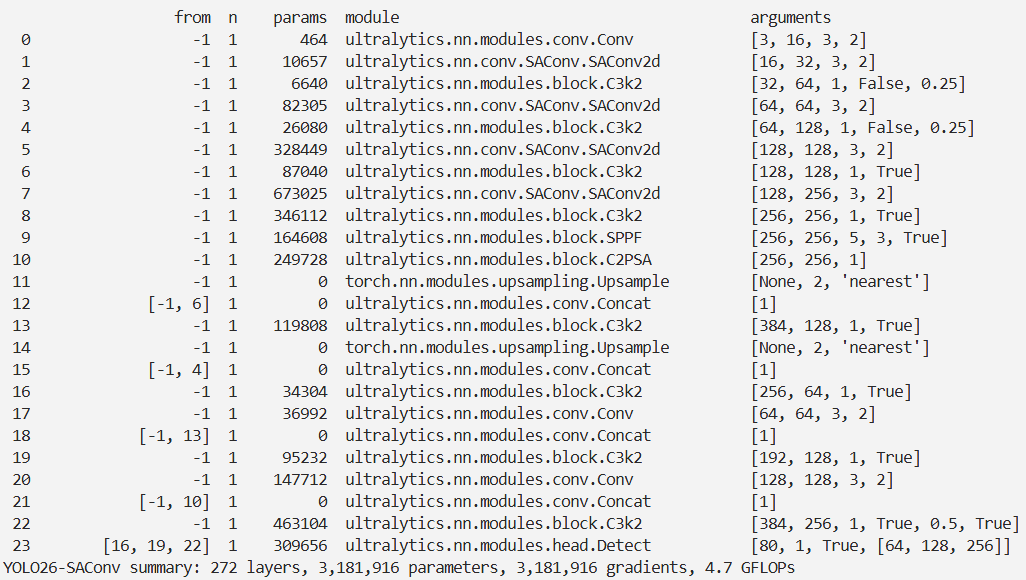
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-SAConv.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
# optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-SAConv',
)
结果