YOLO26改进 – 卷积Conv SCConv空间和通道重建卷积:轻量化设计助力复杂场景与小目标检测
# 前言
本文介绍了一种名为SCConv的高效卷积模块及其在YOLO26中的结合。传统CNN因卷积层提取冗余特征,计算资源消耗大。SCConv由空间重构单元(SRU)和通道重构单元(CRU)组成,是可直接替换标准卷积的即插即用架构单元。SRU采用“分离 - 重构”策略减少空间冗余,CRU运用“分割 - 转换 - 融合”策略减少通道冗余。我们将SCConv集成进YOLO26,实验表明该方法在降低模型复杂性和计算成本的同时,提升了性能。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
介绍

摘要
卷积神经网络(CNNs)在各种计算机视觉任务中取得了显著的性能,但这是以巨大的计算资源为代价的,部分原因是卷积层提取了冗余特征。近期的研究要么压缩训练有素的大规模模型,要么探索设计精良的轻量级模型。在本文中,我们尝试利用特征之间的空间和通道冗余性来进行CNN压缩,并提出了一种高效的卷积模块,称为SCConv(空间和通道重构卷积),以减少冗余计算并促进代表性特征学习。所提出的SCConv由两个单元组成:空间重构单元(SRU)和通道重构单元(CRU)。SRU使用分离-重构方法来抑制空间冗余,而CRU使用分割-变换-融合策略来减少通道冗余。此外,SCConv是一个即插即用的架构单元,可以直接用于替换各种卷积神经网络中的标准卷积。实验结果表明,嵌入SCConv的模型能够通过减少冗余特征,在显著降低复杂性和计算成本的同时,达到更好的性能。
创新点
-
空间重构单元(SRU)
-
通道重构单元(CRU)
如下图,SCConv 由两个单元组成,即空间重构单元 (SRU) 和信道重构单元 (CRU) ,两个单元按顺序排列。输入的特征 X 先经过 空间重构单元 ,得到空间细化的特征Xw 。再经过 通道重构单元 ,得到通道提炼的特征 Y 作为输出。SCConv 模块利用了特征之间的空间冗余和信道冗余,模块可以无缝集成到任何 CNN 框架中,减少特征之间的冗余,提高 CNN 特征的代表性。
文章链接
论文地址:论文地址
基本原理
本研究创新性地提出了一种新型卷积,其设计灵活可与任意卷积模型无缝集成,即插即用。文章分别从空间和通道两个维度提出了空间重构单元(SRU)和通道重构单元(CRU),有效减少了特征的冗余。最为关键的是,该方法在减少模型参数的同时,还显著提升了性能,实现了效率与效果的双赢。
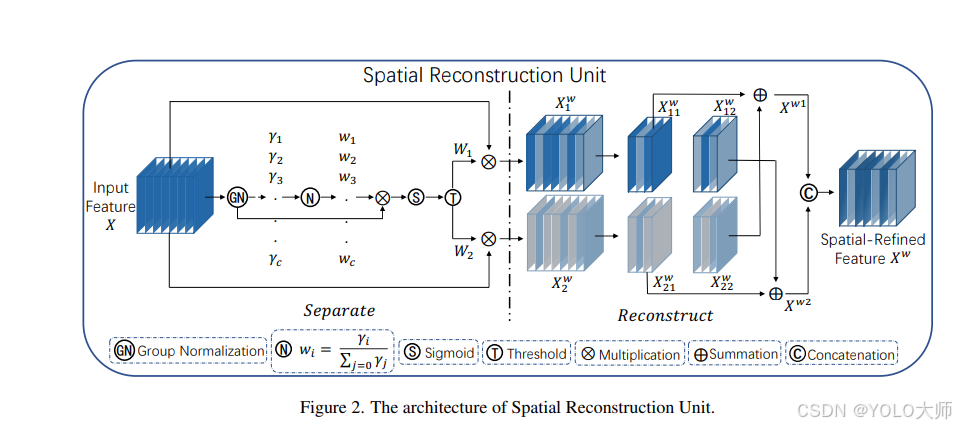
空间重构单元(SRU)
该单元运用“分离-重构”策略。其“分离”步骤旨在根据空间内容将富含信息的特征图与信息稀疏的特征图区分开来。为此,作者借助组归一化(Group Normalization)中的缩放因子来衡量不同特征图的信息量。而“重构”步骤则通过相加信息密集与信息稀疏的特征,以生成信息更丰富的特征同时优化空间利用。具体而言,采用交叉重建法融合两个加权不同信息特征,生成空间精细化特征图Xw,通过这一过程,既丰富了特征信息,又提高了空间效率。
分离操作
分离操作旨在从低信息量的特征图中提取出高信息量的特征图,这与空间内容的相关性密切相关。为了评估不同特征图中的信息含量,作者采用了组归一化(Group Normalization)中的缩放因子。
重构操作
重构操作通过将高信息量特征与低信息量特征相结合,以增加总信息量并优化空间利用效率。具体来说,该操作通过交叉重建的方式,将两个不同信息量的特征图进行加权合并,形成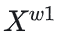 和
和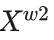 。这些特征图联合后得到空间细化的特征图
。这些特征图联合后得到空间细化的特征图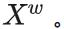 。
。
在这里,⊗表示元素乘法,⊕表示元素加法,而∪表示求并集操作。
通过SRU(Spatial Refinement Unit)处理,高信息量的特征从低信息量的特征中成功分离,从而减少了空间维度上的冗余特征。
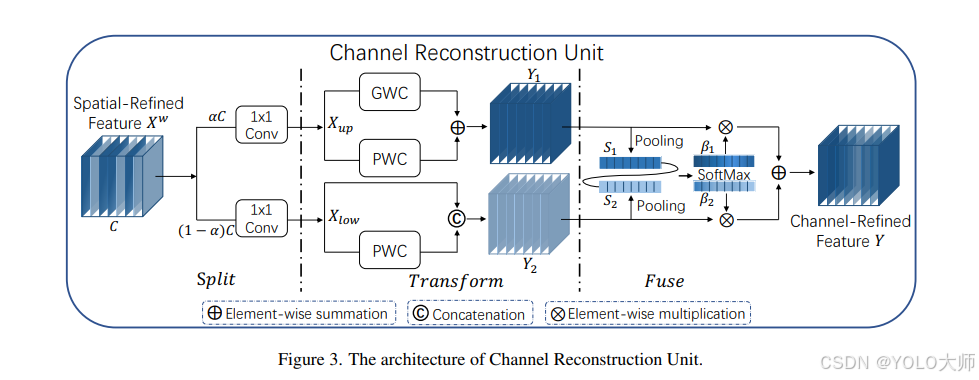
通道重构单元(CRU)
该单元运用分割-转换-融合策略
分割操作
输入的空间细化特征Xw被分割成两部分:
- 第一部分的通道数为
αC - 第二部分的通道数为
(1−α)C
其中,α是一个预设的超参数,满足0 ≤ α ≤ 1。接着,使用1×1卷积核对这两部分特征的通道数进行压缩,分别生成Xup和Xlow。
转换操作
Xup作为“富特征提取”的输入,经历以下过程:
- 经过组卷积(Group-Wise Convolution, GWC)
- 经过点卷积(Point-Wise Convolution, PWC)
- 这两种处理的结果相加,形成输出
Y1
Xlow作为“富特征提取”的补充,进行点卷积处理。其结果与原输入进行合并,得到Y2。
融合操作
采用简化版的SKNet方法自适应合并Y1和Y2。过程如下:
- 首先,应用全局平均池化技术,结合全局空间信息与通道统计信息,处理
S1和S2。 - 对
S1和S2执行Softmax操作,得到特征权重向量β1和β2。 - 最终输出
Y为β1Y1 + β2Y2,其中Y是经过通道提炼的特征。
核心代码
import torch
import torch.nn.functional as F
import torch.nn as nn
class GroupBatchnorm2d(nn.Module):
def __init__(self, c_num:int,
group_num:int = 16,
eps:float = 1e-10
):
super(GroupBatchnorm2d,self).__init__()
assert c_num >= group_num
self.group_num = group_num
self.gamma = nn.Parameter( torch.randn(c_num, 1, 1) )
self.beta = nn.Parameter( torch.zeros(c_num, 1, 1) )
self.eps = eps
def forward(self, x):
N, C, H, W = x.size()
x = x.view( N, self.group_num, -1 )
mean = x.mean( dim = 2, keepdim = True )
std = x.std ( dim = 2, keepdim = True )
x = (x - mean) / (std+self.eps)
x = x.view(N, C, H, W)
return x * self.gamma + self.beta
class SRU(nn.Module):
def __init__(self,
oup_channels:int,
group_num:int = 16,
gate_treshold:float = 0.5
):
super().__init__()
self.gn = GroupBatchnorm2d( oup_channels, group_num = group_num )
self.gate_treshold = gate_treshold
self.sigomid = nn.Sigmoid()
def forward(self,x):
gn_x = self.gn(x)
w_gamma = F.softmax(self.gn.gamma,dim=0)
reweigts = self.sigomid( gn_x * w_gamma )
# Gate
info_mask = w_gamma>self.gate_treshold
noninfo_mask= w_gamma<=self.gate_treshold
x_1 = info_mask*reweigts * x
x_2 = noninfo_mask*reweigts * x
x = self.reconstruct(x_1,x_2)
return x
def reconstruct(self,x_1,x_2):
x_11,x_12 = torch.split(x_1, x_1.size(1)//2, dim=1)
x_21,x_22 = torch.split(x_2, x_2.size(1)//2, dim=1)
return torch.cat([ x_11+x_22, x_12+x_21 ],dim=1)
class CRU(nn.Module):
'''
alpha: 0<alpha<1
'''
def __init__(self,
op_channel:int,
alpha:float = 1/2,
squeeze_radio:int = 2 ,
group_size:int = 2,
group_kernel_size:int = 3,
):
super().__init__()
self.up_channel = up_channel = int(alpha*op_channel)
self.low_channel = low_channel = op_channel-up_channel
self.squeeze1 = nn.Conv2d(up_channel,up_channel//squeeze_radio,kernel_size=1,bias=False)
self.squeeze2 = nn.Conv2d(low_channel,low_channel//squeeze_radio,kernel_size=1,bias=False)
#up
self.GWC = nn.Conv2d(up_channel//squeeze_radio, op_channel,kernel_size=group_kernel_size, stride=1,padding=group_kernel_size//2, groups = group_size)
self.PWC1 = nn.Conv2d(up_channel//squeeze_radio, op_channel,kernel_size=1, bias=False)
#low
self.PWC2 = nn.Conv2d(low_channel//squeeze_radio, op_channel-low_channel//squeeze_radio,kernel_size=1, bias=False)
self.advavg = nn.AdaptiveAvgPool2d(1)
def forward(self,x):
# Split
up,low = torch.split(x,[self.up_channel,self.low_channel],dim=1)
up,low = self.squeeze1(up),self.squeeze2(low)
# Transform
Y1 = self.GWC(up) + self.PWC1(up)
Y2 = torch.cat( [self.PWC2(low), low], dim= 1 )
# Fuse
out = torch.cat( [Y1,Y2], dim= 1 )
out = F.softmax( self.advavg(out), dim=1 ) * out
out1,out2 = torch.split(out,out.size(1)//2,dim=1)
return out1+out2
class ScConv(nn.Module):
def __init__(self,
op_channel:int,
group_num:int = 16,
gate_treshold:float = 0.5,
alpha:float = 1/2,
squeeze_radio:int = 2 ,
group_size:int = 2,
group_kernel_size:int = 3,
):
super().__init__()
self.SRU = SRU( op_channel,
group_num = group_num,
gate_treshold = gate_treshold )
self.CRU = CRU( op_channel,
alpha = alpha,
squeeze_radio = squeeze_radio ,
group_size = group_size ,
group_kernel_size = group_kernel_size )
def forward(self,x):
x = self.SRU(x)
x = self.CRU(x)
return x
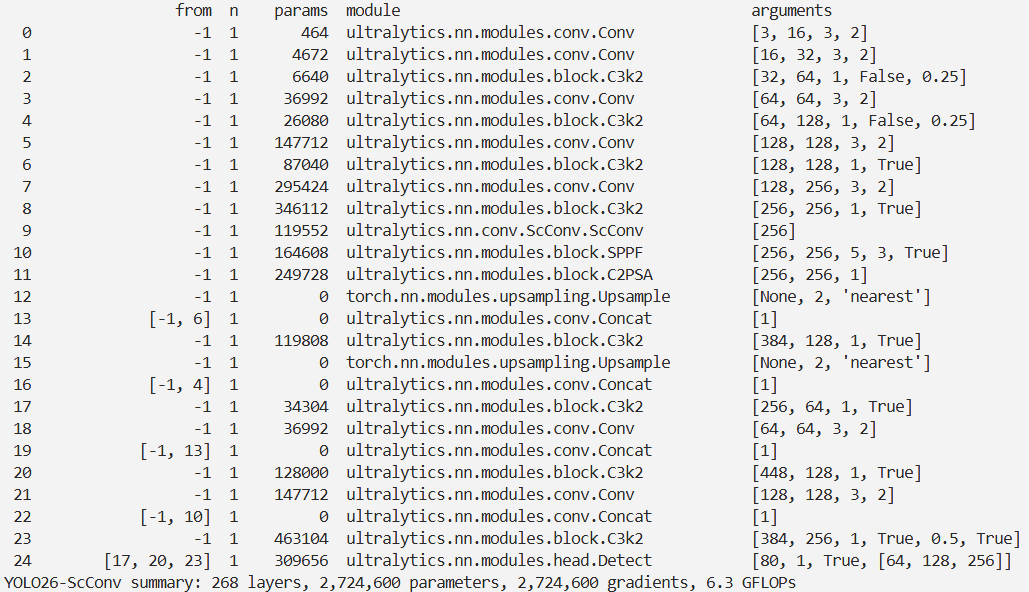
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-ScConv.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
# optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-ScConv',
)
结果