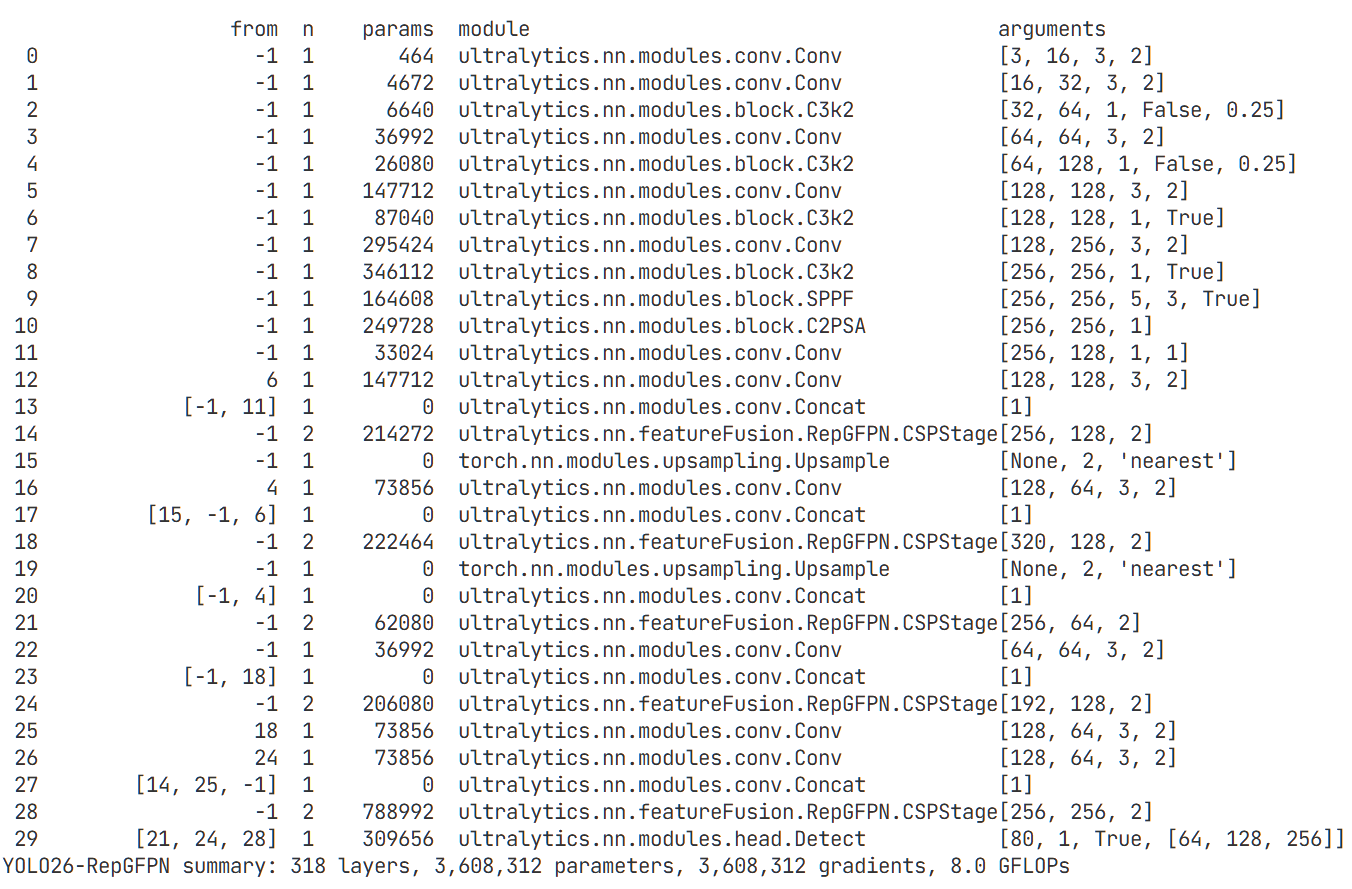
YOLO26改进 – 特征融合 RepGFPN重参数化特征金字塔网络 ,实现高效多尺度特征交互与融合
前言
本文介绍了DAMO - YOLO目标检测方法及其相关技术在YOLO26中的结合。DAMO - YOLO扩展了多项新技术,如MAE - NAS搜索检测主干网络、Efficient - RepGFPN构建检测neck等。在neck设计上,针对原始GFPN存在的问题,提出Efficient - RepGFPN,包括对不同尺度特征使用不同通道数、删除Queen - Fusion中额外上采样操作、改进特征融合方式等。我们将相关模块集成进YOLO26,替换部分模块。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
介绍

摘要
本文呈现了一种卓越的目标检测方法——DAMO-YOLO,该方法通过融合多项创新技术,在保持高效推理速度的同时显著超越了现有YOLO系列的性能水准。DAMO-YOLO基于经典YOLO架构,巧妙整合了多项前沿技术突破,包括遵循最大熵原则的神经架构搜索(MAE-NAS)、高效的重参数化通用特征金字塔网络(RepGFPN)、配合AlignedOTA标签分配策略的轻量化检测头以及精心设计的知识蒸馏增强机制。
在主干网络构建中,我们采用MAE-NAS方法在低延迟与高性能的双重约束下进行精确搜索,成功构建了兼具ResNet与CSP特性的卓越结构,并融合空间金字塔池化与注意力聚焦模块。在网络架构设计上,我们秉持"大neck,小head"的创新理念,引入加速queen-fusion的通用特征金字塔网络作为检测neck,并通过高效层聚合网络(ELAN)与重参数化技术实现了对CSPNet的全面升级。深入研究发现,配备单一任务投影层的强化neck结构能够获得更为理想的检测效果。此外,我们提出的AlignedOTA算法有效解决了标签分配过程中的错位问题,配合精心调校的蒸馏方案进一步提升了模型整体性能。
基于这些技术创新,我们精心打造了满足不同应用场景的系列模型。针对工业级应用需求,我们推出DAMO-YOLO-T/S/M/L系列,这些模型在T4 GPU上的推理延迟分别为2.78/3.83/5.62/7.95毫秒,同时在COCO基准测试上实现了43.6/47.7/50.2/51.9的平均精度(mAP)。针对边缘计算场景,我们设计的DAMO-YOLO-Ns/Nm/Nl轻量级模型在X86-CPU环境下推理延迟仅为4.08/5.05/6.69毫秒,同时保持32.3/38.2/40.5的卓越mAP性能。实验结果表明,我们的DAMO-YOLO系列模型在各自适用场景中均显著优于现有YOLO系列产品。完整源代码已在GitHub开源平台(https://github.com/tinyvision/damo-yolo)公开发布。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理:Large Neck: RepGFPN
在FPN(特征金字塔网络)中,多尺度特征融合旨在聚合不同阶段backbone输出的特征,从而增强输出特征的表达能力,提高模型性能。传统的 FPN 引入自上而下的路径来合并多尺度特征。考虑到单向流量的限制,PAFPN增加了一个额外的自下而上的路径聚合网络,但增加了计算成本。为了降低计算强度,YOLO系列检测网络选择PAFPN和CSPNet来融合主干输出的多尺度特征。
他们在ICLR2022中的工作GiraffeDet提出了一种新颖的Light-Backbone Heavy-Neck结构并实现了SOTA性能,因为给定的颈结构GFPN(广义FPN)可以充分交换高层语义信息和低层空间信息。在GFPN中,多尺度特征融合发生在前一层和当前层的不同尺度特征中,此外,跨层连接log_2(n)提供了更有效的信息传输,可以扩展到更深的网络。
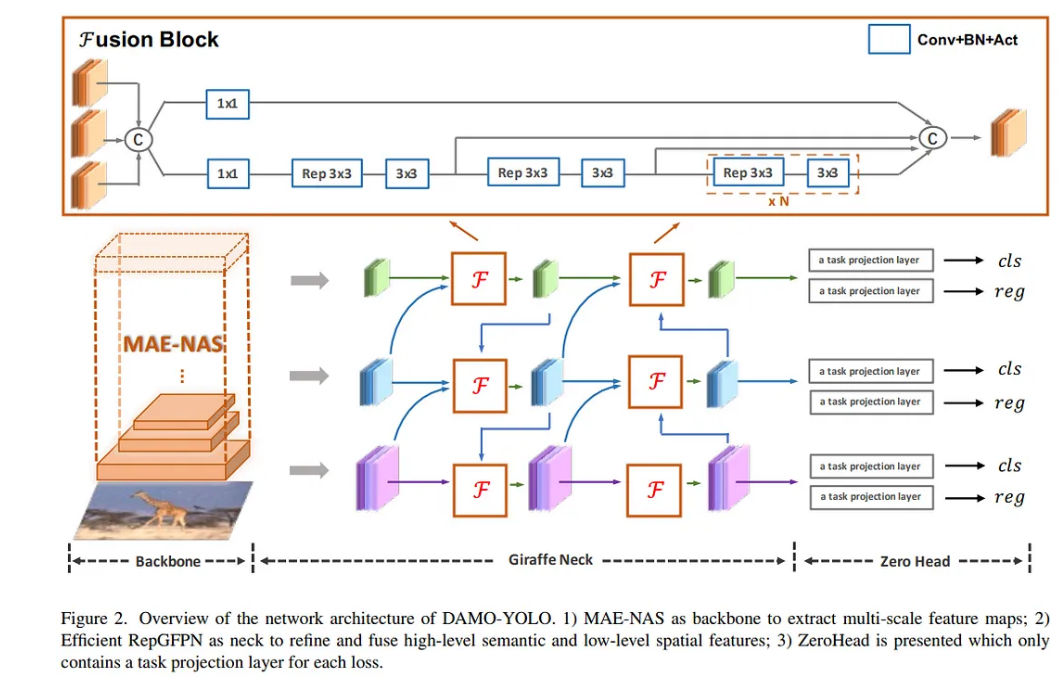
因此,他们尝试将GFPN引入DAMO-YOLO中,并且获得了比PANet更高的准确率,这是预期的。但与此同时,GFPN带来了模型推理延迟的增加,使得精度/延迟的权衡并没有取得很大的优势。通过对原始GFPN结构的分析,他们将原因归结为以下几个方面:
(1)不同尺度的特征共享相同数量的通道,这使得很难给出一个最优的通道数来保证高层低层的特征。 - 分辨率特征和低级高分辨率特征具有同样丰富的表达能力;
(2)GFPN使用Queen-Fusion来增强特征之间的融合,而Queen-Fusion包含大量的上采样和下采样操作来实现不同尺度下特征的融合,这极大地影响了推理速度;
(3)GFPN中使用的3x3卷积的跨尺度特征融合效率不高,无法满足轻量级计算的需求,需要进一步优化。
经过上述分析,他们在GFPN的基础上提出了一种新的Efficient-RepGFPN,以满足实时物体检测中颈部的设计,主要包括以下改进:(1)对不同尺度的特征使用不同的通道数,从而在轻量级计算的约束下灵活控制高层特征和低层特征的表达能力; (2)删除了Queen-Fusion中额外的上采样操作,大大降低了精度下降较小时的模型推理延迟; (3)将原来基于卷积的特征融合改进为CSPNet连接,并引入重参数化和ELAN连接的思想,在不增加更多计算量的情况下提高模型的精度。最终的Efficient-RepGFPN网络结构如上图2所示。 Efficient-RepNGFPN 的消融测定如下表 2 所示。
从表2可以看出,灵活控制不同尺度特征图的通道数可以比共享相同通道数的所有尺度特征图获得更高的精度,表明灵活控制高层特征的表达能力和低级功能可以带来更多好处。同时,通过控制模型在相同计算级别,他们还在Efficient-RepGFPN中做了深度/宽度权衡比较,当深度=3、宽度=(96,192,384)时,模型达到了最高的精度。
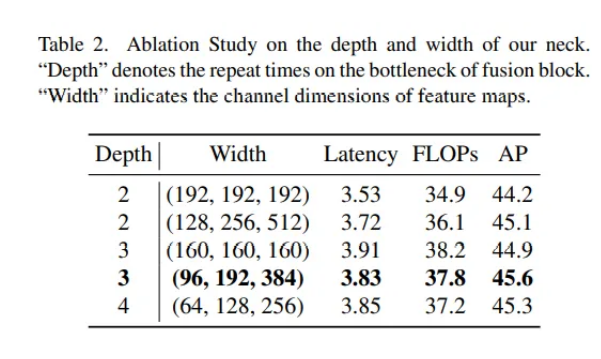
表3为Queen-Fusion连接的Ablation实验对比,颈部结构为PANet连接,没有添加额外的上采样和下采样算子。他们尝试只添加上采样算子和下采样算子以及完整的Queen-Fusion结构,模型精度得到了提高。然而,仅添加上采样算子带来了0.6ms的推理时间增加,并且精度仅提高了0.3,远低于仅添加额外下采样算子的精度/延迟增益,因此他们在最终放弃了额外的上采样算子设计。
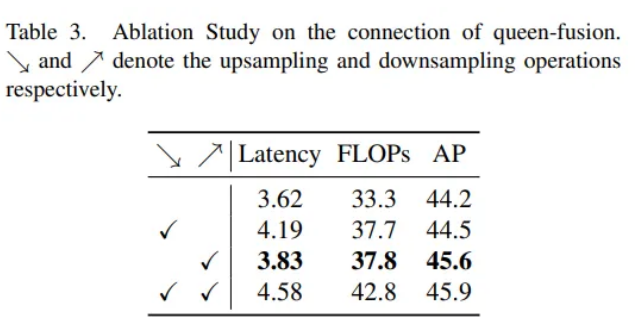
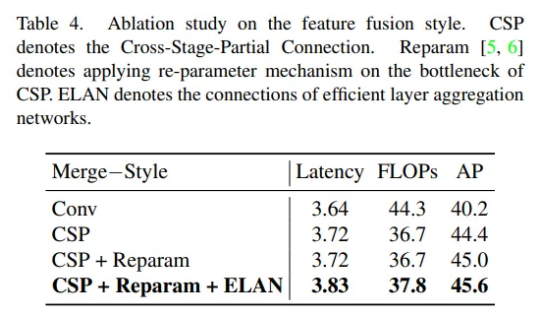
表4中,他们对多尺度特征融合方法进行了实验比较,从表中可以看出,在低计算约束下,CSPNet的特征融合方法比基于卷积的融合方法要好得多,并且在同时,重参数化思维和ELAN连接的引入可以在延迟小幅增加的情况下带来较大的精度提升。
核心代码
# Copyright (C) Alibaba Group Holding Limited. All rights reserved.
import numpy as np
import torch
import math
import torch.nn as nn
import torch.nn.functional as F
from .weight_init import kaiming_init, constant_init
from damo.utils import make_divisible
class SiLU(nn.Module):
"""export-friendly version of nn.SiLU()"""
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
class Swish(nn.Module):
def __init__(self, inplace=True):
super(Swish, self).__init__()
self.inplace = inplace
def forward(self, x):
if self.inplace:
x.mul_(F.sigmoid(x))
return x
else:
return x * F.sigmoid(x)
def get_activation(name='silu', inplace=True):
if name is None:
return nn.Identity()
if isinstance(name, str):
if name == 'silu':
module = nn.SiLU(inplace=inplace)
elif name == 'relu':
module = nn.ReLU(inplace=inplace)
elif name == 'lrelu':
module = nn.LeakyReLU(0.1, inplace=inplace)
elif name == 'swish':
module = Swish(inplace=inplace)
elif name == 'hardsigmoid':
module = nn.Hardsigmoid(inplace=inplace)
elif name == 'identity':
module = nn.Identity()
else:
raise AttributeError('Unsupported act type: {}'.format(name))
return module
elif isinstance(name, nn.Module):
return name
else:
raise AttributeError('Unsupported act type: {}'.format(name))
def get_norm(name, out_channels):
if name == 'bn':
module = nn.BatchNorm2d(out_channels)
elif name == 'gn':
module = nn.GroupNorm(out_channels)
else:
raise NotImplementedError
return module
class ConvBNAct(nn.Module):
"""A Conv2d -> Batchnorm -> silu/leaky relu block"""
def __init__(
self,
in_channels,
out_channels,
ksize,
stride=1,
groups=1,
bias=False,
act='silu',
norm='bn',
reparam=False,
):
super().__init__()
# same padding
pad = (ksize - 1) // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=ksize,
stride=stride,
padding=pad,
groups=groups,
bias=bias,
)
if norm is not None:
self.bn = get_norm(norm, out_channels)
if act is not None:
self.act = get_activation(act, inplace=True)
self.with_norm = norm is not None
self.with_act = act is not None
def forward(self, x):
x = self.conv(x)
if self.with_norm:
x = self.bn(x)
if self.with_act:
x = self.act(x)
return x
def fuseforward(self, x):
return self.act(self.conv(x))
class SPPBottleneck(nn.Module):
"""Spatial pyramid pooling layer used in YOLOv3-SPP"""
def __init__(self,
in_channels,
out_channels,
kernel_sizes=(5, 9, 13),
activation='silu'):
super().__init__()
hidden_channels = in_channels // 2
self.conv1 = ConvBNAct(in_channels,
hidden_channels,
1,
stride=1,
act=activation)
self.m = nn.ModuleList([
nn.MaxPool2d(kernel_size=ks, stride=1, padding=ks // 2)
for ks in kernel_sizes
])
conv2_channels = hidden_channels * (len(kernel_sizes) + 1)
self.conv2 = ConvBNAct(conv2_channels,
out_channels,
1,
stride=1,
act=activation)
def forward(self, x):
x = self.conv1(x)
x = torch.cat([x] + [m(x) for m in self.m], dim=1)
x = self.conv2(x)
return x
def depthwise_conv(i, o, kernel_size, stride=1, padding=0, bias=False):
return nn.Conv2d(i, o, kernel_size, stride, padding, bias=bias, groups=i)
class Focus(nn.Module):
"""Focus width and height information into channel space."""
def __init__(self,
in_channels,
out_channels,
ksize=1,
stride=1,
act='silu'):
super().__init__()
self.conv = ConvBNAct(in_channels * 4,
out_channels,
ksize,
stride,
act=act)
def forward(self, x):
# shape of x (b,c,w,h) -> y(b,4c,w/2,h/2)
patch_top_left = x[..., ::2, ::2]
patch_top_right = x[..., ::2, 1::2]
patch_bot_left = x[..., 1::2, ::2]
patch_bot_right = x[..., 1::2, 1::2]
x = torch.cat(
(
patch_top_left,
patch_bot_left,
patch_top_right,
patch_bot_right,
),
dim=1,
)
return self.conv(x)
class Hsigmoid(nn.Module):
def __init__(self, inplace=True):
super(Hsigmoid, self).__init__()
self.inplace = inplace
def forward(self, x):
return F.relu6(x + 3., inplace=self.inplace) / 6.
class SEModule(nn.Module):
def __init__(self, channel, reduction=4):
super(SEModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
Hsigmoid()
# nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
class MobileV3Block(nn.Module):
def __init__(self,
in_c,
out_c,
btn_c,
kernel_size,
stride,
act='silu',
reparam=False,
block_type='k1kx',
depthwise=False,):
super(MobileV3Block, self).__init__()
self.stride = stride
self.exp_ratio = 3.0
branch_features = math.ceil(out_c * self.exp_ratio)
branch_features = make_divisible(branch_features)
#assert (self.stride != 1) or (in_c == branch_features << 1)
self.conv = nn.Sequential(
nn.Conv2d(
in_c,
branch_features,
kernel_size=1,
stride=1,
padding=0,
bias=False,
),
nn.BatchNorm2d(branch_features),
get_activation(act),
depthwise_conv(
branch_features,
branch_features,
kernel_size=5,
stride=self.stride,
padding=2,
),
nn.BatchNorm2d(branch_features),
get_activation(act),
nn.Conv2d(
branch_features,
out_c,
kernel_size=1,
stride=1,
padding=0,
bias=False,
),
nn.BatchNorm2d(out_c),
)
self.use_shotcut = self.stride == 1 and in_c == out_c
def forward(self, x):
if self.use_shotcut:
return x + self.conv(x)
else:
return self.conv(x)
class BasicBlock_3x3_Reverse(nn.Module):
def __init__(self,
ch_in,
ch_hidden_ratio,
ch_out,
act='relu',
shortcut=True,
depthwise=False):
super(BasicBlock_3x3_Reverse, self).__init__()
assert ch_in == ch_out
ch_hidden = int(ch_in * ch_hidden_ratio)
if not depthwise:
self.conv1 = ConvBNAct(ch_hidden, ch_out, 3, stride=1, act=act)
self.conv2 = RepConv(ch_in, ch_hidden, 3, stride=1, act=act)
else:
self.conv = MobileV3Block(in_c=ch_in, out_c=ch_out, btn_c=None,
kernel_size=5, stride=1, act=act)
self.shortcut = shortcut
self.depthwise = depthwise
def forward(self, x):
if not self.depthwise:
y = self.conv2(x)
y = self.conv1(y)
if self.shortcut:
return x + y
else:
return y
else:
return self.conv(x)
class DepthwiseConv(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
bias="auto",
norm_cfg="bn",
act="ReLU",
inplace=True,
order=("depthwise", "dwnorm", "act", "pointwise", "pwnorm", "act"),
):
super(DepthwiseConv, self).__init__()
assert act is None or isinstance(act, str)
self.act = act
self.inplace = inplace
self.order = order
padding = (kernel_size - 1) //2
self.with_norm = norm_cfg is not None
# if the conv layer is before a norm layer, bias is unnecessary.
if bias == "auto":
bias = False if self.with_norm else True
self.with_bias = bias
# build convolution layer
self.depthwise = nn.Conv2d(
in_channels,
in_channels,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=in_channels,
bias=bias,
)
self.pointwise = nn.Conv2d(
in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=bias
)
# export the attributes of self.conv to a higher level for convenience
self.in_channels = self.depthwise.in_channels
self.out_channels = self.pointwise.out_channels
self.kernel_size = self.depthwise.kernel_size
self.stride = self.depthwise.stride
self.padding = self.depthwise.padding
self.dilation = self.depthwise.dilation
self.transposed = self.depthwise.transposed
self.output_padding = self.depthwise.output_padding
# build normalization layers
if self.with_norm:
# norm layer is after conv layer
if 'dwnorm' in self.order:
self.dwnorm = get_norm(norm_cfg, in_channels)
if 'pwnorm' in self.order:
self.pwnorm = get_norm(norm_cfg, out_channels)
# build activation layer
if self.act:
self.act = get_activation(self.act)
# Use msra init by default
self.init_weights()
def init_weights(self):
if self.act == "lrelu":
nonlinearity = "leaky_relu"
else:
nonlinearity = "relu"
kaiming_init(self.depthwise, nonlinearity=nonlinearity)
kaiming_init(self.pointwise, nonlinearity=nonlinearity)
if self.with_norm:
if 'dwnorm' in self.order:
constant_init(self.dwnorm, 1, bias=0)
if 'pwnorm' in self.order:
constant_init(self.pwnorm, 1, bias=0)
def forward(self, x):
for layer_name in self.order:
if layer_name != "act":
layer = self.__getattr__(layer_name)
x = layer(x)
elif layer_name == "act" and self.act:
x = self.act(x)
return x
class SPP(nn.Module):
def __init__(
self,
ch_in,
ch_out,
k,
pool_size,
act='swish',
):
super(SPP, self).__init__()
self.pool = []
for i, size in enumerate(pool_size):
pool = nn.MaxPool2d(kernel_size=size,
stride=1,
padding=size // 2,
ceil_mode=False)
self.add_module('pool{}'.format(i), pool)
self.pool.append(pool)
self.conv = ConvBNAct(ch_in, ch_out, k, act=act)
def forward(self, x):
outs = [x]
for pool in self.pool:
outs.append(pool(x))
y = torch.cat(outs, axis=1)
y = self.conv(y)
return y
class CSPStage(nn.Module):
def __init__(self,
block_fn,
ch_in,
ch_hidden_ratio,
ch_out,
n,
act='swish',
spp=False,
depthwise=False):
super(CSPStage, self).__init__()
split_ratio = 2
ch_first = int(ch_out // split_ratio)
ch_mid = int(ch_out - ch_first)
self.conv1 = ConvBNAct(ch_in, ch_first, 1, act=act)
self.conv2 = ConvBNAct(ch_in, ch_mid, 1, act=act)
self.convs = nn.Sequential()
next_ch_in = ch_mid
for i in range(n):
if block_fn == 'BasicBlock_3x3_Reverse':
self.convs.add_module(
str(i),
BasicBlock_3x3_Reverse(next_ch_in,
ch_hidden_ratio,
ch_mid,
act=act,
shortcut=True,
depthwise=depthwise))
else:
raise NotImplementedError
if i == (n - 1) // 2 and spp:
self.convs.add_module(
'spp', SPP(ch_mid * 4, ch_mid, 1, [5, 9, 13], act=act))
next_ch_in = ch_mid
self.conv3 = ConvBNAct(ch_mid * n + ch_first, ch_out, 1, act=act)
def forward(self, x):
y1 = self.conv1(x)
y2 = self.conv2(x)
mid_out = [y1]
for conv in self.convs:
y2 = conv(y2)
mid_out.append(y2)
y = torch.cat(mid_out, axis=1)
y = self.conv3(y)
return y
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
'''Basic cell for rep-style block, including conv and bn'''
result = nn.Sequential()
result.add_module(
'conv',
nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class RepConv(nn.Module):
'''RepConv is a basic rep-style block, including training and deploy status
Code is based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
'''
def __init__(self,
in_channels,
out_channels,
kernel_size=3,
stride=1,
padding=1,
dilation=1,
groups=1,
padding_mode='zeros',
deploy=False,
act='relu',
norm=None):
super(RepConv, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
self.out_channels = out_channels
assert kernel_size == 3
assert padding == 1
padding_11 = padding - kernel_size // 2
if isinstance(act, str):
self.nonlinearity = get_activation(act)
else:
self.nonlinearity = act
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=True,
padding_mode=padding_mode)
else:
self.rbr_identity = None
self.rbr_dense = conv_bn(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels,
out_channels=out_channels,
kernel_size=1,
stride=stride,
padding=padding_11,
groups=groups)
def forward(self, inputs):
'''Forward process'''
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.rbr_reparam(inputs))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(
self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(
kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3),
dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(
branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(
in_channels=self.rbr_dense.conv.in_channels,
out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size,
stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding,
dilation=self.rbr_dense.conv.dilation,
groups=self.rbr_dense.conv.groups,
bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-RepGFPN.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False,
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
amp=True,
project='runs/train',
name='RepGFPN',
)
结果