YOLO26改进 – 卷积Conv PConv(Pinwheel-shaped Conv) 风车状卷积用于红外小目标检测 AAAI 2025
# 前言 本文介绍了风车状卷积(PConv)和基于尺度的动态(SD)损失在YOLO26中的结合应用。PConv采用不对称填充,通过特殊结构设计、卷积运算和分组卷积技术,能更好地适应红外小目标的像素高斯空间分布,在少量增加参数的情况下极大扩展感受野。SD损失可根据目标大小动态调整尺度和位置损失的影响。我们将PConv集成到YOLO26的主干网络低层,并在相关配置文件中进行设置。实验证明,YOLO26 - PConv在IRSTD - 1K和SIRST - UAVB数据集上取得显著性能提升,验证了方法的有效性和泛化能力。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
介绍

摘要
近年来,基于卷积神经网络(CNN)的方法在红外小目标检测领域展现出卓越性能。不过,这些方法大多采用标准卷积,未充分考量红外小目标像素分布的空间特征。鉴于此,我们提出一种新型的风车形卷积(PConv),用以替代主干网络低层的标准卷积。PConv能够更好地契合微弱小目标像素的高斯空间分布,在增强特征提取效果、显著增大感受野的同时,仅引入极少量的额外参数。此外,尽管近期的损失函数已将尺度和位置损失相结合,但未能充分考虑不同目标尺度下这些损失的敏感度差异,进而限制了对微弱小目标的检测性能。为解决该问题,我们提出基于尺度的动态(SD)损失,其可依据目标大小动态调整尺度和位置损失的影响,从而提升网络对不同尺度目标的检测能力。我们构建了新的基准数据集SIRST - UAVB,这是目前最大且最具挑战性的实景单帧红外小目标检测数据集。最后,将PConv和SD损失集成到最新的小目标检测算法中,我们在IRSTD - 1K和SIRST - UAVB数据集上均取得显著的性能提升,验证了所提方法的有效性与泛化能力。
文章链接
论文地址:论文地址
代码地址:官方代码地址
基本原理
Pinwheel - shaped Convolution(风车状卷积,简称PConv)是专门为红外小目标检测设计的一种新型卷积模块,其技术原理涵盖结构设计、卷积运算、特征融合以及优势体现等方面:
- 结构设计:PConv模块采用不对称填充方式,为图像不同区域构建水平和垂直方向的卷积核。在卷积过程中,这些卷积核呈向外扩散状态。以输入张量$X^{(h{1}, w{1}, c{1})}$为例,其中$h{1}$、$w{1}$、$c{1}$分别表示该张量的高度、宽度和通道大小。通过这种特殊的填充设计,PConv能够更好地适配红外小目标的像素高斯空间分布特征。
- 卷积运算过程
- 第一层并行卷积:PConv的第一层会开展4组并行卷积操作。例如,$X{1}^{(h', w', c')}=SiLU(BN(X{P(1,0,0,3)}^{(h{1}, w{1}, c{1})} \otimes W{1}^{(1,3, c')}))$ ,其中$\otimes$为卷积运算符,$W{1}^{(1,3, c')}$是一个1×3的卷积核,输出通道数为$c'$,$P(1,0,0,3)$为填充参数,代表在左、右、上、下方向的填充像素数量。$X{2}^{(h', w', c')}$、$X{3}^{(h', w', c')}$、$X{4}^{(h', w', c')}$的计算方式与之类似,仅填充参数和卷积核存在差异。经过第一层卷积后,输出特征图的高度$h'=\frac{h{1}}{s}+1$,宽度$w'=\frac{w{1}}{s}+1$,通道数$c'=\frac{c{2}}{4}$,此处$c{2}$是PConv模块最终输出特征图的通道数,$s$为卷积步长。
- 特征图拼接:将第一层并行卷积得到的4个结果$X{1}^{(h', w', c')}$、$X{2}^{(h', w', c')}$、$X{3}^{(h', w', c')}$、$X{4}^{(h', w', c')}$进行拼接,即$X^{(h', w', 4 c')}=Cat(X{1}^{(h', w', c')}, \cdots, X{4}^{(h', w', c')})$ ,从而得到一个通道数为$4c'$的张量。
- 最终输出计算:使用一个大小为$2×2$、通道数为$c{2}$的卷积核对拼接后的张量进行无填充卷积操作。最终输出特征图的高度$h{2}=h' - 1=\frac{h{1}}{s}$,宽度$w{2}=w' - 1=\frac{w{1}}{s}$ ,计算公式为$Y^{(h{2}, w{2}, c{2})}=SiLU(BN(X^{(h', w', 4 c')} \otimes W^{(2,2, c_{2})}))$。这种设计使得PConv模块在输出特征图时,能够将高度和宽度调整至预设值,并且可与普通卷积层进行互换。
- 感受野与参数优化:PConv模块运用分组卷积技术,在扩大感受野的同时,有效控制了参数数量的增长。以$3×3$的普通卷积与PConv(3,3)进行对比,当普通卷积的输出通道数$c{2}$等于输入通道数$c{1}$时,普通卷积的参数数量为$9c{1}^{2}$ ,而PConv(3,3)的参数数量为$7c{1}^{2}$,相比之下,PConv(3,3)的参数减少了22.2% ,但感受野却增加了177%。在实际应用场景(如YOLO系列网络)中,当$c{2}=4c{1}$时,普通卷积需要$36c{1}^{2}$个参数,PConv(3,3)需要$72c{1}^{2}$个参数,此时PConv(3,3)的感受野增加了178% ,参数仅增加111% 。同样,PConv(4,4)相较于普通卷积,感受野增加444%,参数仅增加122% 。这表明PConv能够在少量增加参数的情况下,大幅扩展感受野,高效提升对红外小目标底层特征的提取能力。
- 对红外小目标检测的优势:由于红外小目标在图像中的像素分布呈现高斯特性,PConv模块特殊的结构和运算方式能够更好地与之契合。通过实验对比PConv与普通卷积的输出结果可知,PConv可以增强红外小目标与背景之间的对比度,同时有效抑制杂波信号,进而更精准地提取红外小目标的特征,为后续的检测任务提供有力支撑。
核心代码
import torch
import torch.nn as nn
import torch.nn.functional as F
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class PConv(nn.Module):
''' Pinwheel-shaped Convolution using the Asymmetric Padding method. '''
def __init__(self, c1, c2, k, s):
super().__init__()
# self.k = k
p = [(k, 0, 1, 0), (0, k, 0, 1), (0, 1, k, 0), (1, 0, 0, k)]
self.pad = [nn.ZeroPad2d(padding=(p[g])) for g in range(4)]
self.cw = Conv(c1, c2 // 4, (1, k), s=s, p=0)
self.ch = Conv(c1, c2 // 4, (k, 1), s=s, p=0)
self.cat = Conv(c2, c2, 2, s=1, p=0)
def forward(self, x):
yw0 = self.cw(self.pad[0](x))
yw1 = self.cw(self.pad[1](x))
yh0 = self.ch(self.pad[2](x))
yh1 = self.ch(self.pad[3](x))
return self.cat(torch.cat([yw0, yw1, yh0, yh1], dim=1))
class APC2f(nn.Module):
"""Faster Implementation of APCSP Bottleneck with Asymmetric Padding convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, P=True, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
if P:
self.m = nn.ModuleList(APBottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
else:
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through APC2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
class APBottleneck(nn.Module):
"""Asymmetric Padding bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
p = [(2,0,2,0),(0,2,0,2),(0,2,2,0),(2,0,0,2)]
self.pad = [nn.ZeroPad2d(padding=(p[g])) for g in range(4)]
self.cv1 = Conv(c1, c_ // 4, k[0], 1, p=0)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2((torch.cat([self.cv1(self.pad[g](x)) for g in range(4)], 1))) if self.add else self.cv2((torch.cat([self.cv1(self.pad[g](x)) for g in range(4)], 1)))实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-PConv.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
amp=True,
project='runs/train',
name='yolo26-PConv',
)
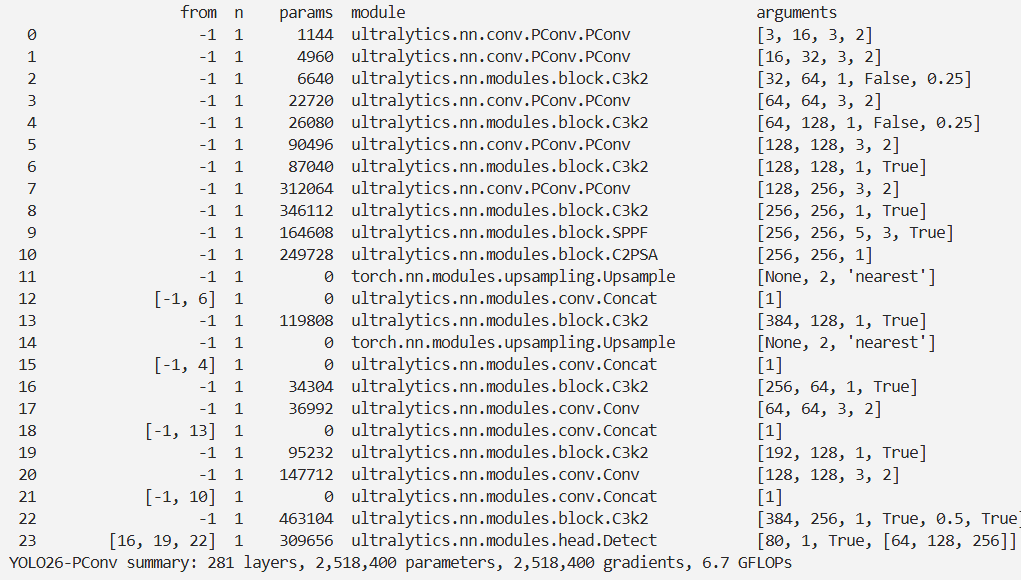
结果