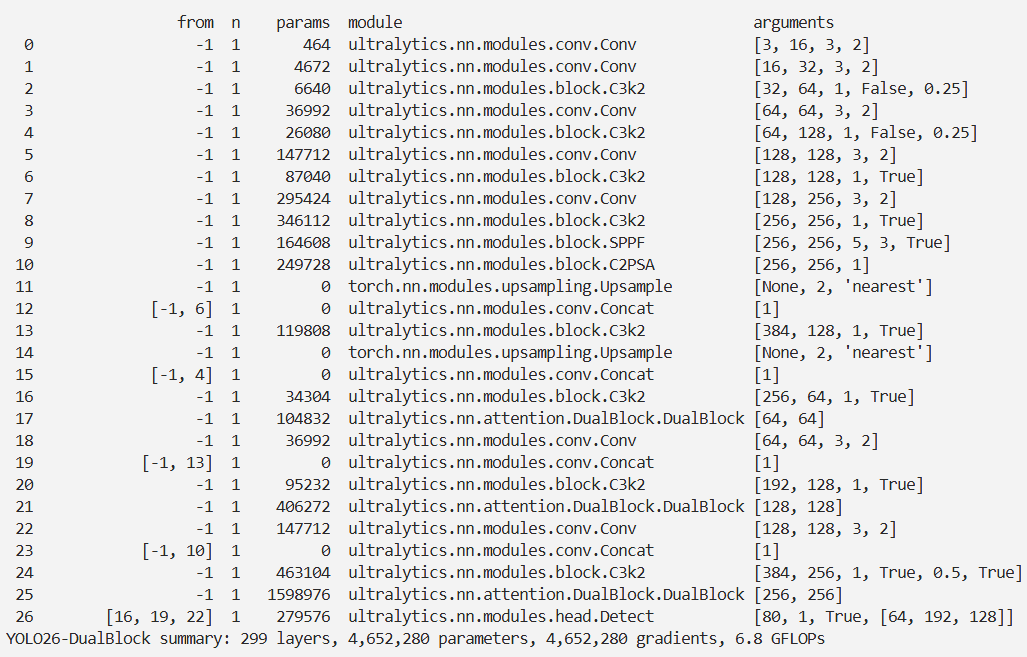
YOLO26改进 – 注意力机制 Dual-ViT 双视觉变换器:双路径建模协同全局语义与局部特征,增强多尺度感知
前言
本文介绍了双视觉Transformer(Dual-ViT)架构,并将其引入YOLO26以降低自注意力机制的计算成本。Dual-ViT包含语义和像素两个路径,语义路径将token向量压缩为全局语义,像素路径利用该语义学习像素级细节,二者并行传播增强自注意力信息,在不显著降低准确性的情况下减少计算复杂度。实验表明,Dual-ViT在ImageNet等数据集上表现优异。我们将Dual-ViT相关代码集成进YOLO26,经实验验证,改进后的YOLO26在目标检测任务中展现出良好性能。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
介绍

摘要
摘要——以往研究提出了多种策略以降低自注意力机制的计算开销,其中不少方法尝试将自注意力过程分解为区域级与局部特征提取过程,从而显著减少计算复杂度。然而,区域信息往往依赖下采样获得,这一过程中常常伴随着信息的不可逆损失。
为缓解这一问题,本文提出了一种新颖的Transformer架构,命名为双视觉Transformer(Dual-ViT)。该架构设计了两条关键路径:其中语义路径负责将token向量有效压缩为全局语义表示,从源头上降低计算负担;而像素路径则借助语义路径中提取的全局先验信息,聚焦于更细粒度的像素级特征学习。两条路径最终融合并联合训练,通过并行传播增强的自注意力信息,实现了全局与局部建模的协同优化。
得益于此架构,Dual-ViT在显著降低计算复杂度的同时,仍保持优异的性能表现。实验结果表明,Dual-ViT在多个任务中实现了优于现有主流Transformer架构的准确率,验证了其高效性与有效性。相关源代码已开源,详见:https://github.com/YehLi/ImageNetModel。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
双视觉Transformer(Dual-ViT)是一种新型的Transformer架构,旨在降低自注意力机制的计算成本,同时提高视觉任务的性能。以下是对Dual-ViT的详细介绍,包括其动机、结构、方法和实验结果。
1. 动机
Transformer架构在深度学习应用中取得了显著成功,尤其是在自然语言处理和计算机视觉领域。然而,由于Transformer依赖于密集的自注意力计算,处理高分辨率输入时训练速度较慢,成为了一个瓶颈。传统的自注意力机制需要对每个token进行全局关注,导致计算复杂度随token数量的平方增长。为了解决这一问题,许多研究尝试将自注意力过程分解为区域和局部特征提取,但这些方法往往会导致信息损失。
Dual-ViT的提出旨在通过引入全局语义和局部特征之间的依赖关系,来有效降低计算复杂度。其核心思想是通过两个路径(语义路径和像素路径)并行处理信息,从而在保持高精度的同时减少计算负担。
2. 结构
Dual-ViT的架构由两个主要路径组成:
-
语义路径:负责提取全局语义信息,通过压缩token向量来生成高级语义token。这些token作为先验信息,帮助后续的局部特征提取。
-
像素路径:专注于细粒度的局部特征提取,利用来自语义路径的全局信息来增强局部特征的学习。
这两个路径在训练过程中是联合进行的,允许信息在两者之间流动,从而有效补偿信息损失并提高特征提取的效率。
3. 方法
Dual-ViT的设计包括以下几个关键组件:
-
Dual块:在高分辨率输入的前两个阶段,Dual块结合了语义路径和像素路径。语义路径首先生成语义token,然后通过交叉注意力将这些token与输入特征结合,进行多头自注意力计算。这样可以显著降低计算复杂度,因为语义路径中的token数量远少于像素路径中的token。
-
合并块:在后两个阶段,合并块将来自两个路径的输出token合并,并在此基础上进行自注意力计算,以实现局部token之间的内部交互。
-
多尺度设计:Dual-ViT的完整架构由四个阶段组成,前两个阶段使用Dual块,后两个阶段使用合并块。该设计允许在不同分辨率下有效提取特征。
4. 实验结果
在ImageNet数据集上的实验表明,Dual-ViT在多个模型尺寸(如Dual-ViT-S、Dual-ViT-B、Dual-ViT-L)下均实现了优异的性能。例如,Dual-ViT在ImageNet上达到了85.7%的top-1精度,同时计算复杂度和参数数量显著低于其他最先进的Transformer架构。此外,在目标检测和实例分割任务中,Dual-ViT也表现出色,分别提高了PVT的mAP。
核心代码
class DualAttention(nn.Module):
def __init__(self, dim, num_heads, drop_path=0.0):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.q = nn.Linear(dim, dim)
self.kv = nn.Linear(dim, dim * 2)
self.proj = nn.Linear(dim, dim)
self.q_proxy = nn.Linear(dim, dim)
self.kv_proxy = nn.Linear(dim, dim * 2)
self.q_proxy_ln = nn.LayerNorm(dim)
self.p_ln = nn.LayerNorm(dim)
self.drop_path = DropPath(drop_path*1.0) if drop_path > 0. else nn.Identity()
self.mlp_proxy = nn.Sequential(
nn.Linear(dim, 4 * dim),
nn.ReLU(inplace=True),
nn.Linear(4 * dim, dim),
)
self.proxy_ln = nn.LayerNorm(dim)
self.qkv_proxy = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, dim*3)
)
layer_scale_init_value = 1e-6
self.gamma1 = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.gamma2 = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.gamma3 = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if m.weight is not None:
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def selfatt(self, semantics):
B, N, C = semantics.shape
qkv = self.qkv_proxy(semantics).reshape(B, -1, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
semantics = (attn @ v).transpose(1, 2).reshape(B, N, C)
return semantics
def forward(self, x, H, W, semantics):
semantics = semantics + self.drop_path(self.gamma1 * self.selfatt(semantics))
B, N, C = x.shape
B_p, N_p, C_p = semantics.shape
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
q_semantics = self.q_proxy(self.q_proxy_ln(semantics)).reshape(B_p, N_p, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
kv_semantics = self.kv_proxy(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
kp, vp = kv_semantics[0], kv_semantics[1]
attn = (q_semantics @ kp.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
_semantics = (attn @ vp).transpose(1, 2).reshape(B, N_p, C) * self.gamma2
semantics = semantics + self.drop_path(_semantics)
semantics = semantics + self.drop_path(self.gamma3 * self.mlp_proxy(self.p_ln(semantics)))
kv = self.kv(self.proxy_ln(semantics)).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
return x, semantics实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-DualBlock.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
# optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-DualBlock',
)
结果