YOLO26 改进 – 注意力机制 二阶通道注意力SOCA 通过协方差建模与自适应重缩放实现判别性特征增强
前言
本文介绍了二阶通道注意力(SOCA)模块在YOLO26中的结合应用。SOCA模块引入二阶统计信息,通过计算特征图通道协方差捕捉通道间相关性,实现步骤包括特征提取、计算均值和协方差、生成注意力权重、特征重标定,可增强特征表达与判别能力。我们将SOCA模块集成到YOLO26的骨干网络和检测头中,并进行相关注册和配置。实验表明,改进后的网络在量化指标和视觉质量上优于当前先进的单图像超分辨率方法。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
介绍

摘要
近期,深度卷积神经网络(CNNs)在单图像超分辨率(SISR)领域得到了广泛研究,并取得了显著的性能提升。然而,大多数现有的基于 CNN 的 SISR 方法主要侧重于构建更宽或更深的网络结构,却忽略了对中间层特征相关性的探究,进而限制了 CNNs 的表征能力。为解决该问题,本文提出了一种二阶注意力网络(SAN),旨在增强特征表达和特征相关性学习的能力。具体来说,我们研发了一种新颖的可训练二阶通道注意力(SOCA)模块,该模块通过利用二阶特征统计信息自适应地重新调整通道特征,以实现更具区分性的表示。此外,我们提出了一种非局部增强残差组(NLRG)结构,该结构不仅结合了非局部操作以捕捉远距离空间上下文信息,还包含了重复的局部源残差注意力组(LSRAG),用于逐步学习更抽象的特征表示。实验结果显示,在量化指标和视觉质量方面,我们的 SAN 网络优于当前最先进的 SISR 方法。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
二阶通道注意力(SOCA)模块主要围绕如何利用特征的二阶统计信息来增强特征表示和学习特征间的相关性。
1. 特征统计信息的概念
在深度学习中,特征图是通过卷积层提取的图像特征。传统的通道注意力机制(如SENet)通常依赖于第一阶统计信息,例如通过全局平均池化获得的通道特征均值。这种方法虽然有效,但仅考虑了每个通道的独立性,忽略了通道之间的相互关系。
2. 二阶统计信息的引入
SOCA模块通过引入二阶统计信息(如协方差矩阵)来捕捉通道之间的相关性。具体来说,SOCA模块计算特征图中每个通道的协方差,以了解不同通道之间的相互依赖性。这种方法能够更全面地反映特征之间的关系,从而提高网络的判别能力。
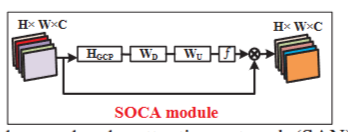
3. SOCA模块的实现步骤
SOCA模块的实现可以分为以下几个步骤:
-
特征提取:首先,从输入图像中提取特征图,通常通过一系列卷积层和激活函数来实现。
-
计算均值和协方差:
- 均值计算:对特征图的每个通道计算均值,以获得每个通道的全局特征表示。
- 协方差计算:计算特征图的协方差矩阵,以捕捉通道之间的相关性。协方差矩阵的每个元素表示两个通道之间的线性关系。
-
生成注意力权重:通过对协方差矩阵进行处理,生成通道注意力权重。这些权重反映了各个通道的重要性,能够自适应地调整特征图中各个通道的贡献。
-
特征重标定:将计算得到的注意力权重应用于原始特征图,进行特征重标定。通过这种方式,SOCA模块能够强调重要特征,同时抑制不重要的特征。
4. 优势与效果
-
增强特征表达:SOCA模块通过考虑二阶统计信息,使得网络能够更好地捕捉特征之间的关系,从而提高特征的表达能力。
-
提高判别能力:通过动态调整通道权重,SOCA模块能够增强网络对重要特征的关注,进而提高图像重建的质量。
-
实验验证:在多个标准数据集上的实验结果表明,使用SOCA模块的网络在视觉质量和定量指标上均优于传统方法,证明了其有效性。
核心代码
lass SOCA(nn.Module):
def __init__(self, channel, reduction=8):
super(SOCA, self).__init__()
# global average pooling: feature --> point
# self.avg_pool = nn.AdaptiveAvgPool2d(1)
# self.max_pool = nn.AdaptiveMaxPool2d(1)
self.max_pool = nn.MaxPool2d(kernel_size=2)
# feature channel downscale and upscale --> channel weight
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
nn.Sigmoid()
# nn.BatchNorm2d(channel)
)
def forward(self, x):
batch_size, C, h, w = x.shape # x: NxCxHxW
N = int(h * w)
min_h = min(h, w)
h1 = 1000
w1 = 1000
if h < h1 and w < w1:
x_sub = x
elif h < h1 and w > w1:
# H = (h - h1) // 2
W = (w - w1) // 2
x_sub = x[:, :, :, W:(W + w1)]
elif w < w1 and h > h1:
H = (h - h1) // 2
# W = (w - w1) // 2
x_sub = x[:, :, H:H + h1, :]
else:
H = (h - h1) // 2
W = (w - w1) // 2
x_sub = x[:, :, H:(H + h1), W:(W + w1)]
# subsample
# subsample_scale = 2
# subsample = nn.Upsample(size=(h // subsample_scale, w // subsample_scale), mode='nearest')
# x_sub = subsample(x)
# max_pool = nn.MaxPool2d(kernel_size=2)
# max_pool = nn.AvgPool2d(kernel_size=2)
# x_sub = self.max_pool(x)
##
## MPN-COV
cov_mat = MPNCOV.CovpoolLayer(x_sub) # Global Covariance pooling layer
cov_mat_sqrt = MPNCOV.SqrtmLayer(cov_mat,5) # Matrix square root layer( including pre-norm,Newton-Schulz iter. and post-com. with 5 iteration)
##
cov_mat_sum = torch.mean(cov_mat_sqrt,1)
cov_mat_sum = cov_mat_sum.view(batch_size,C,1,1)
# y_ave = self.avg_pool(x)
# y_max = self.max_pool(x)
y_cov = self.conv_du(cov_mat_sum)
# y_max = self.conv_du(y_max)
# y = y_ave + y_max
# expand y to C*H*W
# expand_y = y.expand(-1,-1,h,w)
return y_cov*x
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-SCSA.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
# optimizer='MuSGD',
optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-SCSA',
)