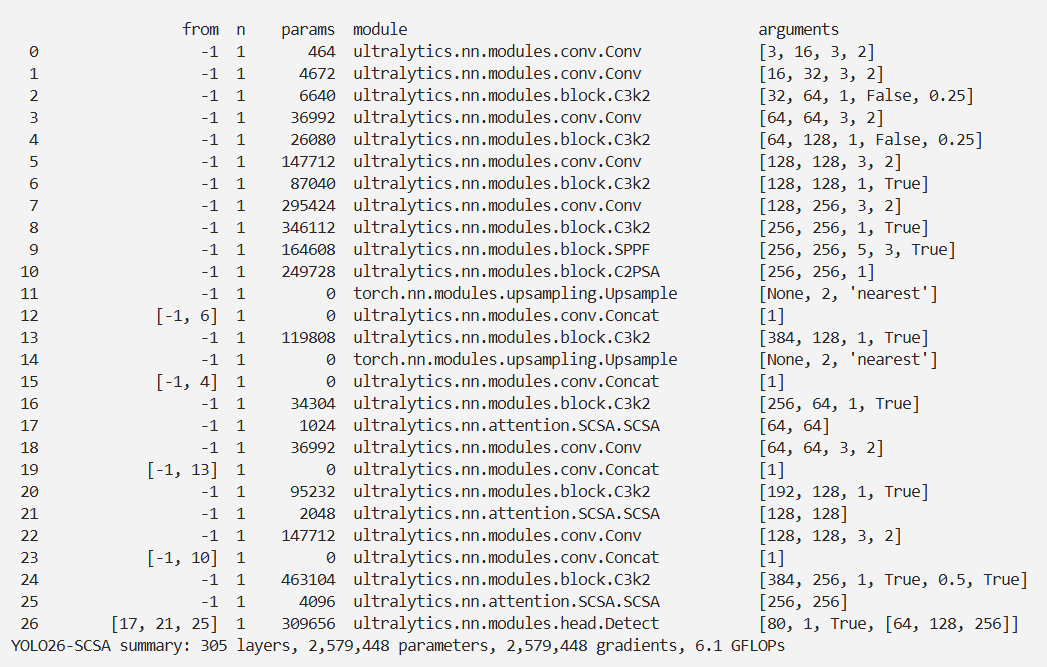
YOLO26 改进 – 注意力机制 SCSA注意力通过双重注意力机制增强局部-全局特征交互
前言
本文介绍了空间与通道协同注意力模块(SCSA)在YOLO26中的结合应用。SCSA由可共享多语义空间注意力(SMSA)和渐进式通道自注意力(PCSA)组成,通过SMSA整合多语义信息并注入判别性空间先验到PCSA,PCSA则缓解SMSA中多语义信息差异。我们将SCSA集成到YOLO26的检测头中,并进行相关注册和配置。实验表明,SCSA在多个基准数据集的分类、检测和分割任务中表现优异,优于现有注意力机制,泛化能力更强。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
介绍

摘要
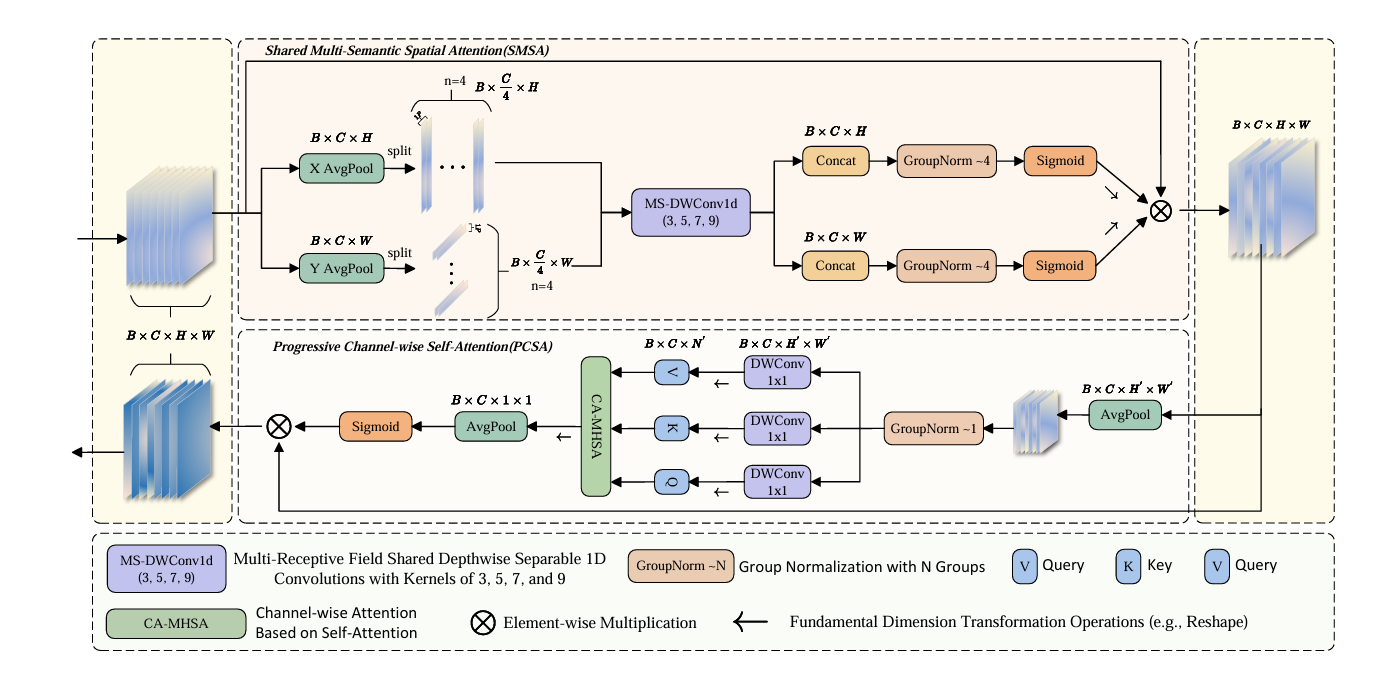
通道注意力机制和空间注意力机制分别在提取特征依赖关系和空间结构关系方面,为各类下游视觉任务带来了显著的性能提升。尽管将二者结合能够更好地发挥各自优势,但通道注意力与空间注意力之间的协同作用尚未得到充分研究,未能充分挖掘多语义信息的协同潜力以实现特征引导和缓解语义差异。本研究旨在揭示空间注意力和通道注意力在多语义层面的协同关系,提出了一种新颖的 空间与通道协同注意力模块(SCSA)。SCSA由 可共享多语义空间注意力(SMSA) 和 渐进式通道自注意力(PCSA) 两部分构成。SMSA整合多语义信息,并通过渐进式压缩策略将判别性空间先验注入到PCSA的通道自注意力中,从而有效引导通道重校准。此外,基于PCSA自注意力机制的强鲁棒性特征交互,进一步缓解了SMSA中不同子特征间的多语义信息差异。我们在七个基准数据集上开展了大量实验,涵盖ImageNet - 1K上的分类、MSCOCO 2017上的目标检测、ADE20K上的分割,以及其他四个复杂场景检测数据集。实验结果显示,我们提出的SCSA不仅优于当前最先进的注意力机制,还在各类任务场景中展现出更强的泛化能力。代码和模型已开源,地址为:https://github.com/HZAI-ZJNU/SCSA。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
SCSA(空间与通道协同注意力机制)是一种新颖的注意力机制,旨在通过有效整合空间和通道信息来提升视觉任务的性能。其技术原理可以分为以下几个关键部分:
-
多语义空间注意力(SMSA):
- SMSA通过将特征图划分为多个子特征,独立提取不同语义层次的信息。这种划分使得模型能够捕捉到不同对象的独特模式,尤其是在处理具有语义差异的对象时。
- 采用深度可分离卷积,SMSA能够高效地学习空间特征,同时保持计算效率。
-
渐进式通道自注意力(PCSA):
- PCSA在SMSA的基础上,进一步整合通道信息,通过自注意力机制强调重要特征通道。这一过程能够有效地增强特征的表达能力,提升模型对复杂场景的适应性。
- PCSA通过对通道间的关系进行建模,能够更好地处理不同类别或同类别不同尺度的对象。
-
协同设计:
- SCSA的设计理念在于空间和通道信息的协同作用,强调两者在特征提取过程中的互补性。通过这种协同,SCSA能够在保持模型轻量化的同时,显著提升检测和分割任务的性能。
- 该机制还通过缓解语义歧义,促进特征之间的强交互和重校准,从而提高模型的鲁棒性和泛化能力。
核心代码
class SCSA(BaseModule):
def __init__(
self,
dim: int,
head_num: int,
window_size: int = 7,
group_kernel_sizes: t.List[int] = [3, 5, 7, 9],
qkv_bias: bool = False,
fuse_bn: bool = False,
norm_cfg: t.Dict = dict(type='BN'),
act_cfg: t.Dict = dict(type='ReLU'),
down_sample_mode: str = 'avg_pool',
attn_drop_ratio: float = 0.,
gate_layer: str = 'sigmoid',
):
super(SCSA, self).__init__()
self.dim = dim
self.head_num = head_num
self.head_dim = dim // head_num
self.scaler = self.head_dim ** -0.5
self.group_kernel_sizes = group_kernel_sizes
self.window_size = window_size
self.qkv_bias = qkv_bias
self.fuse_bn = fuse_bn
self.down_sample_mode = down_sample_mode
assert self.dim // 4, 'The dimension of input feature should be divisible by 4.'
self.group_chans = group_chans = self.dim // 4
self.local_dwc = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[0],
padding=group_kernel_sizes[0] // 2, groups=group_chans)
self.global_dwc_s = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[1],
padding=group_kernel_sizes[1] // 2, groups=group_chans)
self.global_dwc_m = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[2],
padding=group_kernel_sizes[2] // 2, groups=group_chans)
self.global_dwc_l = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[3],
padding=group_kernel_sizes[3] // 2, groups=group_chans)
self.sa_gate = nn.Softmax(dim=2) if gate_layer == 'softmax' else nn.Sigmoid()
self.norm_h = nn.GroupNorm(4, dim)
self.norm_w = nn.GroupNorm(4, dim)
self.conv_d = nn.Identity()
self.norm = nn.GroupNorm(1, dim)
self.q = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=1, bias=qkv_bias, groups=dim)
self.k = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=1, bias=qkv_bias, groups=dim)
self.v = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=1, bias=qkv_bias, groups=dim)
self.attn_drop = nn.Dropout(attn_drop_ratio)
self.ca_gate = nn.Softmax(dim=1) if gate_layer == 'softmax' else nn.Sigmoid()
if window_size == -1:
self.down_func = nn.AdaptiveAvgPool2d((1, 1))
else:
if down_sample_mode == 'recombination':
self.down_func = self.space_to_chans
# dimensionality reduction
self.conv_d = nn.Conv2d(in_channels=dim * window_size ** 2, out_channels=dim, kernel_size=1, bias=False)
elif down_sample_mode == 'avg_pool':
self.down_func = nn.AvgPool2d(kernel_size=(window_size, window_size), stride=window_size)
elif down_sample_mode == 'max_pool':
self.down_func = nn.MaxPool2d(kernel_size=(window_size, window_size), stride=window_size)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
The dim of x is (B, C, H, W)
"""
# Spatial attention priority calculation
b, c, h_, w_ = x.size()
# (B, C, H)
x_h = x.mean(dim=3)
l_x_h, g_x_h_s, g_x_h_m, g_x_h_l = torch.split(x_h, self.group_chans, dim=1)
# (B, C, W)
x_w = x.mean(dim=2)
l_x_w, g_x_w_s, g_x_w_m, g_x_w_l = torch.split(x_w, self.group_chans, dim=1)
x_h_attn = self.sa_gate(self.norm_h(torch.cat((
self.local_dwc(l_x_h),
self.global_dwc_s(g_x_h_s),
self.global_dwc_m(g_x_h_m),
self.global_dwc_l(g_x_h_l),
), dim=1)))
x_h_attn = x_h_attn.view(b, c, h_, 1)
x_w_attn = self.sa_gate(self.norm_w(torch.cat((
self.local_dwc(l_x_w),
self.global_dwc_s(g_x_w_s),
self.global_dwc_m(g_x_w_m),
self.global_dwc_l(g_x_w_l)
), dim=1)))
x_w_attn = x_w_attn.view(b, c, 1, w_)
x = x * x_h_attn * x_w_attn
# Channel attention based on self attention
# reduce calculations
y = self.down_func(x)
y = self.conv_d(y)
_, _, h_, w_ = y.size()
# normalization first, then reshape -> (B, H, W, C) -> (B, C, H * W) and generate q, k and v
y = self.norm(y)
q = self.q(y)
k = self.k(y)
v = self.v(y)
# (B, C, H, W) -> (B, head_num, head_dim, N)
q = rearrange(q, 'b (head_num head_dim) h w -> b head_num head_dim (h w)', head_num=int(self.head_num),
head_dim=int(self.head_dim))
k = rearrange(k, 'b (head_num head_dim) h w -> b head_num head_dim (h w)', head_num=int(self.head_num),
head_dim=int(self.head_dim))
v = rearrange(v, 'b (head_num head_dim) h w -> b head_num head_dim (h w)', head_num=int(self.head_num),
head_dim=int(self.head_dim))
# (B, head_num, head_dim, head_dim)
attn = q @ k.transpose(-2, -1) * self.scaler
attn = self.attn_drop(attn.softmax(dim=-1))
# (B, head_num, head_dim, N)
attn = attn @ v
# (B, C, H_, W_)
attn = rearrange(attn, 'b head_num head_dim (h w) -> b (head_num head_dim) h w', h=int(h_), w=int(w_))
# (B, C, 1, 1)
attn = attn.mean((2, 3), keepdim=True)
attn = self.ca_gate(attn)
return attn * x
实验
脚本
这个模块在optimizer='MuSGD'会报错,是因为SCSA 注意力模块中的某些参数虽然被归类为需要 Muon 更新的参数(因为它们是 2D 的),但在训练过程中某些梯度变成了非 2D 形状,导致函数的断言失败
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-SCSA.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-SCSA',
)
结果