YOLOv11改进 – 卷积Conv GCBlock 聚焦于高效捕获特征图中的全局依赖关系
# 前言
本文介绍了GCBlock在YOLOv11中的结合应用。GCBlock是GCNet的核心组件,能高效捕获特征图中的全局依赖关系,融合了非局部网络和挤压 - 激励网络的优势,降低计算成本并保障模型性能。其遵循“上下文建模 - 特征变换 - 特征融合”框架,通过全局平均池化、全连接层等操作生成注意力权重。我们将GCBlock集成进YOLOv11,替代原有的部分卷积模块,实现更高效的全局上下文建模。实验证明,YOLOv11-GCBlock在目标检测任务中表现出色,展现了GCBlock在深度学习中的广泛应用前景。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总-CSDN博客
专栏链接: YOLOv11改进专栏
介绍

摘要
近年来的实时语义分割模型,无论是单分支还是多分支结构,都在性能和速度上取得了不错的表现。然而,这些模型的速度常常受到多路径模块的限制,有些还依赖于高性能的教师模型进行训练。为了解决这些问题,我们提出了 金箍棒网络(GCNet)。
具体来说,GCNet 在训练阶段结合了 纵向多卷积 和 横向多路径结构,在推理阶段则将这些结构重新参数化为一个单一的卷积操作,从而同时优化性能与速度。这样的设计使得 GCNet 能够在训练时“自我膨胀”,而在推理时“自我收缩”,相当于无需外部教师模型就具备了“教师模型”的能力。
实验结果表明,GCNet 在 Cityscapes、CamVid 和 Pascal VOC 2012 数据集上,在性能和推理速度方面都优于现有的先进模型。
项目代码已开源,地址为:https://github.com/gyyang23/GCNet
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
GCBlock全称为Global Context Block(全局上下文块),是ICCV 2019提出的Global Context Network(GCNet)的核心组件。它聚焦于高效捕获特征图中的全局依赖关系,巧妙融合了非局部网络(NLNet)建模全局依赖的优势与挤压 - 激励网络(SENet)轻量化的特点,在降低计算成本的同时保障了模型性能,以下是详细介绍:
- 核心设计背景
- 传统CNN依靠堆叠卷积层扩大感受野来获取全局信息,不仅参数量和计算量激增,还存在优化难、信息传递不充分的问题。
- NLNet虽能通过自注意力机制建模全局依赖,但需为每个查询位置计算专属注意力图,计算复杂度极高。而研究发现,不同查询位置的注意力图几乎一致,这意味着可简化为与查询位置无关的通用结构。
- SENet虽轻量化,但仅聚焦通道间依赖,对全局空间信息的建模能力不足。GCBlock正是针对这些问题,整合两类网络优势,形成高效的全局上下文建模方案。
- 核心结构与工作流程
GCBlock遵循“上下文建模 - 特征变换 - 特征融合”的通用框架,具体流程如下:
- 上下文建模模块:该模块负责聚合所有位置的特征以形成全局上下文特征。先输入特征图(X ∈ R^{C×H×W})(其中C为通道数,H、W分别为特征图的高和宽);再通过全局平均池化操作压缩空间维度,得到维度为(R^C)的全局上下文特征(z);最后经全连接层或1×1卷积层,结合softmax激活函数生成注意力权重,以此体现全局特征对各位置的重要性。
- 特征变换模块:此模块用于捕获通道间的依赖关系,同时控制计算量。它借鉴SENet的瓶颈结构,通过两层1×1卷积与ReLU激活函数完成特征变换。设置瓶颈比率(r)(默认值为16)缩减通道数,将原本(C×C)的参数量降至(2×C×C/r),大幅降低计算开销,同时有效提取通道维度的关键依赖信息。
- 特征融合模块:该模块的作用是将全局上下文特征与原始特征图融合。采用加法操作,把经过变换的全局上下文特征融入到输入特征图的每个位置中,让局部特征获得全局信息的补充,最终输出增强后的特征图(Y ∈ R^{C×H×W}),实现全局与局部信息的有机结合。
- 核心优势
- 轻量化易部署:通过简化注意力计算和瓶颈变换,GCBlock参数量和计算量远低于NLNet。例如在ResNet深层中应用时,其参数量仅为简化NLNet的1/8左右,可灵活嵌入骨干网络的多个层次。
- 性能全面领先:在图像分类、目标检测、语义分割等多个视觉任务的基准测试中,基于GCBlock构建的GCNet,性能普遍优于NLNet和SENet,既能保证全局依赖建模效果,又避免了冗余计算。
- 结构通用性强:其框架可兼容NLNet和SENet的核心逻辑,便于与ResNet、ResNeXt等主流骨干网络结合,适配不同场景的视觉任务优化需求。
- 典型应用场景
- 目标检测与实例分割:将GCBlock嵌入Mask R - CNN等模型的骨干网络,能提升对小目标、遮挡目标的特征提取能力,在COCO数据集上可在参数量相近的情况下,优于含NLNet的模型性能。
- 语义分割:在Camvid等数据集上,结合ResNet50作为骨干网络,GCBlock可增强全局语义信息的传递,助力模型区分相似类别区域。
- 图像分类:嵌入ResNet等分类网络的多个层次,可提升模型对全局场景和细节特征的综合理解,提升分类准确率。
- 代码实现特点
其PyTorch实现通常以轻量化为核心,通过全局平均池化、1×1卷积实现核心逻辑,同时设置通道缩减比率控制计算量。例如通过定义
ratio参数缩减通道数,结合层归一化提升模型稳定性,可直接嵌入卷积神经网络的残差块中使用。
核心代码
class GCBlock(nn.Module):
"""GCBlock.
Args:
in_channels (int): Number of channels in the input image
out_channels (int): Number of channels produced by the convolution
kernel_size (int or tuple): Size of the convolving kernel
stride (int or tuple): Stride of the convolution. Default: 1
padding (int, tuple): Padding added to all four sides of
the input. Default: 1
padding_mode (string, optional): Default: 'zeros'
norm_cfg (dict): Config dict to build norm layer.
Default: dict(type='BN', requires_grad=True)
act (bool) : Whether to use activation function.
Default: False
deploy (bool): Whether in deploy mode. Default: False
"""
def __init__(self,
in_channels: int,
out_channels: int,
kernel_size: Union[int, Tuple[int]] = 3,
stride: Union[int, Tuple[int]] = 1,
padding: Union[int, Tuple[int]] = 1,
padding_mode: Optional[str] = 'zeros',
norm_cfg: OptConfigType = dict(type='BN', requires_grad=True),
act_cfg: OptConfigType = dict(type='ReLU', inplace=True),
act: bool = True,
deploy: bool = False):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.deploy = deploy
assert kernel_size == 3
assert padding == 1
padding_11 = padding - kernel_size // 2
if act:
self.relu = build_activation_layer(act_cfg)
else:
self.relu = nn.Identity()
if deploy:
self.reparam_3x3 = nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
bias=True,
padding_mode=padding_mode)
else:
if (out_channels == in_channels) and stride == 1:
self.path_residual = build_norm_layer(norm_cfg, num_features=in_channels)[1]
else:
self.path_residual = None
self.path_3x3_1 = Block3x3(
in_channels=in_channels,
out_channels=out_channels,
stride=stride,
padding=padding,
bias=False,
norm_cfg=norm_cfg,
)
self.path_3x3_2 = Block3x3(
in_channels=in_channels,
out_channels=out_channels,
stride=stride,
padding=padding,
bias=False,
norm_cfg=norm_cfg,
)
self.path_1x1 = Block1x1(
in_channels=in_channels,
out_channels=out_channels,
stride=stride,
padding=padding_11,
bias=False,
norm_cfg=norm_cfg,
)
def forward(self, inputs: Tensor) -> Tensor:
if hasattr(self, 'reparam_3x3'):
return self.relu(self.reparam_3x3(inputs))
if self.path_residual is None:
id_out = 0
else:
id_out = self.path_residual(inputs)
return self.relu(self.path_3x3_1(inputs) + self.path_3x3_2(inputs) + self.path_1x1(inputs) + id_out)
def get_equivalent_kernel_bias(self):
"""Derives the equivalent kernel and bias in a differentiable way.
Returns:
tuple: Equivalent kernel and bias
"""
self.path_3x3_1.switch_to_deploy()
kernel3x3_1, bias3x3_1 = self.path_3x3_1.conv.weight.data, self.path_3x3_1.conv.bias.data
self.path_3x3_2.switch_to_deploy()
kernel3x3_2, bias3x3_2 = self.path_3x3_2.conv.weight.data, self.path_3x3_2.conv.bias.data
self.path_1x1.switch_to_deploy()
kernel1x1, bias1x1 = self.path_1x1.conv.weight.data, self.path_1x1.conv.bias.data
kernelid, biasid = self._fuse_bn_tensor(self.path_residual)
return kernel3x3_1 + kernel3x3_2 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3_1 + bias3x3_2 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
"""Pad 1x1 tensor to 3x3.
Args:
kernel1x1 (Tensor): The input 1x1 kernel need to be padded.
Returns:
Tensor: 3x3 kernel after padded.
"""
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, conv: nn.Module) -> Tuple[np.ndarray, Tensor]:
"""Derives the equivalent kernel and bias of a specific conv layer.
Args:
conv (nn.Module): The layer that needs to be equivalently
transformed, which can be nn.Sequential or nn.Batchnorm2d
Returns:
tuple: Equivalent kernel and bias
"""
if conv is None:
return 0, 0
if isinstance(conv, ConvModule):
kernel = conv.conv.weight
running_mean = conv.bn.running_mean
running_var = conv.bn.running_var
gamma = conv.bn.weight
beta = conv.bn.bias
eps = conv.bn.eps
else:
assert isinstance(conv, (nn.SyncBatchNorm, nn.BatchNorm2d, _BatchNormXd))
if not hasattr(self, 'id_tensor'):
input_in_channels = self.in_channels
kernel_value = np.zeros((self.in_channels, input_in_channels, 3, 3),
dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_in_channels, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(
conv.weight.device)
kernel = self.id_tensor
running_mean = conv.running_mean
running_var = conv.running_var
gamma = conv.weight
beta = conv.bias
eps = conv.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
"""Switch to deploy mode."""
if hasattr(self, 'reparam_3x3'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.reparam_3x3 = nn.Conv2d(
in_channels=self.in_channels,
out_channels=self.out_channels,
kernel_size=self.kernel_size,
stride=self.stride,
padding=self.padding,
bias=True)
self.reparam_3x3.weight.data = kernel
self.reparam_3x3.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('path_3x3_1')
self.__delattr__('path_3x3_2')
self.__delattr__('path_1x1')
if hasattr(self, 'path_residual'):
self.__delattr__('path_residual')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('/root/ultralytics-main/ultralytics/cfg/models/11/yolov11-GCBlock.yaml')
# 修改为自己的数据集地址
model.train(data='/root/ultralytics-main/ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='SGD',
amp=True,
project='runs/train',
name='GCBlock',
)
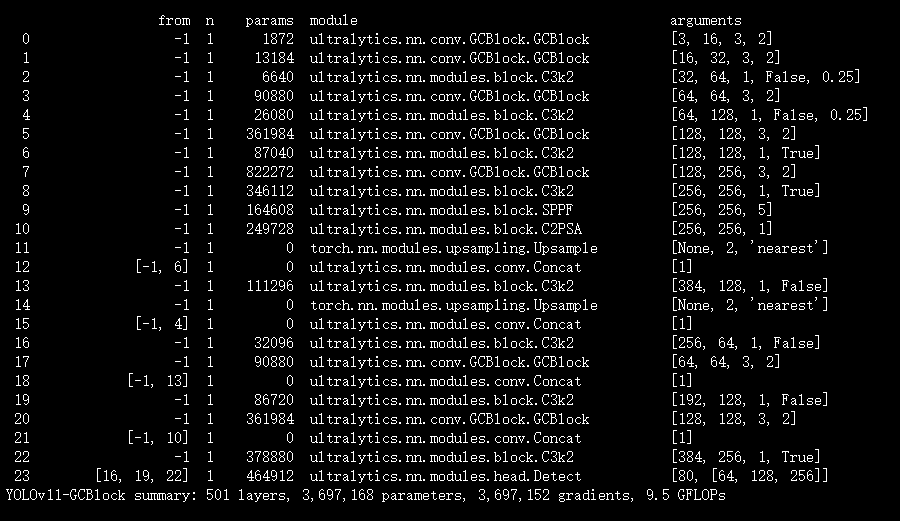
结果