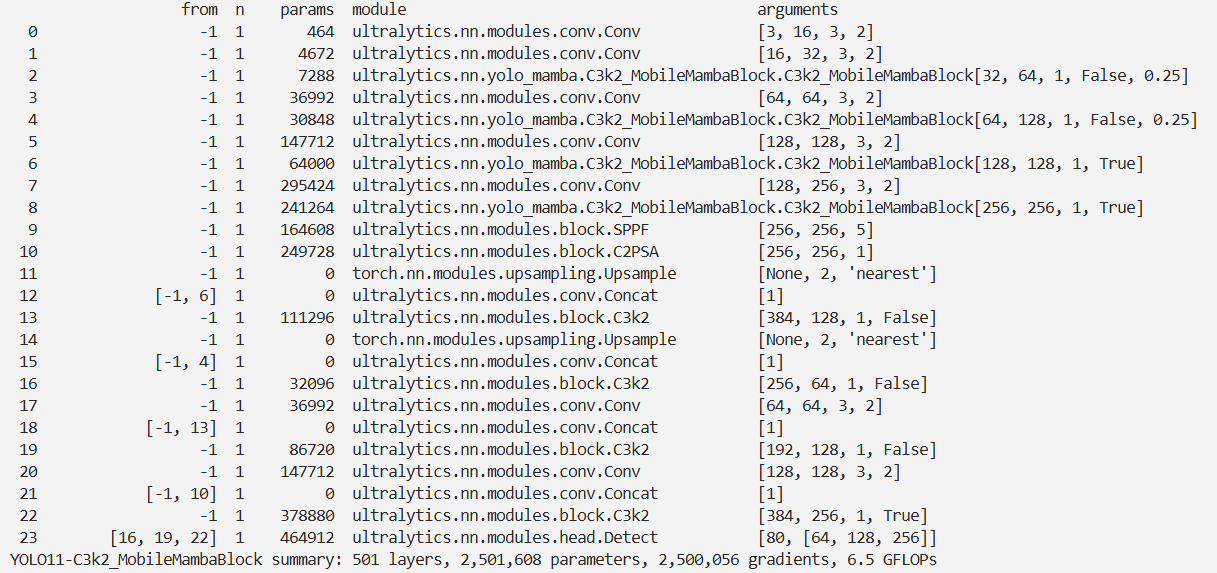
YOLOv11改进 – Mamba C3k2融合MobileMambaBlock在轻量前提下,融合全局、多尺度局部特征并保留高频细节
# 前言
本文介绍了MobileMamba Block,其设计核心是在轻量前提下融合全局、多尺度局部特征并保留高频细节,兼顾推理效率。它是模型的核心功能单元,采用“对称局部感知 + MRFFI 核心模块 + FFN 增强”架构。MRFFI 模块是关键,将输入特征按通道拆分为三部分处理:WTE - Mamba 提取全局和高频细节,MK - DeConv 实现多尺度局部感知,Eliminate Redundant Identity 压缩冗余。我们将其引入 YOLOv11,在根目录下添加相关代码文件,并在ultralytics/nn/tasks.py中注册,还给出了配置文件和实验脚本。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
介绍

摘要
以往关于轻量级模型的研究主要集中在卷积神经网络(CNN)和基于 Transformer 的架构上。CNN 凭借其局部感受野,难以捕捉长距离依赖关系;而 Transformer 尽管具备全局建模能力,但在高分辨率场景下却受限于二次计算复杂度。最近,状态空间模型因其线性计算复杂度在视觉领域受到广泛关注。尽管当前的基于 Mamba 的轻量级模型计算量(FLOPs)较低,但其吞吐量表现并不理想。
在本文中,我们提出了 MobileMamba 框架,旨在平衡效率与性能。我们设计了一个三阶段网络,以显著提升推理速度。在细粒度层面上,我们引入了多感受野特征交互(MRFFI)模块,该模块包含长距离小波变换增强型 Mamba(WTE-Mamba)、高效多核深度卷积(MK-DeConv)以及消除冗余恒等映射组件。该模块融合了多感受野信息,并增强了高频细节的提取能力。
此外,我们还采用了特定的训练和测试策略,以进一步提高性能和效率。MobileMamba 的 Top-1 准确率高达 83.6%,超越了现有的最先进方法,并且在 GPU 上的速度比 LocalVim 最高快 21 倍。在高分辨率下游任务上进行的广泛实验表明,MobileMamba 优于当前的高效模型,实现了速度与精度的最佳平衡。
完整代码已在 https://github.com/lewandofskee/MobileMamba 开源。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
MobileMamba Block 的设计核心是在轻量前提下,融合全局、多尺度局部特征并保留高频细节,同时兼顾推理效率,整体遵循“局部感知→多感受野交互→特征增强”的逻辑,具体设计思路如下:
1. 定位:Block 在网络中的角色
每个 MobileMamba Block 是模型的核心功能单元,串联于“三阶段网络”的各阶段中(论文 3.1 节)。其核心目标是解决传统轻量模型的痛点:CNN 局部感知局限、Transformer 计算复杂、现有 Mamba 模型 throughput 不足,实现“全局+局部”特征的高效融合。
2. 整体结构设计:对称布局+核心交互模块
Block 采用“对称局部感知 + MRFFI 核心模块 + FFN 增强”的架构(论文 3.2 节+图 4(c)):
- 两侧对称设置 局部信息感知模块:通过 3x3 深度卷积(DWConv)+ 批量归一化(BN)实现,快速捕捉局部相邻特征,为后续交互提供基础。
- 中间嵌入 多感受野特征交互(MRFFI)模块:Block 的核心创新,负责拆分并处理不同通道的特征,融合全局、多尺度局部信息。
- 两端搭配 前馈网络(FFN):通过“卷积+激活”的简单结构增强特征表达能力,同时控制计算复杂度(扩张系数设为 2,平衡性能与效率)。
- 保留 残差连接(Identity Skip):直接传递原始输入特征,缓解深层网络梯度消失问题,同时降低计算冗余(论文 3.2 节)。
3. 核心:MRFFI 模块的三分支设计
MRFFI 模块是 Block 实现“多感受野融合”的关键,将输入特征按通道维度拆分为 3 部分,分别处理后拼接输出(论文 3.2 节):
分支 1:WTE-Mamba(全局+高频细节提取)
- 功能:同时捕捉全局依赖和高频边缘细节(如物体轮廓、纹理)。
- 实现逻辑:
- 对部分通道特征(占比 ξ)用双向扫描 Mamba 模块做全局建模,学习长距离关联。
- 对同一特征图做 Haar 小波变换(WT),拆分出 1 个低频(保留核心信息)和 3 个高频(边缘细节)特征图。
- 对小波变换后的特征图做局部卷积,再通过逆小波变换(IWT) 恢复原始尺寸,最终与 Mamba 输出相加,既保留全局信息又增强细节。
分支 2:MK-DeConv(多尺度局部感知)
- 功能:通过多 kernel 卷积捕捉不同尺度的局部特征(如小物体、局部结构)。
- 实现逻辑:
- 选取部分通道特征(占比 μ),拆分为 n 组(n 为正整数)。
- 每组用不同尺寸的奇数核(k=3、5、7...)做深度卷积,对应不同感受野。
- 拼接各组卷积结果,整合多尺度局部特征,提升模型对不同大小物体的适应性。
分支 3:Eliminate Redundant Identity(冗余压缩)
- 功能:减少高维特征的通道冗余,降低计算量。
- 实现逻辑:对剩余通道(占比 1-ξ-μ)直接做恒等映射,不额外添加卷积等复杂操作,仅传递核心特征,避免无效计算。
4. 设计权衡:效率与性能的平衡
- 通道比例控制:全局(ξ)、局部(μ)、冗余压缩(1-ξ-μ)的比例固定(如 {0.8,0.7,0.6} 和 {0.2,0.2,0.3},论文表 2),确保不同模型尺度(T2~B4)的一致性。
- 简化计算:MRFFI 三分支均基于“通道拆分”而非“特征图拆分”,避免空间维度的冗余计算;MK-DeConv 默认 n=1(kernel=3),通过小波变换间接扩大感受野(ERF 从 3 翻倍至 6),兼顾简单性与效果(论文 4.4 节消融实验)。
5. 辅助优化:正则化与适配策略
- 加入 DropPath 正则化:仅在较深的 B1 模型中使用(rate=0.03),防止过拟合,浅模型(T2、T4、S6)因深度不足省略,避免性能损失(论文补充材料 A.3)。
- 支持 分辨率适配:小模型(T2、T4)用低输入分辨率(192x192)保证速度,大模型(B2、B4)提升分辨率(384x384、512x512)提升性能,Block 内部结构不变,仅调整输入维度适配(论文 4.4 节)。
安装依赖
安装pywt
pip install pywaveletsYOLO11引入代码
在根目录下的ultralytics/nn/目录,新建一个mamba目录,然后新建一个以 lib_mamba为文件名的 文件夹, 把代码拷贝进去。
然后把MobileMamba代码库中的https://github.com/lewandofskee/MobileMamba/tree/main/model/lib_mamba整个文件夹考进去
然后手动再拷贝下面的代码到对应的文件中
csm_triton.py
import torch
import warnings
WITH_TRITON = True
# WITH_TRITON = False
try:
import triton
import triton.language as tl
except:
WITH_TRITON = False
# warnings.warn("Triton not installed, fall back to pytorch implements.")
# to make sure cached_property can be loaded for triton
if WITH_TRITON:
try:
from functools import cached_property
except:
# warnings.warn("if you are using py37, add this line to functools.py: "
# "cached_property = lambda func: property(lru_cache()(func))")
pass
# torch implementation ========================================
def cross_scan_fwd(x: torch.Tensor, in_channel_first=True, out_channel_first=True, scans=0):
if in_channel_first:
B, C, H, W = x.shape
if scans == 0:
y = x.new_empty((B, 4, C, H * W))
y[:, 0, :, :] = x.flatten(2, 3)
y[:, 1, :, :] = x.transpose(dim0=2, dim1=3).flatten(2, 3)
y[:, 2:4, :, :] = torch.flip(y[:, 0:2, :, :], dims=[-1])
elif scans == 1:
y = x.view(B, 1, C, H * W).repeat(1, 4, 1, 1)
elif scans == 2:
y = x.view(B, 1, C, H * W).repeat(1, 2, 1, 1)
y = torch.cat([y, y.flip(dims=[-1])], dim=1)
else:
B, H, W, C = x.shape
if scans == 0:
y = x.new_empty((B, H * W, 4, C))
y[:, :, 0, :] = x.flatten(1, 2)
y[:, :, 1, :] = x.transpose(dim0=1, dim1=2).flatten(1, 2)
y[:, :, 2:4, :] = torch.flip(y[:, :, 0:2, :], dims=[1])
elif scans == 1:
y = x.view(B, H * W, 1, C).repeat(1, 1, 4, 1)
elif scans == 2:
y = x.view(B, H * W, 1, C).repeat(1, 1, 2, 1)
y = torch.cat([y, y.flip(dims=[1])], dim=2)
if in_channel_first and (not out_channel_first):
y = y.permute(0, 3, 1, 2).contiguous()
elif (not in_channel_first) and out_channel_first:
y = y.permute(0, 2, 3, 1).contiguous()
return y
def cross_merge_fwd(y: torch.Tensor, in_channel_first=True, out_channel_first=True, scans=0):
if out_channel_first:
B, K, D, H, W = y.shape
y = y.view(B, K, D, -1)
if scans == 0:
y = y[:, 0:2] + y[:, 2:4].flip(dims=[-1]).view(B, 2, D, -1)
y = y[:, 0] + y[:, 1].view(B, -1, W, H).transpose(dim0=2, dim1=3).contiguous().view(B, D, -1)
elif scans == 1:
y = y.sum(1)
elif scans == 2:
y = y[:, 0:2] + y[:, 2:4].flip(dims=[-1]).view(B, 2, D, -1)
y = y.sum(1)
else:
B, H, W, K, D = y.shape
y = y.view(B, -1, K, D)
if scans == 0:
y = y[:, :, 0:2] + y[:, :, 2:4].flip(dims=[1]).view(B, -1, 2, D)
y = y[:, :, 0] + y[:, :, 1].view(B, W, H, -1).transpose(dim0=1, dim1=2).contiguous().view(B, -1, D)
elif scans == 1:
y = y.sum(2)
elif scans == 2:
y = y[:, :, 0:2] + y[:, :, 2:4].flip(dims=[1]).view(B, -1, 2, D)
y = y.sum(2)
if in_channel_first and (not out_channel_first):
y = y.permute(0, 2, 1).contiguous()
elif (not in_channel_first) and out_channel_first:
y = y.permute(0, 2, 1).contiguous()
return y
def cross_scan1b1_fwd(x: torch.Tensor, in_channel_first=True, out_channel_first=True, scans=0):
if in_channel_first:
B, _, C, H, W = x.shape
if scans == 0:
y = torch.stack([
x[:, 0].flatten(2, 3),
x[:, 1].transpose(dim0=2, dim1=3).flatten(2, 3),
torch.flip(x[:, 2].flatten(2, 3), dims=[-1]),
torch.flip(x[:, 3].transpose(dim0=2, dim1=3).flatten(2, 3), dims=[-1]),
], dim=1)
elif scans == 1:
y = x.flatten(2, 3)
elif scans == 2:
y = torch.stack([
x[:, 0].flatten(2, 3),
x[:, 1].flatten(2, 3),
torch.flip(x[:, 2].flatten(2, 3), dims=[-1]),
torch.flip(x[:, 3].flatten(2, 3), dims=[-1]),
], dim=1)
else:
B, H, W, _, C = x.shape
if scans == 0:
y = torch.stack([
x[:, :, :, 0].flatten(1, 2),
x[:, :, :, 1].transpose(dim0=1, dim1=2).flatten(1, 2),
torch.flip(x[:, :, :, 2].flatten(1, 2), dims=[1]),
torch.flip(x[:, :, :, 3].transpose(dim0=1, dim1=2).flatten(1, 2), dims=[1]),
], dim=2)
elif scans == 1:
y = x.flatten(1, 2)
elif scans == 2:
y = torch.stack([
x[:, 0].flatten(1, 2),
x[:, 1].flatten(1, 2),
torch.flip(x[:, 2].flatten(1, 2), dims=[-1]),
torch.flip(x[:, 3].flatten(1, 2), dims=[-1]),
], dim=2)
if in_channel_first and (not out_channel_first):
y = y.permute(0, 3, 1, 2).contiguous()
elif (not in_channel_first) and out_channel_first:
y = y.permute(0, 2, 3, 1).contiguous()
return y
def cross_merge1b1_fwd(y: torch.Tensor, in_channel_first=True, out_channel_first=True, scans=0):
if out_channel_first:
B, K, D, H, W = y.shape
y = y.view(B, K, D, -1)
if scans == 0:
y = torch.stack([
y[:, 0],
y[:, 1].view(B, -1, W, H).transpose(dim0=2, dim1=3).flatten(2, 3),
torch.flip(y[:, 2], dims=[-1]),
torch.flip(y[:, 3].view(B, -1, W, H).transpose(dim0=2, dim1=3).flatten(2, 3), dims=[-1]),
], dim=1)
elif scans == 1:
y = y
elif scans == 2:
y = torch.stack([
y[:, 0],
y[:, 1],
torch.flip(y[:, 2], dims=[-1]),
torch.flip(y[:, 3], dims=[-1]),
], dim=1)
else:
B, H, W, _, D = y.shape
y = y.view(B, -1, K, D)
if scans == 0:
y = torch.stack([
y[:, :, 0],
y[:, :, 1].view(B, W, H, -1).transpose(dim0=1, dim1=2).flatten(1, 2),
torch.flip(y[:, :, 2], dims=[1]),
torch.flip(y[:, :, 3].view(B, W, H, -1).transpose(dim0=1, dim1=2).flatten(1, 2), dims=[1]),
], dim=2)
elif scans == 1:
y = y
elif scans == 2:
y = torch.stack([
y[:, :, 0],
y[:, :, 1],
torch.flip(y[:, :, 2], dims=[1]),
torch.flip(y[:, :, 3], dims=[1]),
], dim=2)
if out_channel_first and (not in_channel_first):
y = y.permute(0, 3, 1, 2).contiguous()
elif (not out_channel_first) and in_channel_first:
y = y.permute(0, 2, 3, 1).contiguous()
return y
class CrossScanF(torch.autograd.Function):
@staticmethod
def forward(ctx, x: torch.Tensor, in_channel_first=True, out_channel_first=True, one_by_one=False, scans=0):
# x: (B, C, H, W) | (B, H, W, C) | (B, 4, C, H, W) | (B, H, W, 4, C)
# y: (B, 4, C, H * W) | (B, H * W, 4, C)
ctx.in_channel_first = in_channel_first
ctx.out_channel_first = out_channel_first
ctx.one_by_one = one_by_one
ctx.scans = scans
if one_by_one:
B, K, C, H, W = x.shape
if not in_channel_first:
B, H, W, K, C = x.shape
else:
B, C, H, W = x.shape
if not in_channel_first:
B, H, W, C = x.shape
ctx.shape = (B, C, H, W)
_fn = cross_scan1b1_fwd if one_by_one else cross_scan_fwd
y = _fn(x, in_channel_first, out_channel_first, scans)
return y
@staticmethod
def backward(ctx, ys: torch.Tensor):
# out: (b, k, d, l)
in_channel_first = ctx.in_channel_first
out_channel_first = ctx.out_channel_first
one_by_one = ctx.one_by_one
scans = ctx.scans
B, C, H, W = ctx.shape
ys = ys.view(B, -1, C, H, W) if out_channel_first else ys.view(B, H, W, -1, C)
_fn = cross_merge1b1_fwd if one_by_one else cross_merge_fwd
y = _fn(ys, in_channel_first, out_channel_first, scans)
if one_by_one:
y = y.view(B, 4, -1, H, W) if in_channel_first else y.view(B, H, W, 4, -1)
else:
y = y.view(B, -1, H, W) if in_channel_first else y.view(B, H, W, -1)
return y, None, None, None, None
class CrossMergeF(torch.autograd.Function):
@staticmethod
def forward(ctx, ys: torch.Tensor, in_channel_first=True, out_channel_first=True, one_by_one=False, scans=0):
# x: (B, C, H, W) | (B, H, W, C) | (B, 4, C, H, W) | (B, H, W, 4, C)
# y: (B, 4, C, H * W) | (B, H * W, 4, C)
ctx.in_channel_first = in_channel_first
ctx.out_channel_first = out_channel_first
ctx.one_by_one = one_by_one
ctx.scans = scans
B, K, C, H, W = ys.shape
if not out_channel_first:
B, H, W, K, C = ys.shape
ctx.shape = (B, C, H, W)
_fn = cross_merge1b1_fwd if one_by_one else cross_merge_fwd
y = _fn(ys, in_channel_first, out_channel_first, scans)
return y
@staticmethod
def backward(ctx, x: torch.Tensor):
# B, D, L = x.shape
# out: (b, k, d, h, w)
in_channel_first = ctx.in_channel_first
out_channel_first = ctx.out_channel_first
one_by_one = ctx.one_by_one
scans = ctx.scans
B, C, H, W = ctx.shape
if not one_by_one:
if in_channel_first:
x = x.view(B, C, H, W)
else:
x = x.view(B, H, W, C)
else:
if in_channel_first:
x = x.view(B, 4, C, H, W)
else:
x = x.view(B, H, W, 4, C)
_fn = cross_scan1b1_fwd if one_by_one else cross_scan_fwd
x = _fn(x, in_channel_first, out_channel_first, scans)
x = x.view(B, 4, C, H, W) if out_channel_first else x.view(B, H, W, 4, C)
return x, None, None, None, None
# triton implements ========================================
try:
@triton.jit
def triton_cross_scan_flex(
x, # (B, C, H, W) | (B, H, W, C) | (B, 4, C, H, W) | (B, H, W, 4, C)
y, # (B, 4, C, H, W) | (B, H, W, 4, C)
x_layout: tl.constexpr,
y_layout: tl.constexpr,
operation: tl.constexpr,
onebyone: tl.constexpr,
scans: tl.constexpr,
BC: tl.constexpr,
BH: tl.constexpr,
BW: tl.constexpr,
DC: tl.constexpr,
DH: tl.constexpr,
DW: tl.constexpr,
NH: tl.constexpr,
NW: tl.constexpr,
):
# x_layout = 0
# y_layout = 1 # 0 BCHW, 1 BHWC
# operation = 0 # 0 scan, 1 merge
# onebyone = 0 # 0 false, 1 true
# scans = 0 # 0 cross scan, 1 unidirectional, 2 bidirectional
i_hw, i_c, i_b = tl.program_id(0), tl.program_id(1), tl.program_id(2)
i_h, i_w = (i_hw // NW), (i_hw % NW)
_mask_h = (i_h * BH + tl.arange(0, BH)) < DH
_mask_w = (i_w * BW + tl.arange(0, BW)) < DW
_mask_hw = _mask_h[:, None] & _mask_w[None, :]
_for_C = min(DC - i_c * BC, BC)
HWRoute0 = i_h * BH * DW + tl.arange(0, BH)[:, None] * DW + i_w * BW + tl.arange(0, BW)[None, :]
HWRoute1 = i_w * BW * DH + tl.arange(0, BW)[None, :] * DH + i_h * BH + tl.arange(0, BH)[:, None] # trans
HWRoute2 = (NH - i_h - 1) * BH * DW + (BH - 1 - tl.arange(0, BH)[:, None]) * DW + (NW - i_w - 1) * BW + (BW - 1 - tl.arange(0, BW)[None, :]) + (DH - NH * BH) * DW + (DW - NW * BW) # flip
HWRoute3 = (NW - i_w - 1) * BW * DH + (BW - 1 - tl.arange(0, BW)[None, :]) * DH + (NH - i_h - 1) * BH + (BH - 1 - tl.arange(0, BH)[:, None]) + (DH - NH * BH) + (DW - NW * BW) * DH # trans + flip
if scans == 1:
HWRoute1 = HWRoute0
HWRoute2 = HWRoute0
HWRoute3 = HWRoute0
elif scans == 2:
HWRoute1 = HWRoute0
HWRoute3 = HWRoute2
_tmp1 = DC * DH * DW
y_ptr_base = y + i_b * 4 * _tmp1 + (i_c * BC * DH * DW if y_layout == 0 else i_c * BC)
if y_layout == 0:
p_y1 = y_ptr_base + HWRoute0
p_y2 = y_ptr_base + _tmp1 + HWRoute1
p_y3 = y_ptr_base + 2 * _tmp1 + HWRoute2
p_y4 = y_ptr_base + 3 * _tmp1 + HWRoute3
else:
p_y1 = y_ptr_base + HWRoute0 * 4 * DC
p_y2 = y_ptr_base + DC + HWRoute1 * 4 * DC
p_y3 = y_ptr_base + 2 * DC + HWRoute2 * 4 * DC
p_y4 = y_ptr_base + 3 * DC + HWRoute3 * 4 * DC
if onebyone == 0:
x_ptr_base = x + i_b * _tmp1 + (i_c * BC * DH * DW if x_layout == 0 else i_c * BC)
if x_layout == 0:
p_x = x_ptr_base + HWRoute0
else:
p_x = x_ptr_base + HWRoute0 * DC
if operation == 0:
for idxc in range(_for_C):
_idx_x = idxc * DH * DW if x_layout == 0 else idxc
_idx_y = idxc * DH * DW if y_layout == 0 else idxc
_x = tl.load(p_x + _idx_x, mask=_mask_hw)
tl.store(p_y1 + _idx_y, _x, mask=_mask_hw)
tl.store(p_y2 + _idx_y, _x, mask=_mask_hw)
tl.store(p_y3 + _idx_y, _x, mask=_mask_hw)
tl.store(p_y4 + _idx_y, _x, mask=_mask_hw)
elif operation == 1:
for idxc in range(_for_C):
_idx_x = idxc * DH * DW if x_layout == 0 else idxc
_idx_y = idxc * DH * DW if y_layout == 0 else idxc
_y1 = tl.load(p_y1 + _idx_y, mask=_mask_hw)
_y2 = tl.load(p_y2 + _idx_y, mask=_mask_hw)
_y3 = tl.load(p_y3 + _idx_y, mask=_mask_hw)
_y4 = tl.load(p_y4 + _idx_y, mask=_mask_hw)
tl.store(p_x + _idx_x, _y1 + _y2 + _y3 + _y4, mask=_mask_hw)
else:
x_ptr_base = x + i_b * 4 * _tmp1 + (i_c * BC * DH * DW if x_layout == 0 else i_c * BC)
if x_layout == 0:
p_x1 = x_ptr_base + HWRoute0
p_x2 = p_x1 + _tmp1
p_x3 = p_x2 + _tmp1
p_x4 = p_x3 + _tmp1
else:
p_x1 = x_ptr_base + HWRoute0 * 4 * DC
p_x2 = p_x1 + DC
p_x3 = p_x2 + DC
p_x4 = p_x3 + DC
if operation == 0:
for idxc in range(_for_C):
_idx_x = idxc * DH * DW if x_layout == 0 else idxc
_idx_y = idxc * DH * DW if y_layout == 0 else idxc
tl.store(p_y1 + _idx_y, tl.load(p_x1 + _idx_x, mask=_mask_hw), mask=_mask_hw)
tl.store(p_y2 + _idx_y, tl.load(p_x2 + _idx_x, mask=_mask_hw), mask=_mask_hw)
tl.store(p_y3 + _idx_y, tl.load(p_x3 + _idx_x, mask=_mask_hw), mask=_mask_hw)
tl.store(p_y4 + _idx_y, tl.load(p_x4 + _idx_x, mask=_mask_hw), mask=_mask_hw)
else:
for idxc in range(_for_C):
_idx_x = idxc * DH * DW if x_layout == 0 else idxc
_idx_y = idxc * DH * DW if y_layout == 0 else idxc
tl.store(p_x1 + _idx_x, tl.load(p_y1 + _idx_y), mask=_mask_hw)
tl.store(p_x2 + _idx_x, tl.load(p_y2 + _idx_y), mask=_mask_hw)
tl.store(p_x3 + _idx_x, tl.load(p_y3 + _idx_y), mask=_mask_hw)
tl.store(p_x4 + _idx_x, tl.load(p_y4 + _idx_y), mask=_mask_hw)
except:
def triton_cross_scan_flex():
pass
class CrossScanTritonF(torch.autograd.Function):
@staticmethod
def forward(ctx, x: torch.Tensor, in_channel_first=True, out_channel_first=True, one_by_one=False, scans=0):
if one_by_one:
if in_channel_first:
B, _, C, H, W = x.shape
else:
B, H, W, _, C = x.shape
else:
if in_channel_first:
B, C, H, W = x.shape
else:
B, H, W, C = x.shape
B, C, H, W = int(B), int(C), int(H), int(W)
BC, BH, BW = 1, 32, 32
NH, NW, NC = triton.cdiv(H, BH), triton.cdiv(W, BW), triton.cdiv(C, BC)
ctx.in_channel_first = in_channel_first
ctx.out_channel_first = out_channel_first
ctx.one_by_one = one_by_one
ctx.scans = scans
ctx.shape = (B, C, H, W)
ctx.triton_shape = (BC, BH, BW, NC, NH, NW)
y = x.new_empty((B, 4, C, H * W)) if out_channel_first else x.new_empty((B, H * W, 4, C))
triton_cross_scan_flex[(NH * NW, NC, B)](
x.contiguous(), y,
(0 if in_channel_first else 1), (0 if out_channel_first else 1), 0, (0 if not one_by_one else 1), scans,
BC, BH, BW, C, H, W, NH, NW
)
return y
@staticmethod
def backward(ctx, y: torch.Tensor):
in_channel_first = ctx.in_channel_first
out_channel_first = ctx.out_channel_first
one_by_one = ctx.one_by_one
scans = ctx.scans
B, C, H, W = ctx.shape
BC, BH, BW, NC, NH, NW = ctx.triton_shape
if one_by_one:
x = y.new_empty((B, 4, C, H, W)) if in_channel_first else y.new_empty((B, H, W, 4, C))
else:
x = y.new_empty((B, C, H, W)) if in_channel_first else y.new_empty((B, H, W, C))
triton_cross_scan_flex[(NH * NW, NC, B)](
x, y.contiguous(),
(0 if in_channel_first else 1), (0 if out_channel_first else 1), 1, (0 if not one_by_one else 1), scans,
BC, BH, BW, C, H, W, NH, NW
)
return x, None, None, None, None
class CrossMergeTritonF(torch.autograd.Function):
@staticmethod
def forward(ctx, y: torch.Tensor, in_channel_first=True, out_channel_first=True, one_by_one=False, scans=0):
if out_channel_first:
B, _, C, H, W = y.shape
else:
B, H, W, _, C = y.shape
B, C, H, W = int(B), int(C), int(H), int(W)
BC, BH, BW = 1, 32, 32
NH, NW, NC = triton.cdiv(H, BH), triton.cdiv(W, BW), triton.cdiv(C, BC)
ctx.in_channel_first = in_channel_first
ctx.out_channel_first = out_channel_first
ctx.one_by_one = one_by_one
ctx.scans = scans
ctx.shape = (B, C, H, W)
ctx.triton_shape = (BC, BH, BW, NC, NH, NW)
if one_by_one:
x = y.new_empty((B, 4, C, H * W)) if in_channel_first else y.new_empty((B, H * W, 4, C))
else:
x = y.new_empty((B, C, H * W)) if in_channel_first else y.new_empty((B, H * W, C))
triton_cross_scan_flex[(NH * NW, NC, B)](
x, y.contiguous(),
(0 if in_channel_first else 1), (0 if out_channel_first else 1), 1, (0 if not one_by_one else 1), scans,
BC, BH, BW, C, H, W, NH, NW
)
return x
@staticmethod
def backward(ctx, x: torch.Tensor):
in_channel_first = ctx.in_channel_first
out_channel_first = ctx.out_channel_first
one_by_one = ctx.one_by_one
scans = ctx.scans
B, C, H, W = ctx.shape
BC, BH, BW, NC, NH, NW = ctx.triton_shape
y = x.new_empty((B, 4, C, H, W)) if out_channel_first else x.new_empty((B, H, W, 4, C))
triton_cross_scan_flex[(NH * NW, NC, B)](
x.contiguous(), y,
(0 if in_channel_first else 1), (0 if out_channel_first else 1), 0, (0 if not one_by_one else 1), scans,
BC, BH, BW, C, H, W, NH, NW
)
return y, None, None, None, None, None
# @torch.compile(options={"triton.cudagraphs": True}, fullgraph=True)
def cross_scan_fn(x: torch.Tensor, in_channel_first=True, out_channel_first=True, one_by_one=False, scans=0, force_torch=False):
# x: (B, C, H, W) | (B, H, W, C) | (B, 4, C, H, W) | (B, H, W, 4, C)
# y: (B, 4, C, L) | (B, L, 4, C)
# scans: 0: cross scan; 1 unidirectional; 2: bidirectional;
CSF = CrossScanTritonF if WITH_TRITON and x.is_cuda and (not force_torch) else CrossScanF
return CSF.apply(x, in_channel_first, out_channel_first, one_by_one, scans)
# @torch.compile(options={"triton.cudagraphs": True}, fullgraph=True)
def cross_merge_fn(y: torch.Tensor, in_channel_first=True, out_channel_first=True, one_by_one=False, scans=0, force_torch=False):
# y: (B, 4, C, L) | (B, L, 4, C)
# x: (B, C, H * W) | (B, H * W, C) | (B, 4, C, H * W) | (B, H * W, 4, C)
# scans: 0: cross scan; 1 unidirectional; 2: bidirectional;
CMF = CrossMergeTritonF if WITH_TRITON and y.is_cuda and (not force_torch) else CrossMergeF
return CMF.apply(y, in_channel_first, out_channel_first, one_by_one, scans)
# checks =================================================================
class CHECK:
def check_csm_triton():
B, C, H, W = 2, 192, 56, 57
dtype=torch.float16
dtype=torch.float32
x = torch.randn((B, C, H, W), dtype=dtype, device=torch.device("cuda")).requires_grad_(True)
y = torch.randn((B, 4, C, H, W), dtype=dtype, device=torch.device("cuda")).requires_grad_(True)
x1 = x.clone().detach().requires_grad_(True)
y1 = y.clone().detach().requires_grad_(True)
def cross_scan(x: torch.Tensor):
B, C, H, W = x.shape
L = H * W
xs = torch.stack([
x.view(B, C, L),
torch.transpose(x, dim0=2, dim1=3).contiguous().view(B, C, L),
torch.flip(x.contiguous().view(B, C, L), dims=[-1]),
torch.flip(torch.transpose(x, dim0=2, dim1=3).contiguous().view(B, C, L), dims=[-1]),
], dim=1).view(B, 4, C, L)
return xs
def cross_merge(out_y: torch.Tensor):
B, K, D, H, W = out_y.shape
L = H * W
out_y = out_y.view(B, K, D, L)
inv_y = torch.flip(out_y[:, 2:4], dims=[-1]).view(B, 2, -1, L)
wh_y = torch.transpose(out_y[:, 1].view(B, -1, W, H), dim0=2, dim1=3).contiguous().view(B, -1, L)
invwh_y = torch.transpose(inv_y[:, 1].view(B, -1, W, H), dim0=2, dim1=3).contiguous().view(B, -1, L)
y = out_y[:, 0] + inv_y[:, 0] + wh_y + invwh_y
return y
def cross_scan_1b1(x: torch.Tensor):
B, K, C, H, W = x.shape
L = H * W
xs = torch.stack([
x[:, 0].view(B, C, L),
torch.transpose(x[:, 1], dim0=2, dim1=3).contiguous().view(B, C, L),
torch.flip(x[:, 2].contiguous().view(B, C, L), dims=[-1]),
torch.flip(torch.transpose(x[:, 3], dim0=2, dim1=3).contiguous().view(B, C, L), dims=[-1]),
], dim=1).view(B, 4, C, L)
return xs
def unidi_scan(x):
B, C, H, W = x.shape
x = x.view(B, 1, C, H * W).repeat(1, 4, 1, 1)
return x
def unidi_merge(ys):
B, K, C, H, W = ys.shape
return ys.view(B, 4, -1, H * W).sum(1)
def bidi_scan(x):
B, C, H, W = x.shape
x = x.view(B, 1, C, H * W).repeat(1, 2, 1, 1)
x = torch.cat([x, x.flip(dims=[-1])], dim=1)
return x
def bidi_merge(ys):
B, K, D, H, W = ys.shape
ys = ys.view(B, K, D, -1)
ys = ys[:, 0:2] + ys[:, 2:4].flip(dims=[-1]).view(B, 2, D, -1)
return ys.contiguous().sum(1)
if True:
res0 = triton.testing.do_bench(lambda :cross_scan(x))
res1 = triton.testing.do_bench(lambda :cross_scan_fn(x, True, True, False))
# res2 = triton.testing.do_bench(lambda :CrossScanTriton.apply(x))
res3 = triton.testing.do_bench(lambda :cross_merge(y))
res4 = triton.testing.do_bench(lambda :cross_merge_fn(y, True, True, False))
# res5 = triton.testing.do_bench(lambda :CrossMergeTriton.apply(y))
# print(res0, res1, res2, res3, res4, res5)
print(res0, res1, res3, res4)
res0 = triton.testing.do_bench(lambda :cross_scan(x).sum().backward())
res1 = triton.testing.do_bench(lambda :cross_scan_fn(x, True, True, False).sum().backward())
# res2 = triton.testing.do_bench(lambda :CrossScanTriton.apply(x).sum().backward())
res3 = triton.testing.do_bench(lambda :cross_merge(y).sum().backward())
res4 = triton.testing.do_bench(lambda :cross_merge_fn(y, True, True, False).sum().backward())
# res5 = triton.testing.do_bench(lambda :CrossMergeTriton.apply(y).sum().backward())
# print(res0, res1, res2, res3, res4, res5)
print(res0, res1, res3, res4)
print("test cross scan")
for (cs0, cm0, cs1, cm1) in [
# channel_first -> channel_first
(cross_scan, cross_merge, cross_scan_fn, cross_merge_fn),
(unidi_scan, unidi_merge, lambda x: cross_scan_fn(x, scans=1), lambda x: cross_merge_fn(x, scans=1)),
(bidi_scan, bidi_merge, lambda x: cross_scan_fn(x, scans=2), lambda x: cross_merge_fn(x, scans=2)),
# flex: BLC->BCL; BCL->BLC; BLC->BLC;
(cross_scan, cross_merge, lambda x: cross_scan_fn(x.permute(0, 2, 3, 1), in_channel_first=False), lambda x: cross_merge_fn(x, in_channel_first=False).permute(0, 2, 1)),
(cross_scan, cross_merge, lambda x: cross_scan_fn(x, out_channel_first=False).permute(0, 2, 3, 1), lambda x: cross_merge_fn(x.permute(0, 3, 4, 1, 2), out_channel_first=False)),
(cross_scan, cross_merge, lambda x: cross_scan_fn(x.permute(0, 2, 3, 1), in_channel_first=False, out_channel_first=False).permute(0, 2, 3, 1), lambda x: cross_merge_fn(x.permute(0, 3, 4, 1, 2), in_channel_first=False, out_channel_first=False).permute(0, 2, 1)),
# previous
# (cross_scan, cross_merge, lambda x: CrossScanTriton.apply(x), lambda x: CrossMergeTriton.apply(x)),
# (unidi_scan, unidi_merge, lambda x: getCSM(1)[0].apply(x), lambda x: getCSM(1)[1].apply(x)),
# (bidi_scan, bidi_merge, lambda x: getCSM(2)[0].apply(x), lambda x: getCSM(2)[1].apply(x)),
]:
x.grad, x1.grad, y.grad, y1.grad = None, None, None, None
o0 = cs0(x)
o1 = cs1(x1)
o0.backward(y.view(B, 4, C, H * W))
o1.backward(y.view(B, 4, C, H * W))
print((o0 - o1).abs().max())
print((x.grad - x1.grad).abs().max())
o0 = cm0(y)
o1 = cm1(y1)
o0.backward(x.view(B, C, H * W))
o1.backward(x.view(B, C, H * W))
print((o0 - o1).abs().max())
print((y.grad - y1.grad).abs().max())
x.grad, x1.grad, y.grad, y1.grad = None, None, None, None
print("===============", flush=True)
print("test cross scan one by one")
for (cs0, cs1) in [
(cross_scan_1b1, lambda x: cross_scan_fn(x, one_by_one=True)),
# (cross_scan_1b1, lambda x: CrossScanTriton1b1.apply(x)),
]:
o0 = cs0(y)
o1 = cs1(y1)
o0.backward(y.view(B, 4, C, H * W))
o1.backward(y.view(B, 4, C, H * W))
print((o0 - o1).abs().max())
print((y.grad - y1.grad).abs().max())
x.grad, x1.grad, y.grad, y1.grad = None, None, None, None
print("===============", flush=True)
if __name__ == "__main__":
CHECK.check_csm_triton()
csm_tritonk2.py
import torch
import warnings
import os
WITH_TRITON = True
# WITH_TRITON = False
try:
import triton
import triton.language as tl
except:
WITH_TRITON = False
# warnings.warn("Triton not installed, fall back to pytorch implements.")
pass
# to make sure cached_property can be loaded for triton
if WITH_TRITON:
try:
from functools import cached_property
except:
# warnings.warn("if you are using py37, add this line to functools.py: "
# "cached_property = lambda func: property(lru_cache()(func))")
pass
# torch implementation ========================================
def cross_scan_fwd(x: torch.Tensor, in_channel_first=True, out_channel_first=True, scans=2):
if in_channel_first:
B, C, H, W = x.shape
if scans == 0:
y = x.new_empty((B, 4, C, H * W))
y[:, 0, :, :] = x.flatten(2, 3)
y[:, 1, :, :] = x.transpose(dim0=2, dim1=3).flatten(2, 3)
y[:, 2:4, :, :] = torch.flip(y[:, 0:2, :, :], dims=[-1])
elif scans == 1:
y = x.view(B, 1, C, H * W).repeat(1, 2, 1, 1)
elif scans == 2:
y = x.view(B, 1, C, H * W)
y = torch.cat([y, y.flip(dims=[-1])], dim=1)
else:
B, H, W, C = x.shape
if scans == 0:
y = x.new_empty((B, H * W, 4, C))
y[:, :, 0, :] = x.flatten(1, 2)
y[:, :, 1, :] = x.transpose(dim0=1, dim1=2).flatten(1, 2)
y[:, :, 2:4, :] = torch.flip(y[:, :, 0:2, :], dims=[1])
elif scans == 1:
y = x.view(B, H * W, 1, C).repeat(1, 1, 2, 1)
elif scans == 2:
y = x.view(B, H * W, 1, C)
y = torch.cat([y, y.flip(dims=[1])], dim=2)
if in_channel_first and (not out_channel_first):
y = y.permute(0, 3, 1, 2).contiguous()
elif (not in_channel_first) and out_channel_first:
y = y.permute(0, 2, 3, 1).contiguous()
return y
def cross_merge_fwd(y: torch.Tensor, in_channel_first=True, out_channel_first=True, scans=2):
if out_channel_first:
B, K, D, H, W = y.shape
y = y.view(B, K, D, -1)
if scans == 0:
y = y[:, 0:2] + y[:, 2:4].flip(dims=[-1]).view(B, 2, D, -1)
y = y[:, 0] + y[:, 1].view(B, -1, W, H).transpose(dim0=2, dim1=3).contiguous().view(B, D, -1)
elif scans == 1:
y = y.sum(1)
elif scans == 2:
y = y[:, 0] + y[:, 1].flip(dims=[-1]).view(B, 1, D, -1)
y = y.sum(1)
else:
B, H, W, K, D = y.shape
y = y.view(B, -1, K, D)
if scans == 0:
y = y[:, :, 0:2] + y[:, :, 2:4].flip(dims=[1]).view(B, -1, 2, D)
y = y[:, :, 0] + y[:, :, 1].view(B, W, H, -1).transpose(dim0=1, dim1=2).contiguous().view(B, -1, D)
elif scans == 1:
y = y.sum(2)
elif scans == 2:
y = y[:, :, 0] + y[:, :, 1].flip(dims=[1]).view(B, -1, 1, D)
y = y.sum(2)
if in_channel_first and (not out_channel_first):
y = y.permute(0, 2, 1).contiguous()
elif (not in_channel_first) and out_channel_first:
y = y.permute(0, 2, 1).contiguous()
return y
def cross_scan1b1_fwd(x: torch.Tensor, in_channel_first=True, out_channel_first=True, scans=2):
if in_channel_first:
B, _, C, H, W = x.shape
if scans == 0:
y = torch.stack([
x[:, 0].flatten(2, 3),
x[:, 1].transpose(dim0=2, dim1=3).flatten(2, 3),
torch.flip(x[:, 2].flatten(2, 3), dims=[-1]),
torch.flip(x[:, 3].transpose(dim0=2, dim1=3).flatten(2, 3), dims=[-1]),
], dim=1)
elif scans == 1:
y = x.flatten(2, 3)
elif scans == 2:
y = torch.stack([
x[:, 0].flatten(2, 3),
x[:, 1].flatten(2, 3),
torch.flip(x[:, 2].flatten(2, 3), dims=[-1]),
torch.flip(x[:, 3].flatten(2, 3), dims=[-1]),
], dim=1)
else:
B, H, W, _, C = x.shape
if scans == 0:
y = torch.stack([
x[:, :, :, 0].flatten(1, 2),
x[:, :, :, 1].transpose(dim0=1, dim1=2).flatten(1, 2),
torch.flip(x[:, :, :, 2].flatten(1, 2), dims=[1]),
torch.flip(x[:, :, :, 3].transpose(dim0=1, dim1=2).flatten(1, 2), dims=[1]),
], dim=2)
elif scans == 1:
y = x.flatten(1, 2)
elif scans == 2:
y = torch.stack([
x[:, 0].flatten(1, 2),
x[:, 1].flatten(1, 2),
torch.flip(x[:, 2].flatten(1, 2), dims=[-1]),
torch.flip(x[:, 3].flatten(1, 2), dims=[-1]),
], dim=2)
if in_channel_first and (not out_channel_first):
y = y.permute(0, 3, 1, 2).contiguous()
elif (not in_channel_first) and out_channel_first:
y = y.permute(0, 2, 3, 1).contiguous()
return y
def cross_merge1b1_fwd(y: torch.Tensor, in_channel_first=True, out_channel_first=True, scans=2):
if out_channel_first:
B, K, D, H, W = y.shape
y = y.view(B, K, D, -1)
if scans == 0:
y = torch.stack([
y[:, 0],
y[:, 1].view(B, -1, W, H).transpose(dim0=2, dim1=3).flatten(2, 3),
torch.flip(y[:, 2], dims=[-1]),
torch.flip(y[:, 3].view(B, -1, W, H).transpose(dim0=2, dim1=3).flatten(2, 3), dims=[-1]),
], dim=1)
elif scans == 1:
y = y
elif scans == 2:
y = torch.stack([
y[:, 0],
y[:, 1],
torch.flip(y[:, 2], dims=[-1]),
torch.flip(y[:, 3], dims=[-1]),
], dim=1)
else:
B, H, W, _, D = y.shape
y = y.view(B, -1, 2, D)
if scans == 0:
y = torch.stack([
y[:, :, 0],
y[:, :, 1].view(B, W, H, -1).transpose(dim0=1, dim1=2).flatten(1, 2),
torch.flip(y[:, :, 2], dims=[1]),
torch.flip(y[:, :, 3].view(B, W, H, -1).transpose(dim0=1, dim1=2).flatten(1, 2), dims=[1]),
], dim=2)
elif scans == 1:
y = y
elif scans == 2:
y = torch.stack([
y[:, :, 0],
y[:, :, 1],
torch.flip(y[:, :, 2], dims=[1]),
torch.flip(y[:, :, 3], dims=[1]),
], dim=2)
if out_channel_first and (not in_channel_first):
y = y.permute(0, 3, 1, 2).contiguous()
elif (not out_channel_first) and in_channel_first:
y = y.permute(0, 2, 3, 1).contiguous()
return y
class CrossScan(torch.nn.Module):
def __init__(self, in_channel_first=True, out_channel_first=True, one_by_one=False, scans=2):
super(CrossScan, self).__init__()
self.in_channel_first = in_channel_first
self.out_channel_first = out_channel_first
self.one_by_one = one_by_one
self.scans = scans
def forward(self, x: torch.Tensor):
if self.one_by_one:
B, K, C, H, W = x.shape
if not self.in_channel_first:
B, H, W, K, C = x.shape
else:
B, C, H, W = x.shape
if not self.in_channel_first:
B, H, W, C = x.shape
self.shape = (B, C, H, W)
_fn = cross_scan1b1_fwd if self.one_by_one else cross_scan_fwd
y = _fn(x, self.in_channel_first, self.out_channel_first, self.scans)
return y
def backward(self, ys: torch.Tensor):
B, C, H, W = self.shape
ys = ys.view(B, -1, C, H, W) if self.out_channel_first else ys.view(B, H, W, -1, C)
_fn = cross_merge1b1_fwd if self.one_by_one else cross_merge_fwd
y = _fn(ys, self.in_channel_first, self.out_channel_first, self.scans)
if self.one_by_one:
y = y.view(B, 2, -1, H, W) if self.in_channel_first else y.view(B, H, W, 2, -1)
else:
y = y.view(B, -1, H, W) if self.in_channel_first else y.view(B, H, W, -1)
return y
class CrossMerge(torch.nn.Module):
def __init__(self, in_channel_first=True, out_channel_first=True, one_by_one=False, scans=2):
super(CrossMerge, self).__init__()
self.in_channel_first = in_channel_first
self.out_channel_first = out_channel_first
self.one_by_one = one_by_one
self.scans = scans
def forward(self, ys: torch.Tensor):
B, K, C, H, W = ys.shape
if not self.out_channel_first:
B, H, W, K, C = ys.shape
self.shape = (B, C, H, W)
_fn = cross_merge1b1_fwd if self.one_by_one else cross_merge_fwd
y = _fn(ys, self.in_channel_first, self.out_channel_first, self.scans)
return y
def backward(self, x: torch.Tensor):
B, C, H, W = self.shape
if not self.one_by_one:
if self.in_channel_first:
x = x.view(B, C, H, W)
else:
x = x.view(B, H, W, C)
else:
if self.in_channel_first:
x = x.view(B, 2, C, H, W)
else:
x = x.view(B, H, W, 2, C)
_fn = cross_scan1b1_fwd if self.one_by_one else cross_scan_fwd
x = _fn(x, self.in_channel_first, self.out_channel_first, self.scans)
x = x.view(B, 2, C, H, W) if self.out_channel_first else x.view(B, H, W, 2, C)
return x
class CrossScanF(torch.autograd.Function):
@staticmethod
def forward(ctx, x: torch.Tensor, in_channel_first=True, out_channel_first=True, one_by_one=False, scans=2):
# x: (B, C, H, W) | (B, H, W, C) | (B, 4, C, H, W) | (B, H, W, 2, C)
# y: (B, 2, C, H * W) | (B, H * W, 2, C)
ctx.in_channel_first = in_channel_first
ctx.out_channel_first = out_channel_first
ctx.one_by_one = one_by_one
ctx.scans = scans
if one_by_one:
B, K, C, H, W = x.shape
if not in_channel_first:
B, H, W, K, C = x.shape
else:
B, C, H, W = x.shape
if not in_channel_first:
B, H, W, C = x.shape
ctx.shape = (B, C, H, W)
_fn = cross_scan1b1_fwd if one_by_one else cross_scan_fwd
y = _fn(x, in_channel_first, out_channel_first, scans)
return y
@staticmethod
def backward(ctx, ys: torch.Tensor):
# out: (b, k, d, l)
in_channel_first = ctx.in_channel_first
out_channel_first = ctx.out_channel_first
one_by_one = ctx.one_by_one
scans = ctx.scans
B, C, H, W = ctx.shape
ys = ys.view(B, -1, C, H, W) if out_channel_first else ys.view(B, H, W, -1, C)
_fn = cross_merge1b1_fwd if one_by_one else cross_merge_fwd
y = _fn(ys, in_channel_first, out_channel_first, scans)
if one_by_one:
y = y.view(B, 2, -1, H, W) if in_channel_first else y.view(B, H, W, 2, -1)
else:
y = y.view(B, -1, H, W) if in_channel_first else y.view(B, H, W, -1)
return y, None, None, None, None
class CrossMergeF(torch.autograd.Function):
@staticmethod
def forward(ctx, ys: torch.Tensor, in_channel_first=True, out_channel_first=True, one_by_one=False, scans=2):
# x: (B, C, H, W) | (B, H, W, C) | (B, 2, C, H, W) | (B, H, W, 2, C)
# y: (B, 2, C, H * W) | (B, H * W, 4, C)
ctx.in_channel_first = in_channel_first
ctx.out_channel_first = out_channel_first
ctx.one_by_one = one_by_one
ctx.scans = scans
B, K, C, H, W = ys.shape
if not out_channel_first:
B, H, W, K, C = ys.shape
ctx.shape = (B, C, H, W)
_fn = cross_merge1b1_fwd if one_by_one else cross_merge_fwd
y = _fn(ys, in_channel_first, out_channel_first, scans)
return y
@staticmethod
def backward(ctx, x: torch.Tensor):
# B, D, L = x.shape
# out: (b, k, d, h, w)
in_channel_first = ctx.in_channel_first
out_channel_first = ctx.out_channel_first
one_by_one = ctx.one_by_one
scans = ctx.scans
B, C, H, W = ctx.shape
if not one_by_one:
if in_channel_first:
x = x.view(B, C, H, W)
else:
x = x.view(B, H, W, C)
else:
if in_channel_first:
x = x.view(B, 2, C, H, W)
else:
x = x.view(B, H, W, 2, C)
_fn = cross_scan1b1_fwd if one_by_one else cross_scan_fwd
x = _fn(x, in_channel_first, out_channel_first, scans)
x = x.view(B, 2, C, H, W) if out_channel_first else x.view(B, H, W, 2, C)
return x, None, None, None, None
# triton implements ========================================
try:
@triton.jit
def triton_cross_scan_flex_k2(
x, # (B, C, H, W) | (B, H, W, C) | (B, 4, C, H, W) | (B, H, W, 4, C)
y, # (B, 4, C, H, W) | (B, H, W, 4, C)
x_layout: tl.constexpr,
y_layout: tl.constexpr,
operation: tl.constexpr,
onebyone: tl.constexpr,
scans: tl.constexpr,
BC: tl.constexpr,
BH: tl.constexpr,
BW: tl.constexpr,
DC: tl.constexpr,
DH: tl.constexpr,
DW: tl.constexpr,
NH: tl.constexpr,
NW: tl.constexpr,
):
# x_layout = 0
# y_layout = 1 # 0 BCHW, 1 BHWC
# operation = 0 # 0 scan, 1 merge
# onebyone = 0 # 0 false, 1 true
# scans = 0 # 0 cross scan, 1 unidirectional, 2 bidirectional
i_hw, i_c, i_b = tl.program_id(0), tl.program_id(1), tl.program_id(2)
i_h, i_w = (i_hw // NW), (i_hw % NW)
_mask_h = (i_h * BH + tl.arange(0, BH)) < DH
_mask_w = (i_w * BW + tl.arange(0, BW)) < DW
_mask_hw = _mask_h[:, None] & _mask_w[None, :]
_for_C = min(DC - i_c * BC, BC)
HWRoute0 = i_h * BH * DW + tl.arange(0, BH)[:, None] * DW + i_w * BW + tl.arange(0, BW)[None, :]
# HWRoute1 = i_w * BW * DH + tl.arange(0, BW)[None, :] * DH + i_h * BH + tl.arange(0, BH)[:, None] # trans
HWRoute2 = (NH - i_h - 1) * BH * DW + (BH - 1 - tl.arange(0, BH)[:, None]) * DW + (NW - i_w - 1) * BW + (BW - 1 - tl.arange(0, BW)[None, :]) + (DH - NH * BH) * DW + (DW - NW * BW) # flip
# HWRoute3 = (NW - i_w - 1) * BW * DH + (BW - 1 - tl.arange(0, BW)[None, :]) * DH + (NH - i_h - 1) * BH + (BH - 1 - tl.arange(0, BH)[:, None]) + (DH - NH * BH) + (DW - NW * BW) * DH # trans + flip
if scans == 1:
HWRoute2 = HWRoute0
_tmp1 = DC * DH * DW
y_ptr_base = y + i_b * 4 * _tmp1 + (i_c * BC * DH * DW if y_layout == 0 else i_c * BC)
if y_layout == 0:
p_y1 = y_ptr_base + HWRoute0
# p_y2 = y_ptr_base + _tmp1 + HWRoute1
p_y3 = y_ptr_base + 2 * _tmp1 + HWRoute2
# p_y4 = y_ptr_base + 3 * _tmp1 + HWRoute3
else:
p_y1 = y_ptr_base + HWRoute0 * 4 * DC
# p_y2 = y_ptr_base + DC + HWRoute1 * 4 * DC
p_y3 = y_ptr_base + 2 * DC + HWRoute2 * 4 * DC
# p_y4 = y_ptr_base + 3 * DC + HWRoute3 * 4 * DC
if onebyone == 0:
x_ptr_base = x + i_b * _tmp1 + (i_c * BC * DH * DW if x_layout == 0 else i_c * BC)
if x_layout == 0:
p_x = x_ptr_base + HWRoute0
else:
p_x = x_ptr_base + HWRoute0 * DC
if operation == 0:
for idxc in range(_for_C):
_idx_x = idxc * DH * DW if x_layout == 0 else idxc
_idx_y = idxc * DH * DW if y_layout == 0 else idxc
_x = tl.load(p_x + _idx_x, mask=_mask_hw)
tl.store(p_y1 + _idx_y, _x, mask=_mask_hw)
# tl.store(p_y2 + _idx_y, _x, mask=_mask_hw)
tl.store(p_y3 + _idx_y, _x, mask=_mask_hw)
# tl.store(p_y4 + _idx_y, _x, mask=_mask_hw)
elif operation == 1:
for idxc in range(_for_C):
_idx_x = idxc * DH * DW if x_layout == 0 else idxc
_idx_y = idxc * DH * DW if y_layout == 0 else idxc
_y1 = tl.load(p_y1 + _idx_y, mask=_mask_hw)
# _y2 = tl.load(p_y2 + _idx_y, mask=_mask_hw)
_y3 = tl.load(p_y3 + _idx_y, mask=_mask_hw)
# _y4 = tl.load(p_y4 + _idx_y, mask=_mask_hw)
# tl.store(p_x + _idx_x, _y1 + _y2 + _y3 + _y4, mask=_mask_hw)
tl.store(p_x + _idx_x, _y1 + _y3, mask=_mask_hw)
else:
x_ptr_base = x + i_b * 4 * _tmp1 + (i_c * BC * DH * DW if x_layout == 0 else i_c * BC)
if x_layout == 0:
p_x1 = x_ptr_base + HWRoute0
p_x2 = p_x1 + _tmp1
p_x3 = p_x2 + _tmp1
p_x4 = p_x3 + _tmp1
else:
p_x1 = x_ptr_base + HWRoute0 * 4 * DC
p_x2 = p_x1 + DC
p_x3 = p_x2 + DC
p_x4 = p_x3 + DC
if operation == 0:
for idxc in range(_for_C):
_idx_x = idxc * DH * DW if x_layout == 0 else idxc
_idx_y = idxc * DH * DW if y_layout == 0 else idxc
tl.store(p_y1 + _idx_y, tl.load(p_x1 + _idx_x, mask=_mask_hw), mask=_mask_hw)
# tl.store(p_y2 + _idx_y, tl.load(p_x2 + _idx_x, mask=_mask_hw), mask=_mask_hw)
tl.store(p_y3 + _idx_y, tl.load(p_x3 + _idx_x, mask=_mask_hw), mask=_mask_hw)
# tl.store(p_y4 + _idx_y, tl.load(p_x4 + _idx_x, mask=_mask_hw), mask=_mask_hw)
else:
for idxc in range(_for_C):
_idx_x = idxc * DH * DW if x_layout == 0 else idxc
_idx_y = idxc * DH * DW if y_layout == 0 else idxc
tl.store(p_x1 + _idx_x, tl.load(p_y1 + _idx_y), mask=_mask_hw)
# tl.store(p_x2 + _idx_x, tl.load(p_y2 + _idx_y), mask=_mask_hw)
tl.store(p_x3 + _idx_x, tl.load(p_y3 + _idx_y), mask=_mask_hw)
# tl.store(p_x4 + _idx_x, tl.load(p_y4 + _idx_y), mask=_mask_hw)
@triton.jit
def triton_cross_scan_flex_k2(
x, # (B, C, H, W) | (B, H, W, C) | (B, 4, C, H, W) | (B, H, W, 4, C)
y, # (B, 4, C, H, W) | (B, H, W, 4, C)
x_layout: tl.constexpr,
y_layout: tl.constexpr,
operation: tl.constexpr,
onebyone: tl.constexpr,
scans: tl.constexpr,
BC: tl.constexpr,
BH: tl.constexpr,
BW: tl.constexpr,
DC: tl.constexpr,
DH: tl.constexpr,
DW: tl.constexpr,
NH: tl.constexpr,
NW: tl.constexpr,
):
i_hw, i_c, i_b = tl.program_id(0), tl.program_id(1), tl.program_id(2)
i_h, i_w = (i_hw // NW), (i_hw % NW)
_mask_h = (i_h * BH + tl.arange(0, BH)) < DH
_mask_w = (i_w * BW + tl.arange(0, BW)) < DW
_mask_hw = _mask_h[:, None] & _mask_w[None, :]
_for_C = min(DC - i_c * BC, BC)
HWRoute0 = i_h * BH * DW + tl.arange(0, BH)[:, None] * DW + i_w * BW + tl.arange(0, BW)[None, :]
HWRoute2 = (NH - i_h - 1) * BH * DW + (BH - 1 - tl.arange(0, BH)[:, None]) * DW + (NW - i_w - 1) * BW + (BW - 1 - tl.arange(0, BW)[None, :]) + (DH - NH * BH) * DW + (DW - NW * BW) # flip
if scans == 1:
HWRoute2 = HWRoute0
_tmp1 = DC * DH * DW
y_ptr_base = y + i_b * 4 * _tmp1 + (i_c * BC * DH * DW if y_layout == 0 else i_c * BC)
if y_layout == 0:
p_y1 = y_ptr_base + HWRoute0
p_y2 = y_ptr_base + 2 * _tmp1 + HWRoute2
else:
p_y1 = y_ptr_base + HWRoute0 * 4 * DC
p_y2 = y_ptr_base + 2 * DC + HWRoute2 * 4 * DC
if onebyone == 0:
x_ptr_base = x + i_b * _tmp1 + (i_c * BC * DH * DW if x_layout == 0 else i_c * BC)
if x_layout == 0:
p_x = x_ptr_base + HWRoute0
else:
p_x = x_ptr_base + HWRoute0 * DC
if operation == 0:
for idxc in range(_for_C):
_idx_x = idxc * DH * DW if x_layout == 0 else idxc
_idx_y = idxc * DH * DW if y_layout == 0 else idxc
_x = tl.load(p_x + _idx_x, mask=_mask_hw)
tl.store(p_y1 + _idx_y, _x, mask=_mask_hw)
tl.store(p_y2 + _idx_y, _x, mask=_mask_hw)
elif operation == 1:
for idxc in range(_for_C):
_idx_x = idxc * DH * DW if x_layout == 0 else idxc
_idx_y = idxc * DH * DW if y_layout == 0 else idxc
_y1 = tl.load(p_y1 + _idx_y, mask=_mask_hw)
_y2 = tl.load(p_y2 + _idx_y, mask=_mask_hw)
tl.store(p_x + _idx_x, _y1 + _y2, mask=_mask_hw)
else:
x_ptr_base = x + i_b * 4 * _tmp1 + (i_c * BC * DH * DW if x_layout == 0 else i_c * BC)
if x_layout == 0:
p_x1 = x_ptr_base + HWRoute0
p_x2 = p_x1 + 2 * _tmp1
else:
p_x1 = x_ptr_base + HWRoute0 * 4 * DC
p_x2 = p_x1 + 2 * DC
if operation == 0:
for idxc in range(_for_C):
_idx_x = idxc * DH * DW if x_layout == 0 else idxc
_idx_y = idxc * DH * DW if y_layout == 0 else idxc
tl.store(p_y1 + _idx_y, tl.load(p_x1 + _idx_x, mask=_mask_hw), mask=_mask_hw)
tl.store(p_y2 + _idx_y, tl.load(p_x2 + _idx_x, mask=_mask_hw), mask=_mask_hw)
else:
for idxc in range(_for_C):
_idx_x = idxc * DH * DW if x_layout == 0 else idxc
_idx_y = idxc * DH * DW if y_layout == 0 else idxc
tl.store(p_x1 + _idx_x, tl.load(p_y1 + _idx_y), mask=_mask_hw)
tl.store(p_x2 + _idx_x, tl.load(p_y2 + _idx_y), mask=_mask_hw)
@triton.jit
def triton_cross_scan_flex_k2(
x, # (B, C, H, W) | (B, H, W, C) | (B, 4, C, H, W) | (B, H, W, 4, C)
y, # (B, 4, C, H, W) | (B, H, W, 4, C)
x_layout: tl.constexpr,
y_layout: tl.constexpr,
operation: tl.constexpr,
onebyone: tl.constexpr,
scans: tl.constexpr,
BC: tl.constexpr,
BH: tl.constexpr,
BW: tl.constexpr,
DC: tl.constexpr,
DH: tl.constexpr,
DW: tl.constexpr,
NH: tl.constexpr,
NW: tl.constexpr,
):
i_hw, i_c, i_b = tl.program_id(0), tl.program_id(1), tl.program_id(2)
i_h, i_w = (i_hw // NW), (i_hw % NW)
_mask_h = (i_h * BH + tl.arange(0, BH)) < DH
_mask_w = (i_w * BW + tl.arange(0, BW)) < DW
_mask_hw = _mask_h[:, None] & _mask_w[None, :]
_for_C = min(DC - i_c * BC, BC)
HWRoute0 = i_h * BH * DW + tl.arange(0, BH)[:, None] * DW + i_w * BW + tl.arange(0, BW)[None, :]
HWRoute2 = (NH - i_h - 1) * BH * DW + (BH - 1 - tl.arange(0, BH)[:, None]) * DW + (NW - i_w - 1) * BW + (BW - 1 - tl.arange(0, BW)[None, :]) + (DH - NH * BH) * DW + (DW - NW * BW) # flip
if scans == 1:
HWRoute2 = HWRoute0
_tmp1 = DC * DH * DW
y_ptr_base = y + i_b * 2 * _tmp1 + (i_c * BC * DH * DW if y_layout == 0 else i_c * BC)
if y_layout == 0:
p_y1 = y_ptr_base + HWRoute0
p_y2 = y_ptr_base + 1 * _tmp1 + HWRoute2
else:
p_y1 = y_ptr_base + HWRoute0 * 4 * DC
p_y2 = y_ptr_base + 1 * DC + HWRoute2 * 4 * DC
if onebyone == 0:
x_ptr_base = x + i_b * _tmp1 + (i_c * BC * DH * DW if x_layout == 0 else i_c * BC)
if x_layout == 0:
p_x = x_ptr_base + HWRoute0
else:
p_x = x_ptr_base + HWRoute0 * DC
if operation == 0:
for idxc in range(_for_C):
_idx_x = idxc * DH * DW if x_layout == 0 else idxc
_idx_y = idxc * DH * DW if y_layout == 0 else idxc
_x = tl.load(p_x + _idx_x, mask=_mask_hw)
tl.store(p_y1 + _idx_y, _x, mask=_mask_hw)
tl.store(p_y2 + _idx_y, _x, mask=_mask_hw)
elif operation == 1:
for idxc in range(_for_C):
_idx_x = idxc * DH * DW if x_layout == 0 else idxc
_idx_y = idxc * DH * DW if y_layout == 0 else idxc
_y1 = tl.load(p_y1 + _idx_y, mask=_mask_hw)
_y2 = tl.load(p_y2 + _idx_y, mask=_mask_hw)
tl.store(p_x + _idx_x, _y1 + _y2, mask=_mask_hw)
else:
x_ptr_base = x + i_b * 4 * _tmp1 + (i_c * BC * DH * DW if x_layout == 0 else i_c * BC)
if x_layout == 0:
p_x1 = x_ptr_base + HWRoute0
p_x2 = p_x1 + 2 * _tmp1
else:
p_x1 = x_ptr_base + HWRoute0 * 4 * DC
p_x2 = p_x1 + 2 * DC
if operation == 0:
for idxc in range(_for_C):
_idx_x = idxc * DH * DW if x_layout == 0 else idxc
_idx_y = idxc * DH * DW if y_layout == 0 else idxc
_x1 = tl.load(p_x1 + _idx_x, mask=_mask_hw)
_x2 = tl.load(p_x2 + _idx_x, mask=_mask_hw)
tl.store(p_y1 + _idx_y, _x1, mask=_mask_hw)
tl.store(p_y2 + _idx_y, _x2, mask=_mask_hw)
else:
for idxc in range(_for_C):
_idx_x = idxc * DH * DW if x_layout == 0 else idxc
_idx_y = idxc * DH * DW if y_layout == 0 else idxc
_y1 = tl.load(p_y1 + _idx_y, mask=_mask_hw)
_y2 = tl.load(p_y2 + _idx_y, mask=_mask_hw)
tl.store(p_x1 + _idx_x, _y1, mask=_mask_hw)
tl.store(p_x2 + _idx_x, _y2, mask=_mask_hw)
except:
def triton_cross_scan_flex():
pass
class CrossScanTritonFk2(torch.autograd.Function):
@staticmethod
def forward(ctx, x: torch.Tensor, in_channel_first=True, out_channel_first=True, one_by_one=False, scans=2):
if one_by_one:
if in_channel_first:
B, _, C, H, W = x.shape
else:
B, H, W, _, C = x.shape
else:
if in_channel_first:
B, C, H, W = x.shape
else:
B, H, W, C = x.shape
B, C, H, W = int(B), int(C), int(H), int(W)
BC, BH, BW = 1, 32, 32
NH, NW, NC = triton.cdiv(H, BH), triton.cdiv(W, BW), triton.cdiv(C, BC)
ctx.in_channel_first = in_channel_first
ctx.out_channel_first = out_channel_first
ctx.one_by_one = one_by_one
ctx.scans = scans
ctx.shape = (B, C, H, W)
ctx.triton_shape = (BC, BH, BW, NC, NH, NW)
y = x.new_empty((B, 2, C, H * W)) if out_channel_first else x.new_empty((B, H * W, 2, C))
triton_cross_scan_flex_k2[(NH * NW, NC, B)](
x.contiguous(), y,
(0 if in_channel_first else 1), (0 if out_channel_first else 1), 0, (0 if not one_by_one else 1), scans,
BC, BH, BW, C, H, W, NH, NW
)
return y
@staticmethod
def backward(ctx, y: torch.Tensor):
in_channel_first = ctx.in_channel_first
out_channel_first = ctx.out_channel_first
one_by_one = ctx.one_by_one
scans = ctx.scans
B, C, H, W = ctx.shape
BC, BH, BW, NC, NH, NW = ctx.triton_shape
if one_by_one:
x = y.new_empty((B, 2, C, H, W)) if in_channel_first else y.new_empty((B, H, W, 2, C))
else:
x = y.new_empty((B, C, H, W)) if in_channel_first else y.new_empty((B, H, W, C))
triton_cross_scan_flex_k2[(NH * NW, NC, B)](
x, y.contiguous(),
(0 if in_channel_first else 1), (0 if out_channel_first else 1), 1, (0 if not one_by_one else 1), scans,
BC, BH, BW, C, H, W, NH, NW
)
return x, None, None, None, None
class CrossMergeTritonFk2(torch.autograd.Function):
@staticmethod
def forward(ctx, y: torch.Tensor, in_channel_first=True, out_channel_first=True, one_by_one=False, scans=2):
if out_channel_first:
B, _, C, H, W = y.shape
else:
B, H, W, _, C = y.shape
B, C, H, W = int(B), int(C), int(H), int(W)
BC, BH, BW = 1, 32, 32
NH, NW, NC = triton.cdiv(H, BH), triton.cdiv(W, BW), triton.cdiv(C, BC)
ctx.in_channel_first = in_channel_first
ctx.out_channel_first = out_channel_first
ctx.one_by_one = one_by_one
ctx.scans = scans
ctx.shape = (B, C, H, W)
ctx.triton_shape = (BC, BH, BW, NC, NH, NW)
if one_by_one:
x = y.new_empty((B, 2, C, H * W)) if in_channel_first else y.new_empty((B, H * W, 2, C))
else:
x = y.new_empty((B, C, H * W)) if in_channel_first else y.new_empty((B, H * W, C))
triton_cross_scan_flex_k2[(NH * NW, NC, B)](
x, y.contiguous(),
(0 if in_channel_first else 1), (0 if out_channel_first else 1), 1, (0 if not one_by_one else 1), scans,
BC, BH, BW, C, H, W, NH, NW
)
return x
@staticmethod
def backward(ctx, x: torch.Tensor):
in_channel_first = ctx.in_channel_first
out_channel_first = ctx.out_channel_first
one_by_one = ctx.one_by_one
scans = ctx.scans
B, C, H, W = ctx.shape
BC, BH, BW, NC, NH, NW = ctx.triton_shape
y = x.new_empty((B, 2, C, H, W)) if out_channel_first else x.new_empty((B, H, W, 2, C))
triton_cross_scan_flex_k2[(NH * NW, NC, B)](
x.contiguous(), y,
(0 if in_channel_first else 1), (0 if out_channel_first else 1), 0, (0 if not one_by_one else 1), scans,
BC, BH, BW, C, H, W, NH, NW
)
return y, None, None, None, None, None
# @torch.compile(options={"triton.cudagraphs": True}, fullgraph=True)
def cross_scan_fn_k2(x: torch.Tensor, in_channel_first=True, out_channel_first=True, one_by_one=False, scans=2, force_torch=False):
# x: (B, C, H, W) | (B, H, W, C) | (B, 2, C, H, W) | (B, H, W, 2, C)
# y: (B, 2, C, L) | (B, L, 2, C)
# scans: 0: cross scan; 1 unidirectional; 2: bidirectional;
CSF = CrossScanTritonFk2 if WITH_TRITON and x.is_cuda and (not force_torch) else CrossScanF
return CSF.apply(x, in_channel_first, out_channel_first, one_by_one, scans)
# @torch.compile(options={"triton.cudagraphs": True}, fullgraph=True)
def cross_merge_fn_k2(y: torch.Tensor, in_channel_first=True, out_channel_first=True, one_by_one=False, scans=2, force_torch=False):
# y: (B, 2, C, L) | (B, L, 2, C)
# x: (B, C, H * W) | (B, H * W, C) | (B, 2, C, H * W) | (B, H * W, 2, C)
# scans: 0: cross scan; 1 unidirectional; 2: bidirectional;
CMF = CrossMergeTritonFk2 if WITH_TRITON and y.is_cuda and (not force_torch) else CrossMergeF
return CMF.apply(y, in_channel_first, out_channel_first, one_by_one, scans)
def cross_scan_fn_k2_torch(x: torch.Tensor, in_channel_first=True, out_channel_first=True, one_by_one=False, scans=2, force_torch=False):
cross_scan = CrossScan(in_channel_first, out_channel_first, one_by_one, scans)
return cross_scan(x)
def cross_merge_fn_k2_torch(y: torch.Tensor, in_channel_first=True, out_channel_first=True, one_by_one=False, scans=2, force_torch=False):
cross_merge = CrossMerge(in_channel_first, out_channel_first, one_by_one, scans)
return cross_merge(y)
# checks =================================================================
class CHECK:
def check_csm_triton():
B, C, H, W = 2, 192, 56, 57
dtype=torch.float16
dtype=torch.float32
x = torch.randn((B, C, H, W), dtype=dtype, device=torch.device("cuda")).requires_grad_(True)
y = torch.randn((B, 2, C, H, W), dtype=dtype, device=torch.device("cuda")).requires_grad_(True)
x1 = x.clone().detach().requires_grad_(True)
y1 = y.clone().detach().requires_grad_(True)
def cross_scan(x: torch.Tensor):
B, C, H, W = x.shape
L = H * W
xs = torch.stack([
x.view(B, C, L),
torch.transpose(x, dim0=2, dim1=3).contiguous().view(B, C, L),
torch.flip(x.contiguous().view(B, C, L), dims=[-1]),
torch.flip(torch.transpose(x, dim0=2, dim1=3).contiguous().view(B, C, L), dims=[-1]),
], dim=1).view(B, 4, C, L)
return xs
def cross_merge(out_y: torch.Tensor):
B, K, D, H, W = out_y.shape
L = H * W
out_y = out_y.view(B, K, D, L)
inv_y = torch.flip(out_y[:, 2:4], dims=[-1]).view(B, 2, -1, L)
wh_y = torch.transpose(out_y[:, 1].view(B, -1, W, H), dim0=2, dim1=3).contiguous().view(B, -1, L)
invwh_y = torch.transpose(inv_y[:, 1].view(B, -1, W, H), dim0=2, dim1=3).contiguous().view(B, -1, L)
y = out_y[:, 0] + inv_y[:, 0] + wh_y + invwh_y
return y
def cross_scan_1b1(x: torch.Tensor):
B, K, C, H, W = x.shape
L = H * W
xs = torch.stack([
x[:, 0].view(B, C, L),
torch.transpose(x[:, 1], dim0=2, dim1=3).contiguous().view(B, C, L),
torch.flip(x[:, 2].contiguous().view(B, C, L), dims=[-1]),
torch.flip(torch.transpose(x[:, 3], dim0=2, dim1=3).contiguous().view(B, C, L), dims=[-1]),
], dim=1).view(B, 2, C, L)
return xs
def unidi_scan(x):
B, C, H, W = x.shape
x = x.view(B, 1, C, H * W).repeat(1, 4, 1, 1)
return x
def unidi_merge(ys):
B, K, C, H, W = ys.shape
return ys.view(B, 4, -1, H * W).sum(1)
def bidi_scan(x):
B, C, H, W = x.shape
x = x.view(B, 1, C, H * W).repeat(1, 2, 1, 1)
x = torch.cat([x, x.flip(dims=[-1])], dim=1)
return x
def bidi_merge(ys):
B, K, D, H, W = ys.shape
ys = ys.view(B, K, D, -1)
ys = ys[:, 0:2] + ys[:, 2:4].flip(dims=[-1]).view(B, 2, D, -1)
return ys.contiguous().sum(1)
if True:
# res0 = triton.testing.do_bench(lambda :cross_scan(x))
res1 = triton.testing.do_bench(lambda :cross_scan_fn_k2(x, True, True, False))
# res2 = triton.testing.do_bench(lambda :CrossScanTriton.apply(x))
# res3 = triton.testing.do_bench(lambda :cross_merge(y))
res4 = triton.testing.do_bench(lambda :cross_merge_fn_k2(y, True, True, False))
# res5 = triton.testing.do_bench(lambda :CrossMergeTriton.apply(y))
# print(res0, res1, res2, res3, res4, res5)
print(res0, res1, res3, res4)
res0 = triton.testing.do_bench(lambda :cross_scan(x).sum().backward())
res1 = triton.testing.do_bench(lambda :cross_scan_fn_k2(x, True, True, False).sum().backward())
# res2 = triton.testing.do_bench(lambda :CrossScanTriton.apply(x).sum().backward())
res3 = triton.testing.do_bench(lambda :cross_merge(y).sum().backward())
res4 = triton.testing.do_bench(lambda :cross_merge_fn_k2(y, True, True, False).sum().backward())
# res5 = triton.testing.do_bench(lambda :CrossMergeTriton.apply(y).sum().backward())
# print(res0, res1, res2, res3, res4, res5)
print(res0, res1, res3, res4)
print("test cross scan")
for (cs0, cm0, cs1, cm1) in [
# channel_first -> channel_first
(cross_scan, cross_merge, cross_scan_fn_k2, cross_merge_fn_k2),
(unidi_scan, unidi_merge, lambda x: cross_scan_fn_k2(x, scans=1), lambda x: cross_merge_fn_k2(x, scans=1)),
(bidi_scan, bidi_merge, lambda x: cross_scan_fn_k2(x, scans=2), lambda x: cross_merge_fn_k2(x, scans=2)),
# flex: BLC->BCL; BCL->BLC; BLC->BLC;
(cross_scan, cross_merge, lambda x: cross_scan_fn_k2(x.permute(0, 2, 3, 1), in_channel_first=False), lambda x: cross_merge_fn_k2(x, in_channel_first=False).permute(0, 2, 1)),
(cross_scan, cross_merge, lambda x: cross_scan_fn_k2(x, out_channel_first=False).permute(0, 2, 3, 1), lambda x: cross_merge_fn_k2(x.permute(0, 3, 4, 1, 2), out_channel_first=False)),
(cross_scan, cross_merge, lambda x: cross_scan_fn_k2(x.permute(0, 2, 3, 1), in_channel_first=False, out_channel_first=False).permute(0, 2, 3, 1), lambda x: cross_merge_fn_k2(x.permute(0, 3, 4, 1, 2), in_channel_first=False, out_channel_first=False).permute(0, 2, 1)),
# previous
# (cross_scan, cross_merge, lambda x: CrossScanTriton.apply(x), lambda x: CrossMergeTriton.apply(x)),
# (unidi_scan, unidi_merge, lambda x: getCSM(1)[0].apply(x), lambda x: getCSM(1)[1].apply(x)),
# (bidi_scan, bidi_merge, lambda x: getCSM(2)[0].apply(x), lambda x: getCSM(2)[1].apply(x)),
]:
x.grad, x1.grad, y.grad, y1.grad = None, None, None, None
o0 = cs0(x)
o1 = cs1(x1)
o0.backward(y.view(B, 2, C, H * W))
o1.backward(y.view(B, 2, C, H * W))
print((o0 - o1).abs().max())
print((x.grad - x1.grad).abs().max())
o0 = cm0(y)
o1 = cm1(y1)
o0.backward(x.view(B, C, H * W))
o1.backward(x.view(B, C, H * W))
print((o0 - o1).abs().max())
print((y.grad - y1.grad).abs().max())
x.grad, x1.grad, y.grad, y1.grad = None, None, None, None
print("===============", flush=True)
print("test cross scan one by one")
for (cs0, cs1) in [
(cross_scan_1b1, lambda x: cross_scan_fn_k2(x, one_by_one=True)),
# (cross_scan_1b1, lambda x: CrossScanTriton1b1.apply(x)),
]:
o0 = cs0(y)
o1 = cs1(y1)
o0.backward(y.view(B, 2, C, H * W))
o1.backward(y.view(B, 2, C, H * W))
print((o0 - o1).abs().max())
print((y.grad - y1.grad).abs().max())
x.grad, x1.grad, y.grad, y1.grad = None, None, None, None
print("===============", flush=True)
if __name__ == "__main__":
CHECK.check_csm_triton()
csms6s.py
import time
import torch
import warnings
WITH_SELECTIVESCAN_OFLEX = True
WITH_SELECTIVESCAN_CORE = False
WITH_SELECTIVESCAN_MAMBA = True
try:
import selective_scan_cuda_oflex
except ImportError:
WITH_SELECTIVESCAN_OFLEX = False
# warnings.warn("Can not import selective_scan_cuda_oflex. This affects speed.")
# print("Can not import selective_scan_cuda_oflex. This affects speed.", flush=True)
try:
import selective_scan_cuda_core
except ImportError:
WITH_SELECTIVESCAN_CORE = False
try:
import selective_scan_cuda
except ImportError:
WITH_SELECTIVESCAN_MAMBA = False
def selective_scan_torch(
u: torch.Tensor, # (B, K * C, L)
delta: torch.Tensor, # (B, K * C, L)
A: torch.Tensor, # (K * C, N)
B: torch.Tensor, # (B, K, N, L)
C: torch.Tensor, # (B, K, N, L)
D: torch.Tensor = None, # (K * C)
delta_bias: torch.Tensor = None, # (K * C)
delta_softplus=True,
oflex=True,
*args,
**kwargs
):
dtype_in = u.dtype
Batch, K, N, L = B.shape
KCdim = u.shape[1]
Cdim = int(KCdim / K)
assert u.shape == (Batch, KCdim, L)
assert delta.shape == (Batch, KCdim, L)
assert A.shape == (KCdim, N)
assert C.shape == B.shape
if delta_bias is not None:
delta = delta + delta_bias[..., None]
if delta_softplus:
delta = torch.nn.functional.softplus(delta)
u, delta, A, B, C = u.float(), delta.float(), A.float(), B.float(), C.float()
B = B.view(Batch, K, 1, N, L).repeat(1, 1, Cdim, 1, 1).view(Batch, KCdim, N, L)
C = C.view(Batch, K, 1, N, L).repeat(1, 1, Cdim, 1, 1).view(Batch, KCdim, N, L)
deltaA = torch.exp(torch.einsum('bdl,dn->bdln', delta, A))
deltaB_u = torch.einsum('bdl,bdnl,bdl->bdln', delta, B, u)
if True:
x = A.new_zeros((Batch, KCdim, N))
ys = []
for i in range(L):
x = deltaA[:, :, i, :] * x + deltaB_u[:, :, i, :]
y = torch.einsum('bdn,bdn->bd', x, C[:, :, :, i])
ys.append(y)
y = torch.stack(ys, dim=2) # (B, C, L)
out = y if D is None else y + u * D.unsqueeze(-1)
return out if oflex else out.to(dtype=dtype_in)
class SelectiveScanCuda(torch.autograd.Function):
@staticmethod
@torch.cuda.amp.custom_fwd
def forward(ctx, u, delta, A, B, C, D=None, delta_bias=None, delta_softplus=False, oflex=True, backend=None):
ctx.delta_softplus = delta_softplus
backend = "oflex" if WITH_SELECTIVESCAN_OFLEX and (backend is None) else backend
backend = "core" if WITH_SELECTIVESCAN_CORE and (backend is None) else backend
backend = "mamba" if WITH_SELECTIVESCAN_MAMBA and (backend is None) else backend
ctx.backend = backend
if backend == "oflex":
out, x, *rest = selective_scan_cuda_oflex.fwd(u, delta, A, B, C, D, delta_bias, delta_softplus, 1, oflex)
elif backend == "core":
out, x, *rest = selective_scan_cuda_core.fwd(u, delta, A, B, C, D, delta_bias, delta_softplus, 1)
elif backend == "mamba":
out, x, *rest = selective_scan_cuda.fwd(u, delta, A, B, C, D, None, delta_bias, delta_softplus)
ctx.save_for_backward(u, delta, A, B, C, D, delta_bias, x)
return out
@staticmethod
@torch.cuda.amp.custom_bwd
def backward(ctx, dout, *args):
u, delta, A, B, C, D, delta_bias, x = ctx.saved_tensors
backend = ctx.backend
if dout.stride(-1) != 1:
dout = dout.contiguous()
if backend == "oflex":
du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda_oflex.bwd(
u, delta, A, B, C, D, delta_bias, dout, x, ctx.delta_softplus, 1
)
elif backend == "core":
du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda_core.bwd(
u, delta, A, B, C, D, delta_bias, dout, x, ctx.delta_softplus, 1
)
elif backend == "mamba":
du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda.bwd(
u, delta, A, B, C, D, None, delta_bias, dout, x, None, None, ctx.delta_softplus,
False
)
return du, ddelta, dA, dB, dC, dD, ddelta_bias, None, None, None
def selective_scan_fn(
u: torch.Tensor, # (B, K * C, L)
delta: torch.Tensor, # (B, K * C, L)
A: torch.Tensor, # (K * C, N)
B: torch.Tensor, # (B, K, N, L)
C: torch.Tensor, # (B, K, N, L)
D: torch.Tensor = None, # (K * C)
delta_bias: torch.Tensor = None, # (K * C)
delta_softplus=True,
oflex=True,
backend=None,
):
WITH_CUDA = (WITH_SELECTIVESCAN_OFLEX or WITH_SELECTIVESCAN_CORE or WITH_SELECTIVESCAN_MAMBA)
fn = selective_scan_torch if backend == "torch" or (not WITH_CUDA) else SelectiveScanCuda.apply
return fn(u, delta, A, B, C, D, delta_bias, delta_softplus, oflex, backend)
# fvcore flops =======================================
def print_jit_input_names(inputs):
print("input params: ", end=" ", flush=True)
try:
for i in range(10):
print(inputs[i].debugName(), end=" ", flush=True)
except Exception as e:
pass
print("", flush=True)
def flops_selective_scan_fn(B=1, L=256, D=768, N=16, with_D=True, with_Z=False, with_complex=False):
"""
u: r(B D L)
delta: r(B D L)
A: r(D N)
B: r(B N L)
C: r(B N L)
D: r(D)
z: r(B D L)
delta_bias: r(D), fp32
ignores:
[.float(), +, .softplus, .shape, new_zeros, repeat, stack, to(dtype), silu]
"""
assert not with_complex
# https://github.com/state-spaces/mamba/issues/110
flops = 9 * B * L * D * N
if with_D:
flops += B * D * L
if with_Z:
flops += B * D * L
return flops
# this is only for selective_scan_ref...
def flops_selective_scan_ref(B=1, L=256, D=768, N=16, with_D=True, with_Z=False, with_Group=True, with_complex=False):
"""
u: r(B D L)
delta: r(B D L)
A: r(D N)
B: r(B N L)
C: r(B N L)
D: r(D)
z: r(B D L)
delta_bias: r(D), fp32
ignores:
[.float(), +, .softplus, .shape, new_zeros, repeat, stack, to(dtype), silu]
"""
import numpy as np
# fvcore.nn.jit_handles
def get_flops_einsum(input_shapes, equation):
np_arrs = [np.zeros(s) for s in input_shapes]
optim = np.einsum_path(equation, *np_arrs, optimize="optimal")[1]
for line in optim.split("\n"):
if "optimized flop" in line.lower():
# divided by 2 because we count MAC (multiply-add counted as one flop)
flop = float(np.floor(float(line.split(":")[-1]) / 2))
return flop
assert not with_complex
flops = 0 # below code flops = 0
flops += get_flops_einsum([[B, D, L], [D, N]], "bdl,dn->bdln")
if with_Group:
flops += get_flops_einsum([[B, D, L], [B, N, L], [B, D, L]], "bdl,bnl,bdl->bdln")
else:
flops += get_flops_einsum([[B, D, L], [B, D, N, L], [B, D, L]], "bdl,bdnl,bdl->bdln")
in_for_flops = B * D * N
if with_Group:
in_for_flops += get_flops_einsum([[B, D, N], [B, D, N]], "bdn,bdn->bd")
else:
in_for_flops += get_flops_einsum([[B, D, N], [B, N]], "bdn,bn->bd")
flops += L * in_for_flops
if with_D:
flops += B * D * L
if with_Z:
flops += B * D * L
return flops
def selective_scan_flop_jit(inputs, outputs, backend="prefixsum", verbose=True):
if verbose:
print_jit_input_names(inputs)
flops_fn = flops_selective_scan_ref if backend == "naive" else flops_selective_scan_fn
B, D, L = inputs[0].type().sizes()
N = inputs[2].type().sizes()[1]
flops = flops_fn(B=B, L=L, D=D, N=N, with_D=True, with_Z=False)
return flops
if __name__ == "__main__":
def params(B, K, C, N, L, device = torch.device("cuda"), itype = torch.float):
As = (-0.5 * torch.rand(K * C, N, device=device, dtype=torch.float32)).requires_grad_()
Bs = torch.randn((B, K, N, L), device=device, dtype=itype).requires_grad_()
Cs = torch.randn((B, K, N, L), device=device, dtype=itype).requires_grad_()
Ds = torch.randn((K * C), device=device, dtype=torch.float32).requires_grad_()
u = torch.randn((B, K * C, L), device=device, dtype=itype).requires_grad_()
delta = (0.5 * torch.rand((B, K * C, L), device=device, dtype=itype)).requires_grad_()
delta_bias = (0.5 * torch.rand((K * C), device=device, dtype=torch.float32)).requires_grad_()
return u, delta, As, Bs, Cs, Ds, delta_bias
def bench(func, xs, Warmup=30, NTimes=20):
import time
torch.cuda.synchronize()
for r in range(Warmup):
for x in xs:
func(x)
torch.cuda.synchronize()
tim0 = time.time()
for r in range(NTimes):
for x in xs:
func(x)
torch.cuda.synchronize()
return (time.time() - tim0) / NTimes
def check():
u, delta, As, Bs, Cs, Ds, delta_bias = params(1, 4, 16, 8, 512, itype=torch.float16)
u1, delta1, As1, Bs1, Cs1, Ds1, delta_bias1 = [x.clone().detach().requires_grad_() for x in [u, delta, As, Bs, Cs, Ds, delta_bias]]
# out_ref = selective_scan_fn(u, delta, As, Bs, Cs, Ds, delta_bias, True, backend="torch")
out = selective_scan_fn(u1, delta1, As1, Bs1, Cs1, Ds1, delta_bias1, True, backend="oflex")
out_ref = selective_scan_fn(u, delta, As, Bs, Cs, Ds, delta_bias, True, backend="mamba")
print((out_ref - out).abs().max())
out.sum().backward()
out_ref.sum().backward()
for x, y in zip([u, As, Bs, Cs, Ds, delta, delta_bias], [u1, As1, Bs1, Cs1, Ds1, delta1, delta_bias1]):
print((x.grad - y.grad).abs().max())
u, delta, As, Bs, Cs, Ds, delta_bias = params(128, 4, 96, 8, 56 * 56)
print(bench(lambda x: selective_scan_fn(x[0], x[1], x[2], x[3], x[4], x[5], x[6], True, backend="oflex"), [(u, delta, As, Bs, Cs, Ds, delta_bias),]))
print(bench(lambda x: selective_scan_fn(x[0], x[1], x[2], x[3], x[4], x[5], x[6], True, backend="mamba"), [(u, delta, As, Bs, Cs, Ds, delta_bias),]))
print(bench(lambda x: selective_scan_fn(x[0], x[1], x[2], x[3], x[4], x[5], x[6], True, backend="torch"), [(u, delta, As, Bs, Cs, Ds, delta_bias),]))
check()
vmambanew.py
import os
import time
import math
import copy
from functools import partial
from typing import Optional, Callable, Any
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, trunc_normal_
DropPath.__repr__ = lambda self: f"timm.DropPath({self.drop_prob})"
# train speed is slower after enabling this opts.
# torch.backends.cudnn.enabled = True
# torch.backends.cudnn.benchmark = True
# torch.backends.cudnn.deterministic = True
try:
from .csm_triton import cross_scan_fn, cross_merge_fn
except:
from csm_triton import cross_scan_fn, cross_merge_fn
try:
from .csm_tritonk2 import cross_scan_fn_k2, cross_merge_fn_k2
from .csm_tritonk2 import cross_scan_fn_k2_torch, cross_merge_fn_k2_torch
except:
from csm_tritonk2 import cross_scan_fn_k2, cross_merge_fn_k2
from csm_tritonk2 import cross_scan_fn_k2_torch, cross_merge_fn_k2_torch
try:
from .csms6s import selective_scan_fn, selective_scan_flop_jit
except:
from csms6s import selective_scan_fn, selective_scan_flop_jit
# FLOPs counter not prepared fro mamba2
# try:
# from .mamba2.ssd_minimal import selective_scan_chunk_fn
# except:
# from mamba2.ssd_minimal import selective_scan_chunk_fn
# =====================================================
# we have this class as linear and conv init differ from each other
# this function enable loading from both conv2d or linear
class Linear2d(nn.Linear):
def forward(self, x: torch.Tensor):
# B, C, H, W = x.shape
return F.conv2d(x, self.weight[:, :, None, None], self.bias)
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys,
error_msgs):
state_dict[prefix + "weight"] = state_dict[prefix + "weight"].view(self.weight.shape)
return super()._load_from_state_dict(state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys,
error_msgs)
class LayerNorm2d(nn.LayerNorm):
def forward(self, x: torch.Tensor):
x = x.permute(0, 2, 3, 1)
x = nn.functional.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
x = x.permute(0, 3, 1, 2)
return x
class PatchMerging2D(nn.Module):
def __init__(self, dim, out_dim=-1, norm_layer=nn.LayerNorm, channel_first=False):
super().__init__()
self.dim = dim
Linear = Linear2d if channel_first else nn.Linear
self._patch_merging_pad = self._patch_merging_pad_channel_first if channel_first else self._patch_merging_pad_channel_last
self.reduction = Linear(4 * dim, (2 * dim) if out_dim < 0 else out_dim, bias=False)
self.norm = norm_layer(4 * dim)
@staticmethod
def _patch_merging_pad_channel_last(x: torch.Tensor):
H, W, _ = x.shape[-3:]
if (W % 2 != 0) or (H % 2 != 0):
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
x0 = x[..., 0::2, 0::2, :] # ... H/2 W/2 C
x1 = x[..., 1::2, 0::2, :] # ... H/2 W/2 C
x2 = x[..., 0::2, 1::2, :] # ... H/2 W/2 C
x3 = x[..., 1::2, 1::2, :] # ... H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # ... H/2 W/2 4*C
return x
@staticmethod
def _patch_merging_pad_channel_first(x: torch.Tensor):
H, W = x.shape[-2:]
if (W % 2 != 0) or (H % 2 != 0):
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
x0 = x[..., 0::2, 0::2] # ... H/2 W/2
x1 = x[..., 1::2, 0::2] # ... H/2 W/2
x2 = x[..., 0::2, 1::2] # ... H/2 W/2
x3 = x[..., 1::2, 1::2] # ... H/2 W/2
x = torch.cat([x0, x1, x2, x3], 1) # ... H/2 W/2 4*C
return x
def forward(self, x):
x = self._patch_merging_pad(x)
x = self.norm(x)
x = self.reduction(x)
return x
class Permute(nn.Module):
def __init__(self, *args):
super().__init__()
self.args = args
def forward(self, x: torch.Tensor):
return x.permute(*self.args)
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.,
channels_first=False):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
Linear = Linear2d if channels_first else nn.Linear
self.fc1 = Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class gMlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.,
channels_first=False):
super().__init__()
self.channel_first = channels_first
out_features = out_features or in_features
hidden_features = hidden_features or in_features
Linear = Linear2d if channels_first else nn.Linear
self.fc1 = Linear(in_features, 2 * hidden_features)
self.act = act_layer()
self.fc2 = Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x: torch.Tensor):
x = self.fc1(x)
x, z = x.chunk(2, dim=(1 if self.channel_first else -1))
x = self.fc2(x * self.act(z))
x = self.drop(x)
return x
class SoftmaxSpatial(nn.Softmax):
def forward(self, x: torch.Tensor):
if self.dim == -1:
B, C, H, W = x.shape
return super().forward(x.view(B, C, -1).contiguous()).view(B, C, H, W).contiguous()
elif self.dim == 1:
B, H, W, C = x.shape
return super().forward(x.view(B, -1, C).contiguous()).view(B, H, W, C).contiguous()
else:
raise NotImplementedError
class Conv2d_BN(torch.nn.Sequential):
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
groups=1, bn_weight_init=1, resolution=-10000):
super().__init__()
self.add_module('c', torch.nn.Conv2d(
a, b, ks, stride, pad, dilation, groups, bias=False))
self.add_module('bn', torch.nn.BatchNorm2d(b))
torch.nn.init.constant_(self.bn.weight, bn_weight_init)
torch.nn.init.constant_(self.bn.bias, 0)
@torch.no_grad()
def fuse(self):
c, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps) ** 0.5
w = c.weight * w[:, None, None, None]
b = bn.bias - bn.running_mean * bn.weight / \
(bn.running_var + bn.eps) ** 0.5
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(
0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation,
groups=self.c.groups)
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
# =====================================================
class mamba_init:
@staticmethod
def dt_init(dt_rank, d_inner, dt_scale=1.0, dt_init="random", dt_min=0.001, dt_max=0.1, dt_init_floor=1e-4):
dt_proj = nn.Linear(dt_rank, d_inner, bias=True)
# Initialize special dt projection to preserve variance at initialization
dt_init_std = dt_rank ** -0.5 * dt_scale
if dt_init == "constant":
nn.init.constant_(dt_proj.weight, dt_init_std)
elif dt_init == "random":
nn.init.uniform_(dt_proj.weight, -dt_init_std, dt_init_std)
else:
raise NotImplementedError
# Initialize dt bias so that F.softplus(dt_bias) is between dt_min and dt_max
dt = torch.exp(
torch.rand(d_inner) * (math.log(dt_max) - math.log(dt_min))
+ math.log(dt_min)
).clamp(min=dt_init_floor)
# Inverse of softplus: https://github.com/pytorch/pytorch/issues/72759
inv_dt = dt + torch.log(-torch.expm1(-dt))
with torch.no_grad():
dt_proj.bias.copy_(inv_dt)
# Our initialization would set all Linear.bias to zero, need to mark this one as _no_reinit
# dt_proj.bias._no_reinit = True
return dt_proj
@staticmethod
def A_log_init(d_state, d_inner, copies=-1, device=None, merge=True):
# S4D real initialization
A = torch.arange(1, d_state + 1, dtype=torch.float32, device=device).view(1, -1).repeat(d_inner, 1).contiguous()
A_log = torch.log(A) # Keep A_log in fp32
if copies > 0:
A_log = A_log[None].repeat(copies, 1, 1).contiguous()
if merge:
A_log = A_log.flatten(0, 1)
A_log = nn.Parameter(A_log)
A_log._no_weight_decay = True
return A_log
@staticmethod
def D_init(d_inner, copies=-1, device=None, merge=True):
# D "skip" parameter
D = torch.ones(d_inner, device=device)
if copies > 0:
D = D[None].repeat(copies, 1).contiguous()
if merge:
D = D.flatten(0, 1)
D = nn.Parameter(D) # Keep in fp32
D._no_weight_decay = True
return D
@classmethod
def init_dt_A_D(cls, d_state, dt_rank, d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, k_group=4):
# dt proj ============================
dt_projs = [
cls.dt_init(dt_rank, d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor)
for _ in range(k_group)
]
dt_projs_weight = nn.Parameter(torch.stack([t.weight for t in dt_projs], dim=0)) # (K, inner, rank)
dt_projs_bias = nn.Parameter(torch.stack([t.bias for t in dt_projs], dim=0)) # (K, inner)
del dt_projs
# A, D =======================================
A_logs = cls.A_log_init(d_state, d_inner, copies=k_group, merge=True) # (K * D, N)
Ds = cls.D_init(d_inner, copies=k_group, merge=True) # (K * D)
return A_logs, Ds, dt_projs_weight, dt_projs_bias
class SS2Dv2:
def __initv2__(
self,
# basic dims ===========
d_model=96,
d_state=16,
ssm_ratio=2.0,
dt_rank="auto",
act_layer=nn.SiLU,
# dwconv ===============
d_conv=3, # < 2 means no conv
conv_bias=True,
# ======================
dropout=0.0,
bias=False,
# dt init ==============
dt_min=0.001,
dt_max=0.1,
dt_init="random",
dt_scale=1.0,
dt_init_floor=1e-4,
initialize="v0",
# ======================
forward_type="v05",
channel_first=False,
# ======================
k_group=4,
**kwargs,
):
factory_kwargs = {"device": None, "dtype": None}
super().__init__()
d_inner = int(ssm_ratio * d_model)
dt_rank = math.ceil(d_model / 16) if dt_rank == "auto" else dt_rank
self.channel_first = channel_first
self.with_dconv = d_conv > 1
Linear = Linear2d if channel_first else nn.Linear
self.forward = self.forwardv2
# tags for forward_type ==============================
checkpostfix = self.checkpostfix
self.disable_force32, forward_type = checkpostfix("_no32", forward_type)
self.oact, forward_type = checkpostfix("_oact", forward_type)
self.disable_z, forward_type = checkpostfix("_noz", forward_type)
self.disable_z_act, forward_type = checkpostfix("_nozact", forward_type)
self.out_norm, forward_type = self.get_outnorm(forward_type, d_inner, channel_first)
# forward_type debug =======================================
FORWARD_TYPES = dict(
v01=partial(self.forward_corev2, force_fp32=(not self.disable_force32), selective_scan_backend="mamba",
scan_force_torch=True),
v02=partial(self.forward_corev2, force_fp32=(not self.disable_force32), selective_scan_backend="mamba"),
v03=partial(self.forward_corev2, force_fp32=(not self.disable_force32), selective_scan_backend="oflex"),
v04=partial(self.forward_corev2, force_fp32=False), # selective_scan_backend="oflex", scan_mode="cross2d"
v05=partial(self.forward_corev2, force_fp32=False, no_einsum=True),
# selective_scan_backend="oflex", scan_mode="cross2d"
# ===============================
v051d=partial(self.forward_corev2, force_fp32=False, no_einsum=True, scan_mode="unidi"),
v052d=partial(self.forward_corev2, force_fp32=False, no_einsum=True, scan_mode="bidi"),
v052dc=partial(self.forward_corev2, force_fp32=False, no_einsum=True, scan_mode="cascade2d"),
# ===============================
v2=partial(self.forward_corev2, force_fp32=(not self.disable_force32), selective_scan_backend="core"),
v3=partial(self.forward_corev2, force_fp32=False, selective_scan_backend="oflex"),
)
self.forward_core = FORWARD_TYPES.get(forward_type, None)
self.k_group = k_group
# in proj =======================================
d_proj = d_inner if self.disable_z else (d_inner * 2)
self.in_proj = Conv2d_BN(d_model, d_proj)
# self.in_proj = Linear(d_model, d_proj, bias=bias)
self.act: nn.Module = act_layer()
# conv =======================================
if self.with_dconv:
self.conv2d = nn.Conv2d(
in_channels=d_inner,
out_channels=d_inner,
groups=d_inner,
bias=conv_bias,
kernel_size=d_conv,
padding=(d_conv - 1) // 2,
**factory_kwargs,
)
# x proj ============================
self.x_proj = [
nn.Linear(d_inner, (dt_rank + d_state * 2), bias=False)
# torch.nn.Conv2d(d_inner, (dt_rank + d_state * 2), 1, bias=False)
for _ in range(k_group)
]
self.x_proj_weight = nn.Parameter(torch.stack([t.weight for t in self.x_proj], dim=0)) # (K, N, inner)
del self.x_proj
# out proj =======================================
self.out_act = nn.GELU() if self.oact else nn.Identity()
self.out_proj = Conv2d_BN(d_inner, d_model)
# self.out_proj = Linear(d_inner, d_model, bias=bias)
self.dropout = nn.Dropout(dropout) if dropout > 0. else nn.Identity()
if initialize in ["v0"]:
self.A_logs, self.Ds, self.dt_projs_weight, self.dt_projs_bias = mamba_init.init_dt_A_D(
d_state, dt_rank, d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, k_group=k_group,
)
elif initialize in ["v1"]:
# simple init dt_projs, A_logs, Ds
self.Ds = nn.Parameter(torch.ones((k_group * d_inner)))
self.A_logs = nn.Parameter(
torch.randn((k_group * d_inner, d_state))) # A == -A_logs.exp() < 0; # 0 < exp(A * dt) < 1
self.dt_projs_weight = nn.Parameter(0.1 * torch.randn((k_group, d_inner, dt_rank))) # 0.1 is added in 0430
self.dt_projs_bias = nn.Parameter(0.1 * torch.randn((k_group, d_inner))) # 0.1 is added in 0430
elif initialize in ["v2"]:
# simple init dt_projs, A_logs, Ds
self.Ds = nn.Parameter(torch.ones((k_group * d_inner)))
self.A_logs = nn.Parameter(
torch.zeros((k_group * d_inner, d_state))) # A == -A_logs.exp() < 0; # 0 < exp(A * dt) < 1
self.dt_projs_weight = nn.Parameter(0.1 * torch.rand((k_group, d_inner, dt_rank)))
self.dt_projs_bias = nn.Parameter(0.1 * torch.rand((k_group, d_inner)))
def forward_corev2(
self,
x: torch.Tensor = None,
# ==============================
force_fp32=False, # True: input fp32
# ==============================
ssoflex=True, # True: input 16 or 32 output 32 False: output dtype as input
no_einsum=False, # replace einsum with linear or conv1d to raise throughput
# ==============================
selective_scan_backend=None,
# ==============================
scan_mode="cross2d",
scan_force_torch=False,
# ==============================
**kwargs,
):
x_dtype = x.dtype
assert scan_mode in ["unidi", "bidi", "cross2d", "cascade2d"]
assert selective_scan_backend in [None, "oflex", "core", "mamba", "torch"]
delta_softplus = True
out_norm = self.out_norm
channel_first = self.channel_first
to_fp32 = lambda *args: (_a.to(torch.float32) for _a in args)
B, D, H, W = x.shape
D, N = self.A_logs.shape
K, D, R = self.dt_projs_weight.shape
L = H * W
_scan_mode = dict(cross2d=0, unidi=1, bidi=2, cascade2d=3)[scan_mode]
def selective_scan(u, delta, A, B, C, D=None, delta_bias=None, delta_softplus=True):
# print(u.device)
# print(selective_scan_backend)
if u.device == torch.device("cpu"):
selective_scan_backend = "torch"
else:
selective_scan_backend = "oflex"
return selective_scan_fn(u, delta, A, B, C, D, delta_bias, delta_softplus, ssoflex,
backend=selective_scan_backend)
if _scan_mode == 3:
x_proj_bias = getattr(self, "x_proj_bias", None)
def scan_rowcol(
x: torch.Tensor,
proj_weight: torch.Tensor,
proj_bias: torch.Tensor,
dt_weight: torch.Tensor,
dt_bias: torch.Tensor, # (2*c)
_As: torch.Tensor, # As = -torch.exp(A_logs.to(torch.float))[:2,] # (2*c, d_state)
_Ds: torch.Tensor,
width=True,
):
# x: (B, D, H, W)
# proj_weight: (2 * D, (R+N+N))
XB, XD, XH, XW = x.shape
if width:
_B, _D, _L = XB * XH, XD, XW
xs = x.permute(0, 2, 1, 3).contiguous()
else:
_B, _D, _L = XB * XW, XD, XH
xs = x.permute(0, 3, 1, 2).contiguous()
xs = torch.stack([xs, xs.flip(dims=[-1])], dim=2) # (B, H, 2, D, W)
if no_einsum:
x_dbl = F.conv1d(xs.view(_B, -1, _L), proj_weight.view(-1, _D, 1),
bias=(proj_bias.view(-1) if proj_bias is not None else None), groups=2)
dts, Bs, Cs = torch.split(x_dbl.view(_B, 2, -1, _L), [R, N, N], dim=2)
dts = F.conv1d(dts.contiguous().view(_B, -1, _L), dt_weight.view(2 * _D, -1, 1), groups=2)
else:
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs, proj_weight)
if x_proj_bias is not None:
x_dbl = x_dbl + x_proj_bias.view(1, 2, -1, 1)
dts, Bs, Cs = torch.split(x_dbl, [R, N, N], dim=2)
dts = torch.einsum("b k r l, k d r -> b k d l", dts, dt_weight)
xs = xs.view(_B, -1, _L)
dts = dts.contiguous().view(_B, -1, _L)
As = _As.view(-1, N).to(torch.float)
Bs = Bs.contiguous().view(_B, 2, N, _L)
Cs = Cs.contiguous().view(_B, 2, N, _L)
Ds = _Ds.view(-1)
delta_bias = dt_bias.view(-1).to(torch.float)
if force_fp32:
xs = xs.to(torch.float)
dts = dts.to(xs.dtype)
Bs = Bs.to(xs.dtype)
Cs = Cs.to(xs.dtype)
ys: torch.Tensor = selective_scan(
xs, dts, As, Bs, Cs, Ds, delta_bias, delta_softplus
).view(_B, 2, -1, _L)
return ys
As = -self.A_logs.to(torch.float).exp().view(self.k_group, -1, N).contiguous()
x = F.layer_norm(x.permute(0, 2, 3, 1), normalized_shape=(int(x.shape[1]),)).permute(0, 3, 1,
2).contiguous() # added0510 to avoid nan
y_row = scan_rowcol(
x,
proj_weight=self.x_proj_weight.view(self.k_group, -1, D)[:2].contiguous(),
proj_bias=(x_proj_bias.view(self.k_group, -1)[:2].contiguous() if x_proj_bias is not None else None),
dt_weight=self.dt_projs_weight.view(self.k_group, D, -1)[:2].contiguous(),
dt_bias=(self.dt_projs_bias.view(self.k_group, -1)[
:2].contiguous() if self.dt_projs_bias is not None else None),
_As=As[:2].contiguous().view(-1, N),
_Ds=self.Ds.view(self.k_group, -1)[:2].contiguous().view(-1),
width=True,
).view(B, H, 2, -1, W).sum(dim=2).permute(0, 2, 1, 3).contiguous() # (B,C,H,W)
y_row = F.layer_norm(y_row.permute(0, 2, 3, 1), normalized_shape=(int(y_row.shape[1]),)).permute(0, 3, 1,
2).contiguous() # added0510 to avoid nan
y_col = scan_rowcol(
y_row,
proj_weight=self.x_proj_weight.view(self.k_group, -1, D)[2:].contiguous().to(y_row.dtype),
proj_bias=(
x_proj_bias.view(self.k_group, -1)[2:].contiguous().to(
y_row.dtype) if x_proj_bias is not None else None),
dt_weight=self.dt_projs_weight.view(self.k_group, D, -1)[2:].contiguous().to(y_row.dtype),
dt_bias=(self.dt_projs_bias.view(self.k_group, -1)[2:].contiguous().to(
y_row.dtype) if self.dt_projs_bias is not None else None),
_As=As[2:].contiguous().view(-1, N),
_Ds=self.Ds.view(self.k_group, -1)[2:].contiguous().view(-1),
width=False,
).view(B, W, 2, -1, H).sum(dim=2).permute(0, 2, 3, 1).contiguous()
y = y_col
else:
x_proj_bias = getattr(self, "x_proj_bias", None)
if self.k_group == 4:
xs = cross_scan_fn(x, in_channel_first=True, out_channel_first=True, scans=_scan_mode,
force_torch=scan_force_torch)
else:
xs = cross_scan_fn_k2(x, in_channel_first=True, out_channel_first=True, scans=_scan_mode,
force_torch=scan_force_torch)
if no_einsum:
x_dbl = F.conv1d(xs.view(B, -1, L).contiguous(), self.x_proj_weight.view(-1, D, 1).contiguous(),
bias=(x_proj_bias.view(-1) if x_proj_bias is not None else None), groups=K)
dts, Bs, Cs = torch.split(x_dbl.view(B, K, -1, L).contiguous(), [R, N, N], dim=2)
dts = F.conv1d(dts.contiguous().view(B, -1, L).contiguous(), self.dt_projs_weight.view(K * D, -1, 1).contiguous(), groups=K)
else:
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs, self.x_proj_weight)
if x_proj_bias is not None:
x_dbl = x_dbl + x_proj_bias.view(1, K, -1, 1).contiguous()
dts, Bs, Cs = torch.split(x_dbl, [R, N, N], dim=2)
dts = torch.einsum("b k r l, k d r -> b k d l", dts, self.dt_projs_weight)
xs = xs.view(B, -1, L).contiguous()
dts = dts.contiguous().view(B, -1, L).contiguous()
As = -self.A_logs.to(torch.float).exp() # (k * c, d_state)
Ds = self.Ds.to(torch.float) # (K * c)
Bs = Bs.contiguous().view(B, K, N, L).contiguous()
Cs = Cs.contiguous().view(B, K, N, L).contiguous()
delta_bias = self.dt_projs_bias.view(-1).contiguous().to(torch.float)
if force_fp32:
xs, dts, Bs, Cs = to_fp32(xs, dts, Bs, Cs)
ys: torch.Tensor = selective_scan(
xs, dts, As, Bs, Cs, Ds, delta_bias, delta_softplus
).view(B, K, -1, H, W).contiguous()
if self.k_group == 4:
y: torch.Tensor = cross_merge_fn(ys, in_channel_first=True, out_channel_first=True, scans=_scan_mode,
force_torch=scan_force_torch)
else:
y: torch.Tensor = cross_merge_fn_k2(ys, in_channel_first=True, out_channel_first=True, scans=_scan_mode,
force_torch=scan_force_torch)
if getattr(self, "__DEBUG__", False):
setattr(self, "__data__", dict(
A_logs=self.A_logs, Bs=Bs, Cs=Cs, Ds=Ds,
us=xs, dts=dts, delta_bias=delta_bias,
ys=ys, y=y, H=H, W=W,
))
y = y.view(B, -1, H, W).contiguous()
if not channel_first:
y = y.view(B, -1, H * W).contiguous().transpose(dim0=1, dim1=2).contiguous().view(B, H, W, -1).contiguous() # (B, L, C)
y = out_norm(y.to(x_dtype))
return y.to(x.dtype)
def forwardv2(self, x: torch.Tensor, **kwargs):
x = self.in_proj(x)
x, z = x.chunk(2, dim=(1 if self.channel_first else -1)) # (b, h, w, d)
z = self.act(z.contiguous().clone())
x = self.conv2d(x) # (b, d, h, w)
x = self.act(x)
y = self.forward_core(x)
y = self.out_act(y)
y = y * z
out = self.dropout(self.out_proj(y))
return out
@staticmethod
def get_outnorm(forward_type="", d_inner=192, channel_first=True):
def checkpostfix(tag, value):
ret = value[-len(tag):] == tag
if ret:
value = value[:-len(tag)]
return ret, value
LayerNorm = LayerNorm2d if channel_first else nn.LayerNorm
out_norm_none, forward_type = checkpostfix("_onnone", forward_type)
out_norm_dwconv3, forward_type = checkpostfix("_ondwconv3", forward_type)
out_norm_cnorm, forward_type = checkpostfix("_oncnorm", forward_type)
out_norm_softmax, forward_type = checkpostfix("_onsoftmax", forward_type)
out_norm_sigmoid, forward_type = checkpostfix("_onsigmoid", forward_type)
out_norm = nn.Identity()
if out_norm_none:
out_norm = nn.Identity()
elif out_norm_cnorm:
out_norm = nn.Sequential(
LayerNorm(d_inner),
(nn.Identity() if channel_first else Permute(0, 3, 1, 2)),
nn.Conv2d(d_inner, d_inner, kernel_size=3, padding=1, groups=d_inner, bias=False),
(nn.Identity() if channel_first else Permute(0, 2, 3, 1)),
)
elif out_norm_dwconv3:
out_norm = nn.Sequential(
(nn.Identity() if channel_first else Permute(0, 3, 1, 2)),
nn.Conv2d(d_inner, d_inner, kernel_size=3, padding=1, groups=d_inner, bias=False),
(nn.Identity() if channel_first else Permute(0, 2, 3, 1)),
)
elif out_norm_softmax:
out_norm = SoftmaxSpatial(dim=(-1 if channel_first else 1))
elif out_norm_sigmoid:
out_norm = nn.Sigmoid()
else:
out_norm = LayerNorm(d_inner)
return out_norm, forward_type
@staticmethod
def checkpostfix(tag, value):
ret = value[-len(tag):] == tag
if ret:
value = value[:-len(tag)]
return ret, value
# mamba2 support ================================
class SS2Dm0:
def __initm0__(
self,
# basic dims ===========
d_model=96,
d_state=16, # now with mamba2, dstate should be bigger...
ssm_ratio=2.0,
dt_rank="auto",
act_layer=nn.GELU,
# dwconv ===============
d_conv=3, # < 2 means no conv
conv_bias=True,
# ======================
dropout=0.0,
bias=False,
# dt init ==============
dt_min=0.001,
dt_max=0.1,
dt_init="random",
dt_scale=1.0,
dt_init_floor=1e-4,
initialize="v2",
# ======================
forward_type="m0",
# ======================
with_initial_state=False,
channel_first=False,
# ======================
**kwargs,
):
factory_kwargs = {"device": None, "dtype": None}
super().__init__()
d_inner = int(ssm_ratio * d_model)
dt_rank = math.ceil(d_model / 16) if dt_rank == "auto" else dt_rank
assert d_inner % dt_rank == 0
self.channel_first = channel_first
Linear = Linear2d if channel_first else nn.Linear
self.with_dconv = d_conv > 1
self.forward = self.forwardm0
# tags for forward_type ==============================
checkpostfix = SS2Dv2.checkpostfix
self.disable_force32, forward_type = checkpostfix("_no32", forward_type)
self.oact, forward_type = checkpostfix("_oact", forward_type)
self.disable_z, forward_type = checkpostfix("_noz", forward_type)
self.disable_z_act, forward_type = checkpostfix("_nozact", forward_type)
self.out_norm, forward_type = SS2Dv2.get_outnorm(forward_type, d_inner, False)
# forward_type debug =======================================
FORWARD_TYPES = dict(
m0=partial(self.forward_corem0, force_fp32=False, dstate=d_state),
)
self.forward_core = FORWARD_TYPES.get(forward_type, None)
k_group = 4
# in proj =======================================
d_proj = d_inner if self.disable_z else (d_inner * 2)
# self.in_proj = Linear(d_model, d_proj, bias=bias)
self.in_proj = Conv2d_BN(d_model, d_proj)
self.act: nn.Module = act_layer()
# conv =======================================
if self.with_dconv:
self.conv2d = nn.Conv2d(
in_channels=d_inner,
out_channels=d_inner,
groups=d_inner,
bias=conv_bias,
kernel_size=d_conv,
padding=(d_conv - 1) // 2,
**factory_kwargs,
)
# x proj ============================
self.x_proj = [
nn.Linear(d_inner, (dt_rank + d_state * 2), bias=False)
for _ in range(k_group)
]
self.x_proj_weight = nn.Parameter(torch.stack([t.weight for t in self.x_proj], dim=0)) # (K, N, inner)
del self.x_proj
# out proj =======================================
self.out_act = nn.GELU() if self.oact else nn.Identity()
# self.out_proj = Linear(d_inner, d_model, bias=bias)
self.out_proj = Conv2d_BN(d_inner, d_model)
self.dropout = nn.Dropout(dropout) if dropout > 0. else nn.Identity()
if initialize in ["v1"]:
# simple init dt_projs, A_logs, Ds
self.Ds = nn.Parameter(torch.ones((k_group, dt_rank, int(d_inner // dt_rank))))
self.A_logs = nn.Parameter(torch.randn((k_group, dt_rank))) # A == -A_logs.exp() < 0; # 0 < exp(A * dt) < 1
self.dt_projs_bias = nn.Parameter(0.1 * torch.randn((k_group, dt_rank))) # 0.1 is added in 0430
elif initialize in ["v2"]:
# simple init dt_projs, A_logs, Ds
self.Ds = nn.Parameter(torch.ones((k_group, dt_rank, int(d_inner // dt_rank))))
self.A_logs = nn.Parameter(torch.zeros((k_group, dt_rank))) # A == -A_logs.exp() < 0; # 0 < exp(A * dt) < 1
self.dt_projs_bias = nn.Parameter(0.1 * torch.rand((k_group, dt_rank)))
# init state ============================
self.initial_state = None
if with_initial_state:
self.initial_state = nn.Parameter(torch.zeros((1, k_group * dt_rank, int(d_inner // dt_rank), d_state)),
requires_grad=False)
def forward_corem0(
self,
x: torch.Tensor = None,
# ==============================
force_fp32=False, # True: input fp32
chunk_size=64,
dstate=64,
# ==============================
selective_scan_backend='torch',
scan_mode="cross2d",
scan_force_torch=False,
# ==============================
**kwargs,
):
x_dtype = x.dtype
assert scan_mode in ["unidi", "bidi", "cross2d"]
assert selective_scan_backend in [None, "triton", "torch"]
x_proj_bias = getattr(self, "x_proj_bias", None)
to_fp32 = lambda *args: (_a.to(torch.float32) for _a in args)
N = dstate
B, H, W, RD = x.shape
K, R = self.A_logs.shape
K, R, D = self.Ds.shape
assert RD == R * D
L = H * W
KR = K * R
_scan_mode = dict(cross2d=0, unidi=1, bidi=2, cascade2d=3)[scan_mode]
initial_state = None
if self.initial_state is not None:
assert self.initial_state.shape[-1] == dstate
initial_state = self.initial_state.detach().repeat(B, 1, 1, 1)
xs = cross_scan_fn(x.view(B, H, W, RD).contiguous(), in_channel_first=False, out_channel_first=False,
scans=_scan_mode, force_torch=scan_force_torch) # (B, H, W, 4, D)
x_dbl = torch.einsum("b l k d, k c d -> b l k c", xs, self.x_proj_weight)
if x_proj_bias is not None:
x_dbl = x_dbl + x_proj_bias.view(1, -1, K, 1)
dts, Bs, Cs = torch.split(x_dbl, [R, N, N], dim=3)
xs = xs.contiguous().view(B, L, KR, D).contiguous()
dts = dts.contiguous().view(B, L, KR).contiguous()
Bs = Bs.contiguous().view(B, L, K, N).contiguous()
Cs = Cs.contiguous().view(B, L, K, N).contiguous()
if force_fp32:
xs, dts, Bs, Cs = to_fp32(xs, dts, Bs, Cs)
As = -self.A_logs.to(torch.float).exp().view(KR).contiguous()
Ds = self.Ds.to(torch.float).view(KR, D).contiguous()
dt_bias = self.dt_projs_bias.view(KR).contiguous()
if force_fp32:
xs, dts, Bs, Cs = to_fp32(xs, dts, Bs, Cs)
ys, final_state = selective_scan_chunk_fn(
xs, dts, As, Bs, Cs, chunk_size=chunk_size, D=Ds, dt_bias=dt_bias,
initial_states=initial_state, dt_softplus=True, return_final_states=True,
backend=selective_scan_backend,
)
y: torch.Tensor = cross_merge_fn(ys.contiguous().view(B, H, W, K, RD).contiguous(), in_channel_first=False,
out_channel_first=False, scans=_scan_mode, force_torch=scan_force_torch)
if getattr(self, "__DEBUG__", False):
setattr(self, "__data__", dict(
A_logs=self.A_logs, Bs=Bs, Cs=Cs, Ds=self.Ds,
us=xs, dts=dts, delta_bias=self.dt_projs_bias,
initial_state=self.initial_state, final_satte=final_state,
ys=ys, y=y, H=H, W=W,
))
if self.initial_state is not None:
self.initial_state = nn.Parameter(final_state.detach().sum(0, keepdim=True), requires_grad=False)
y = self.out_norm(y.view(B, H, W, -1).contiguous().to(x_dtype))
return y.to(x.dtype)
def forwardm0(self, x: torch.Tensor, **kwargs):
x = self.in_proj(x)
if not self.disable_z:
x, z = x.chunk(2, dim=(1 if self.channel_first else -1)) # (b, h, w, d)
if not self.disable_z_act:
z = self.act(z.contiguous())
if self.with_dconv:
x = self.conv2d(x) # (b, d, h, w)
x = self.act(x)
y = self.forward_core(x.permute(0, 2, 3, 1)).permute(0, 3, 1, 2)
y = self.out_act(y)
if not self.disable_z:
y = y * z
out = self.dropout(self.out_proj(y))
return out
class SS2D(nn.Module, SS2Dv2, SS2Dm0):
def __init__(
self,
# basic dims ===========
d_model=96,
d_state=16,
ssm_ratio=2.0,
dt_rank="auto",
act_layer=nn.SiLU,
# dwconv ===============
d_conv=3, # < 2 means no conv
conv_bias=True,
# ======================
dropout=0.0,
bias=False,
# dt init ==============
dt_min=0.001,
dt_max=0.1,
dt_init="random",
dt_scale=1.0,
dt_init_floor=1e-4,
initialize="v0",
# ======================
forward_type="v5",
channel_first=False,
# ======================
k_group=4,
**kwargs,
):
super().__init__()
kwargs.update(
d_model=d_model, d_state=d_state, ssm_ratio=ssm_ratio, dt_rank=dt_rank,
act_layer=act_layer, d_conv=d_conv, conv_bias=conv_bias, dropout=dropout, bias=bias,
dt_min=dt_min, dt_max=dt_max, dt_init=dt_init, dt_scale=dt_scale, dt_init_floor=dt_init_floor,
initialize=initialize, forward_type=forward_type, channel_first=channel_first, k_group=k_group,
)
if forward_type in ["v0", "v0seq"]:
self.__initv0__(seq=("seq" in forward_type), **kwargs)
elif forward_type.startswith("xv"):
self.__initxv__(**kwargs)
elif forward_type.startswith("m"):
self.__initm0__(**kwargs)
else:
self.__initv2__(**kwargs)
# =====================================================
class VSSBlock(nn.Module):
def __init__(
self,
hidden_dim: int = 0,
drop_path: float = 0,
norm_layer: nn.Module = nn.LayerNorm,
channel_first=False,
# =============================
ssm_d_state: int = 16,
ssm_ratio=1,
ssm_dt_rank: Any = "auto",
ssm_act_layer=nn.SiLU,
ssm_conv: int = 3,
ssm_conv_bias=True,
ssm_drop_rate: float = 0,
ssm_init="v0",
forward_type="v05_noz",
# =============================
mlp_ratio=4.0,
mlp_act_layer=nn.GELU,
mlp_drop_rate: float = 0.0,
gmlp=False,
# =============================
use_checkpoint: bool = False,
post_norm: bool = False,
**kwargs,
):
super().__init__()
self.ssm_branch = ssm_ratio > 0
self.mlp_branch = mlp_ratio > 0
self.use_checkpoint = use_checkpoint
self.post_norm = post_norm
if self.ssm_branch:
self.norm = norm_layer(hidden_dim)
self.op = SS2D(
d_model=hidden_dim,
d_state=ssm_d_state,
ssm_ratio=ssm_ratio,
dt_rank=ssm_dt_rank,
act_layer=ssm_act_layer,
# ==========================
d_conv=ssm_conv,
conv_bias=ssm_conv_bias,
# ==========================
dropout=ssm_drop_rate,
# bias=False,
# ==========================
# dt_min=0.001,
# dt_max=0.1,
# dt_init="random",
# dt_scale="random",
# dt_init_floor=1e-4,
initialize=ssm_init,
# ==========================
forward_type=forward_type,
channel_first=channel_first,
)
self.drop_path = DropPath(drop_path)
if self.mlp_branch:
_MLP = Mlp if not gmlp else gMlp
self.norm2 = norm_layer(hidden_dim)
mlp_hidden_dim = int(hidden_dim * mlp_ratio)
self.mlp = _MLP(in_features=hidden_dim, hidden_features=mlp_hidden_dim, act_layer=mlp_act_layer,
drop=mlp_drop_rate, channels_first=channel_first)
def _forward(self, input: torch.Tensor):
x = input
if self.ssm_branch:
if self.post_norm:
x = x + self.drop_path(self.norm(self.op(x)))
else:
x = x + self.drop_path(self.op(self.norm(x)))
if self.mlp_branch:
if self.post_norm:
x = x + self.drop_path(self.norm2(self.mlp(x))) # FFN
else:
x = x + self.drop_path(self.mlp(self.norm2(x))) # FFN
return x
def forward(self, input: torch.Tensor):
if self.use_checkpoint:
return checkpoint.checkpoint(self._forward, input)
else:
return self._forward(input)
class VSSM(nn.Module):
def __init__(
self,
patch_size=4,
in_chans=3,
num_classes=1000,
depths=[2, 2, 9, 2],
dims=[96, 192, 384, 768],
# =========================
ssm_d_state=16,
ssm_ratio=2.0,
ssm_dt_rank="auto",
ssm_act_layer="silu",
ssm_conv=3,
ssm_conv_bias=True,
ssm_drop_rate=0.0,
ssm_init="v0",
forward_type="v2",
# =========================
mlp_ratio=4.0,
mlp_act_layer="gelu",
mlp_drop_rate=0.0,
gmlp=False,
# =========================
drop_path_rate=0.1,
patch_norm=True,
norm_layer="LN", # "BN", "LN2D"
downsample_version: str = "v2", # "v1", "v2", "v3"
patchembed_version: str = "v1", # "v1", "v2"
use_checkpoint=False,
# =========================
posembed=False,
imgsize=224,
**kwargs,
):
super().__init__()
self.channel_first = (norm_layer.lower() in ["bn", "ln2d"])
self.num_classes = num_classes
self.num_layers = len(depths)
if isinstance(dims, int):
dims = [int(dims * 2 ** i_layer) for i_layer in range(self.num_layers)]
self.num_features = dims[-1]
self.dims = dims
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
_NORMLAYERS = dict(
ln=nn.LayerNorm,
ln2d=LayerNorm2d,
bn=nn.BatchNorm2d,
)
_ACTLAYERS = dict(
silu=nn.SiLU,
gelu=nn.GELU,
relu=nn.ReLU,
sigmoid=nn.Sigmoid,
)
norm_layer: nn.Module = _NORMLAYERS.get(norm_layer.lower(), None)
ssm_act_layer: nn.Module = _ACTLAYERS.get(ssm_act_layer.lower(), None)
mlp_act_layer: nn.Module = _ACTLAYERS.get(mlp_act_layer.lower(), None)
self.pos_embed = self._pos_embed(dims[0], patch_size, imgsize) if posembed else None
_make_patch_embed = dict(
v1=self._make_patch_embed,
v2=self._make_patch_embed_v2,
).get(patchembed_version, None)
self.patch_embed = _make_patch_embed(in_chans, dims[0], patch_size, patch_norm, norm_layer,
channel_first=self.channel_first)
_make_downsample = dict(
v1=PatchMerging2D,
v2=self._make_downsample,
v3=self._make_downsample_v3,
none=(lambda *_, **_k: None),
).get(downsample_version, None)
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
downsample = _make_downsample(
self.dims[i_layer],
self.dims[i_layer + 1],
norm_layer=norm_layer,
channel_first=self.channel_first,
) if (i_layer < self.num_layers - 1) else nn.Identity()
self.layers.append(self._make_layer(
dim=self.dims[i_layer],
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
use_checkpoint=use_checkpoint,
norm_layer=norm_layer,
downsample=downsample,
channel_first=self.channel_first,
# =================
ssm_d_state=ssm_d_state,
ssm_ratio=ssm_ratio,
ssm_dt_rank=ssm_dt_rank,
ssm_act_layer=ssm_act_layer,
ssm_conv=ssm_conv,
ssm_conv_bias=ssm_conv_bias,
ssm_drop_rate=ssm_drop_rate,
ssm_init=ssm_init,
forward_type=forward_type,
# =================
mlp_ratio=mlp_ratio,
mlp_act_layer=mlp_act_layer,
mlp_drop_rate=mlp_drop_rate,
gmlp=gmlp,
))
self.classifier = nn.Sequential(OrderedDict(
norm=norm_layer(self.num_features), # B,H,W,C
permute=(Permute(0, 3, 1, 2) if not self.channel_first else nn.Identity()),
avgpool=nn.AdaptiveAvgPool2d(1),
flatten=nn.Flatten(1),
head=nn.Linear(self.num_features, num_classes),
))
self.apply(self._init_weights)
@staticmethod
def _pos_embed(embed_dims, patch_size, img_size):
patch_height, patch_width = (img_size // patch_size, img_size // patch_size)
pos_embed = nn.Parameter(torch.zeros(1, embed_dims, patch_height, patch_width))
trunc_normal_(pos_embed, std=0.02)
return pos_embed
def _init_weights(self, m: nn.Module):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
# used in building optimizer
@torch.jit.ignore
def no_weight_decay(self):
return {"pos_embed"}
# used in building optimizer
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {}
@staticmethod
def _make_patch_embed(in_chans=3, embed_dim=96, patch_size=4, patch_norm=True, norm_layer=nn.LayerNorm,
channel_first=False):
# if channel first, then Norm and Output are both channel_first
return nn.Sequential(
nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size, bias=True),
(nn.Identity() if channel_first else Permute(0, 2, 3, 1)),
(norm_layer(embed_dim) if patch_norm else nn.Identity()),
)
@staticmethod
def _make_patch_embed_v2(in_chans=3, embed_dim=96, patch_size=4, patch_norm=True, norm_layer=nn.LayerNorm,
channel_first=False):
# if channel first, then Norm and Output are both channel_first
stride = patch_size // 2
kernel_size = stride + 1
padding = 1
return nn.Sequential(
nn.Conv2d(in_chans, embed_dim // 2, kernel_size=kernel_size, stride=stride, padding=padding),
(nn.Identity() if (channel_first or (not patch_norm)) else Permute(0, 2, 3, 1)),
(norm_layer(embed_dim // 2) if patch_norm else nn.Identity()),
(nn.Identity() if (channel_first or (not patch_norm)) else Permute(0, 3, 1, 2)),
nn.GELU(),
nn.Conv2d(embed_dim // 2, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding),
(nn.Identity() if channel_first else Permute(0, 2, 3, 1)),
(norm_layer(embed_dim) if patch_norm else nn.Identity()),
)
@staticmethod
def _make_downsample(dim=96, out_dim=192, norm_layer=nn.LayerNorm, channel_first=False):
# if channel first, then Norm and Output are both channel_first
return nn.Sequential(
(nn.Identity() if channel_first else Permute(0, 3, 1, 2)),
nn.Conv2d(dim, out_dim, kernel_size=2, stride=2),
(nn.Identity() if channel_first else Permute(0, 2, 3, 1)),
norm_layer(out_dim),
)
@staticmethod
def _make_downsample_v3(dim=96, out_dim=192, norm_layer=nn.LayerNorm, channel_first=False):
# if channel first, then Norm and Output are both channel_first
return nn.Sequential(
(nn.Identity() if channel_first else Permute(0, 3, 1, 2)),
nn.Conv2d(dim, out_dim, kernel_size=3, stride=2, padding=1),
(nn.Identity() if channel_first else Permute(0, 2, 3, 1)),
norm_layer(out_dim),
)
@staticmethod
def _make_layer(
dim=96,
drop_path=[0.1, 0.1],
use_checkpoint=False,
norm_layer=nn.LayerNorm,
downsample=nn.Identity(),
channel_first=False,
# ===========================
ssm_d_state=16,
ssm_ratio=2.0,
ssm_dt_rank="auto",
ssm_act_layer=nn.SiLU,
ssm_conv=3,
ssm_conv_bias=True,
ssm_drop_rate=0.0,
ssm_init="v0",
forward_type="v2",
# ===========================
mlp_ratio=4.0,
mlp_act_layer=nn.GELU,
mlp_drop_rate=0.0,
gmlp=False,
**kwargs,
):
# if channel first, then Norm and Output are both channel_first
depth = len(drop_path)
blocks = []
for d in range(depth):
blocks.append(VSSBlock(
hidden_dim=dim,
drop_path=drop_path[d],
norm_layer=norm_layer,
channel_first=channel_first,
ssm_d_state=ssm_d_state,
ssm_ratio=ssm_ratio,
ssm_dt_rank=ssm_dt_rank,
ssm_act_layer=ssm_act_layer,
ssm_conv=ssm_conv,
ssm_conv_bias=ssm_conv_bias,
ssm_drop_rate=ssm_drop_rate,
ssm_init=ssm_init,
forward_type=forward_type,
mlp_ratio=mlp_ratio,
mlp_act_layer=mlp_act_layer,
mlp_drop_rate=mlp_drop_rate,
gmlp=gmlp,
use_checkpoint=use_checkpoint,
))
return nn.Sequential(OrderedDict(
blocks=nn.Sequential(*blocks, ),
downsample=downsample,
))
def forward(self, x: torch.Tensor):
x = self.patch_embed(x)
out_features = []
if self.pos_embed is not None:
pos_embed = self.pos_embed.permute(0, 2, 3, 1) if not self.channel_first else self.pos_embed
x = x + pos_embed
out_features.append(x)
for layer in self.layers:
x = layer(x)
if len(out_features) < 2:
out_features.append(x)
x = self.classifier(x)
return x
def flops(self, shape=(3, 224, 224), verbose=True):
# shape = self.__input_shape__[1:]
supported_ops = {
"aten::silu": None, # as relu is in _IGNORED_OPS
"aten::neg": None, # as relu is in _IGNORED_OPS
"aten::exp": None, # as relu is in _IGNORED_OPS
"aten::flip": None, # as permute is in _IGNORED_OPS
# "prim::PythonOp.CrossScan": None,
# "prim::PythonOp.CrossMerge": None,
"prim::PythonOp.SelectiveScanCuda": partial(selective_scan_flop_jit, backend="prefixsum", verbose=verbose),
}
model = copy.deepcopy(self)
model.cuda().eval()
input = torch.randn((1, *shape), device=next(model.parameters()).device)
params = parameter_count(model)[""]
Gflops, unsupported = flop_count(model=model, inputs=(input,), supported_ops=supported_ops)
del model, input
return sum(Gflops.values()) * 1e9
return f"params {params} GFLOPs {sum(Gflops.values())}"
# used to load ckpt from previous training code
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys,
error_msgs):
def check_name(src, state_dict: dict = state_dict, strict=False):
if strict:
if prefix + src in list(state_dict.keys()):
return True
else:
key = prefix + src
for k in list(state_dict.keys()):
if k.startswith(key):
return True
return False
def change_name(src, dst, state_dict: dict = state_dict, strict=False):
if strict:
if prefix + src in list(state_dict.keys()):
state_dict[prefix + dst] = state_dict[prefix + src]
state_dict.pop(prefix + src)
else:
key = prefix + src
for k in list(state_dict.keys()):
if k.startswith(key):
new_k = prefix + dst + k[len(key):]
state_dict[new_k] = state_dict[k]
state_dict.pop(k)
if check_name("pos_embed", strict=True):
srcEmb: torch.Tensor = state_dict[prefix + "pos_embed"]
state_dict[prefix + "pos_embed"] = F.interpolate(srcEmb.float(), size=self.pos_embed.shape[2:4],
align_corners=False, mode="bicubic").to(srcEmb.device)
change_name("patch_embed.proj", "patch_embed.0")
change_name("patch_embed.norm", "patch_embed.2")
for i in range(100):
for j in range(100):
change_name(f"layers.{i}.blocks.{j}.ln_1", f"layers.{i}.blocks.{j}.norm")
change_name(f"layers.{i}.blocks.{j}.self_attention", f"layers.{i}.blocks.{j}.op")
change_name("norm", "classifier.norm")
change_name("head", "classifier.head")
return super()._load_from_state_dict(state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys,
error_msgs)
# compatible with openmmlab
class Backbone_VSSM(VSSM):
def __init__(self, out_indices=(0, 1, 2, 3), pretrained=None, norm_layer="ln", **kwargs):
kwargs.update(norm_layer=norm_layer)
super().__init__(**kwargs)
self.channel_first = (norm_layer.lower() in ["bn", "ln2d"])
_NORMLAYERS = dict(
ln=nn.LayerNorm,
ln2d=LayerNorm2d,
bn=nn.BatchNorm2d,
)
norm_layer: nn.Module = _NORMLAYERS.get(norm_layer.lower(), None)
self.out_indices = out_indices
for i in out_indices:
layer = norm_layer(self.dims[i])
layer_name = f'outnorm{i}'
self.add_module(layer_name, layer)
del self.classifier
self.load_pretrained(pretrained)
def load_pretrained(self, ckpt=None, key="model"):
if ckpt is None:
return
try:
_ckpt = torch.load(open(ckpt, "rb"), map_location=torch.device("cpu"))
print(f"Successfully load ckpt {ckpt}")
incompatibleKeys = self.load_state_dict(_ckpt[key], strict=False)
print(incompatibleKeys)
except Exception as e:
print(f"Failed loading checkpoint form {ckpt}: {e}")
def forward(self, x):
def layer_forward(l, x):
x = l.blocks(x)
y = l.downsample(x)
return x, y
x = self.patch_embed(x)
outs = []
for i, layer in enumerate(self.layers):
o, x = layer_forward(layer, x) # (B, H, W, C)
if i in self.out_indices:
norm_layer = getattr(self, f'outnorm{i}')
out = norm_layer(o)
if not self.channel_first:
out = out.permute(0, 3, 1, 2)
outs.append(out.contiguous())
if len(self.out_indices) == 0:
return x
return outs
# =====================================================
def vanilla_vmamba_tiny():
return VSSM(
depths=[2, 2, 9, 2], dims=96, drop_path_rate=0.2,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=16, ssm_ratio=2.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=True, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v0",
mlp_ratio=0.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer="ln",
downsample_version="v1", patchembed_version="v1",
use_checkpoint=False, posembed=False, imgsize=224,
)
def vanilla_vmamba_small():
return VSSM(
depths=[2, 2, 27, 2], dims=96, drop_path_rate=0.3,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=16, ssm_ratio=2.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=True, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v0",
mlp_ratio=0.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer="ln",
downsample_version="v1", patchembed_version="v1",
use_checkpoint=False, posembed=False, imgsize=224,
)
def vanilla_vmamba_base():
return VSSM(
depths=[2, 2, 27, 2], dims=128, drop_path_rate=0.6,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=16, ssm_ratio=2.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=True, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v0",
mlp_ratio=0.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer="ln",
downsample_version="v1", patchembed_version="v1",
use_checkpoint=False, posembed=False, imgsize=224,
)
# =====================================================
def vmamba_tiny_s2l5(channel_first=True):
return VSSM(
depths=[2, 2, 5, 2], dims=96, drop_path_rate=0.2,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=1, ssm_ratio=2.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v05_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer=("ln2d" if channel_first else "ln"),
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
def vmamba_small_s2l15(channel_first=True):
return VSSM(
depths=[2, 2, 15, 2], dims=96, drop_path_rate=0.3,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=1, ssm_ratio=2.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v05_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer=("ln2d" if channel_first else "ln"),
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
def vmamba_base_s2l15(channel_first=True):
return VSSM(
depths=[2, 2, 15, 2], dims=128, drop_path_rate=0.6,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=1, ssm_ratio=2.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v05_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer=("ln2d" if channel_first else "ln"),
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
# =====================================================
def vmamba_tiny_s1l8(channel_first=True):
return VSSM(
depths=[2, 2, 8, 2], dims=96, drop_path_rate=0.2,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=1, ssm_ratio=1.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v05_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer=("ln2d" if channel_first else "ln"),
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
def vmamba_small_s1l20(channel_first=True):
return VSSM(
depths=[2, 2, 20, 2], dims=96, drop_path_rate=0.3,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=1, ssm_ratio=1.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v05_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer=("ln2d" if channel_first else "ln"),
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
def vmamba_base_s1l20(channel_first=True):
return VSSM(
depths=[2, 2, 20, 2], dims=128, drop_path_rate=0.5,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=1, ssm_ratio=1.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v05_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer=("ln2d" if channel_first else "ln"),
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
# mamba2 support =====================================================
def vmamba_tiny_m2():
return VSSM(
depths=[2, 2, 4, 2], dims=96, drop_path_rate=0.2,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=64, ssm_ratio=1.0, ssm_dt_rank="auto", ssm_act_layer="gelu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v2", forward_type="m0_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer="ln",
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
def vmamba_small_m2():
return VSSM(
depths=[2, 2, 12, 2], dims=96, drop_path_rate=0.3,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=64, ssm_ratio=1.0, ssm_dt_rank="auto", ssm_act_layer="gelu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v2", forward_type="m0_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer="ln",
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
def vmamba_base_m2():
return VSSM(
depths=[2, 2, 12, 2], dims=128, drop_path_rate=0.3,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=64, ssm_ratio=1.0, ssm_dt_rank="auto", ssm_act_layer="gelu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v2", forward_type="m0_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer="ln",
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
if __name__ == "__main__":
model = vmamba_tiny_s1l8()
# model = VSSM(
# depths=[2, 2, 4, 2], dims=96, drop_path_rate=0.2,
# patch_size=4, in_chans=3, num_classes=1000,
# ssm_d_state=64, ssm_ratio=1.0, ssm_dt_rank="auto", ssm_act_layer="gelu",
# ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
# ssm_init="v2", forward_type="m0_noz",
# mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
# patch_norm=True, norm_layer="ln",
# downsample_version="v3", patchembed_version="v2",
# use_checkpoint=False, posembed=False, imgsize=224,
# )
# print(parameter_count(model)[""])
# print(model.flops()) # wrong
# model.cuda().train()
model_weights_path = 'vssm1_tiny_0230s_ckpt_epoch_264.pth'
checkpoint = torch.load(model_weights_path, map_location='cpu')
# if 'model' in checkpoint:
# msg = model.load_state_dict(checkpoint['model'], strict=False)
# print(msg)
model.load_state_dict(checkpoint['model'], strict=False)
model.cuda().eval()
x = torch.randn(1, 3, 256, 256).cuda()
y, features = model(x)
print('finish')
def bench(model):
import time
inp = torch.randn((128, 3, 224, 224)).cuda()
for _ in range(30):
model(inp)
torch.cuda.synchronize()
tim = time.time()
for _ in range(30):
model(inp)
torch.cuda.synchronize()
tim1 = time.time() - tim
for _ in range(30):
model(inp).sum().backward()
torch.cuda.synchronize()
tim = time.time()
for _ in range(30):
model(inp).sum().backward()
torch.cuda.synchronize()
tim2 = time.time() - tim
return tim1 / 30, tim2 / 30
C3k2_MobileMambaBlock.py
在根目录下的ultralytics/nn/目录,新建一个mamba目录,然后新建一个以 C3k2_MobileMambaBlock为文件名的py文件, 把代码拷贝进去。
import torch
import itertools
import torch.nn as nn
from timm.layers import SqueezeExcite, trunc_normal_, DropPath
from .lib_mamba.vmambanew import SS2D
import torch.nn.functional as F
from functools import partial
import pywt
import pywt.data
def create_wavelet_filter(wave, in_size, out_size, type=torch.float):
w = pywt.Wavelet(wave)
dec_hi = torch.tensor(w.dec_hi[::-1], dtype=type)
dec_lo = torch.tensor(w.dec_lo[::-1], dtype=type)
dec_filters = torch.stack([dec_lo.unsqueeze(0) * dec_lo.unsqueeze(1),
dec_lo.unsqueeze(0) * dec_hi.unsqueeze(1),
dec_hi.unsqueeze(0) * dec_lo.unsqueeze(1),
dec_hi.unsqueeze(0) * dec_hi.unsqueeze(1)], dim=0)
dec_filters = dec_filters[:, None].repeat(in_size, 1, 1, 1)
rec_hi = torch.tensor(w.rec_hi[::-1], dtype=type).flip(dims=[0])
rec_lo = torch.tensor(w.rec_lo[::-1], dtype=type).flip(dims=[0])
rec_filters = torch.stack([rec_lo.unsqueeze(0) * rec_lo.unsqueeze(1),
rec_lo.unsqueeze(0) * rec_hi.unsqueeze(1),
rec_hi.unsqueeze(0) * rec_lo.unsqueeze(1),
rec_hi.unsqueeze(0) * rec_hi.unsqueeze(1)], dim=0)
rec_filters = rec_filters[:, None].repeat(out_size, 1, 1, 1)
return dec_filters, rec_filters
def wavelet_transform(x, filters):
b, c, h, w = x.shape
pad = (filters.shape[2] // 2 - 1, filters.shape[3] // 2 - 1)
x = F.conv2d(x, filters, stride=2, groups=c, padding=pad)
x = x.reshape(b, c, 4, h // 2, w // 2)
return x
def inverse_wavelet_transform(x, filters):
b, c, _, h_half, w_half = x.shape
pad = (filters.shape[2] // 2 - 1, filters.shape[3] // 2 - 1)
x = x.reshape(b, c * 4, h_half, w_half)
x = F.conv_transpose2d(x, filters, stride=2, groups=c, padding=pad)
return x
class MBWTConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=5, stride=1, bias=True, wt_levels=1, wt_type='db1',ssm_ratio=1,forward_type="v05",):
super(MBWTConv2d, self).__init__()
assert in_channels == out_channels
self.in_channels = in_channels
self.wt_levels = wt_levels
self.stride = stride
self.dilation = 1
self.wt_filter, self.iwt_filter = create_wavelet_filter(wt_type, in_channels, in_channels, torch.float)
self.wt_filter = nn.Parameter(self.wt_filter, requires_grad=False)
self.iwt_filter = nn.Parameter(self.iwt_filter, requires_grad=False)
self.wt_function = partial(wavelet_transform, filters=self.wt_filter)
self.iwt_function = partial(inverse_wavelet_transform, filters=self.iwt_filter)
self.global_atten =SS2D(d_model=in_channels, d_state=1,
ssm_ratio=ssm_ratio, initialize="v2", forward_type=forward_type, channel_first=True, k_group=2)
self.base_scale = _ScaleModule([1, in_channels, 1, 1])
self.wavelet_convs = nn.ModuleList(
[nn.Conv2d(in_channels * 4, in_channels * 4, kernel_size, padding='same', stride=1, dilation=1,
groups=in_channels * 4, bias=False) for _ in range(self.wt_levels)]
)
self.wavelet_scale = nn.ModuleList(
[_ScaleModule([1, in_channels * 4, 1, 1], init_scale=0.1) for _ in range(self.wt_levels)]
)
if self.stride > 1:
self.stride_filter = nn.Parameter(torch.ones(in_channels, 1, 1, 1), requires_grad=False)
self.do_stride = lambda x_in: F.conv2d(x_in, self.stride_filter, bias=None, stride=self.stride,
groups=in_channels)
else:
self.do_stride = None
def forward(self, x):
x_ll_in_levels = []
x_h_in_levels = []
shapes_in_levels = []
curr_x_ll = x
for i in range(self.wt_levels):
curr_shape = curr_x_ll.shape
shapes_in_levels.append(curr_shape)
if (curr_shape[2] % 2 > 0) or (curr_shape[3] % 2 > 0):
curr_pads = (0, curr_shape[3] % 2, 0, curr_shape[2] % 2)
curr_x_ll = F.pad(curr_x_ll, curr_pads)
curr_x = self.wt_function(curr_x_ll)
curr_x_ll = curr_x[:, :, 0, :, :]
shape_x = curr_x.shape
curr_x_tag = curr_x.reshape(shape_x[0], shape_x[1] * 4, shape_x[3], shape_x[4])
curr_x_tag = self.wavelet_scale[i](self.wavelet_convs[i](curr_x_tag))
curr_x_tag = curr_x_tag.reshape(shape_x)
x_ll_in_levels.append(curr_x_tag[:, :, 0, :, :])
x_h_in_levels.append(curr_x_tag[:, :, 1:4, :, :])
next_x_ll = 0
for i in range(self.wt_levels - 1, -1, -1):
curr_x_ll = x_ll_in_levels.pop()
curr_x_h = x_h_in_levels.pop()
curr_shape = shapes_in_levels.pop()
curr_x_ll = curr_x_ll + next_x_ll
curr_x = torch.cat([curr_x_ll.unsqueeze(2), curr_x_h], dim=2)
next_x_ll = self.iwt_function(curr_x)
next_x_ll = next_x_ll[:, :, :curr_shape[2], :curr_shape[3]]
x_tag = next_x_ll
assert len(x_ll_in_levels) == 0
x = self.base_scale(self.global_atten(x))
x = x + x_tag
if self.do_stride is not None:
x = self.do_stride(x)
return x
class _ScaleModule(nn.Module):
def __init__(self, dims, init_scale=1.0, init_bias=0):
super(_ScaleModule, self).__init__()
self.dims = dims
self.weight = nn.Parameter(torch.ones(*dims) * init_scale)
self.bias = None
def forward(self, x):
return torch.mul(self.weight, x)
class DWConv2d_BN_ReLU(nn.Sequential):
def __init__(self, in_channels, out_channels, kernel_size=3, bn_weight_init=1):
super().__init__()
self.add_module('dwconv3x3',
nn.Conv2d(in_channels, in_channels, kernel_size=kernel_size, stride=1, padding=kernel_size//2, groups=in_channels,
bias=False))
self.add_module('bn1', nn.BatchNorm2d(in_channels))
self.add_module('relu', nn.ReLU(inplace=True))
self.add_module('dwconv1x1',
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, groups=in_channels,
bias=False))
self.add_module('bn2', nn.BatchNorm2d(out_channels))
# Initialize batch norm weights
nn.init.constant_(self.bn1.weight, bn_weight_init)
nn.init.constant_(self.bn1.bias, 0)
nn.init.constant_(self.bn2.weight, bn_weight_init)
nn.init.constant_(self.bn2.bias, 0)
@torch.no_grad()
def fuse(self):
# Fuse dwconv3x3 and bn1
dwconv3x3, bn1, relu, dwconv1x1, bn2 = self._modules.values()
w1 = bn1.weight / (bn1.running_var + bn1.eps) ** 0.5
w1 = dwconv3x3.weight * w1[:, None, None, None]
b1 = bn1.bias - bn1.running_mean * bn1.weight / (bn1.running_var + bn1.eps) ** 0.5
fused_dwconv3x3 = nn.Conv2d(w1.size(1) * dwconv3x3.groups, w1.size(0), w1.shape[2:], stride=dwconv3x3.stride,
padding=dwconv3x3.padding, dilation=dwconv3x3.dilation, groups=dwconv3x3.groups,
device=dwconv3x3.weight.device)
fused_dwconv3x3.weight.data.copy_(w1)
fused_dwconv3x3.bias.data.copy_(b1)
# Fuse dwconv1x1 and bn2
w2 = bn2.weight / (bn2.running_var + bn2.eps) ** 0.5
w2 = dwconv1x1.weight * w2[:, None, None, None]
b2 = bn2.bias - bn2.running_mean * bn2.weight / (bn2.running_var + bn2.eps) ** 0.5
fused_dwconv1x1 = nn.Conv2d(w2.size(1) * dwconv1x1.groups, w2.size(0), w2.shape[2:], stride=dwconv1x1.stride,
padding=dwconv1x1.padding, dilation=dwconv1x1.dilation, groups=dwconv1x1.groups,
device=dwconv1x1.weight.device)
fused_dwconv1x1.weight.data.copy_(w2)
fused_dwconv1x1.bias.data.copy_(b2)
# Create a new sequential model with fused layers
fused_model = nn.Sequential(fused_dwconv3x3, relu, fused_dwconv1x1)
return fused_model
class Conv2d_BN(torch.nn.Sequential):
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
groups=1, bn_weight_init=1,):
super().__init__()
self.add_module('c', torch.nn.Conv2d(
a, b, ks, stride, pad, dilation, groups, bias=False))
self.add_module('bn', torch.nn.BatchNorm2d(b))
torch.nn.init.constant_(self.bn.weight, bn_weight_init)
torch.nn.init.constant_(self.bn.bias, 0)
@torch.no_grad()
def fuse(self):
c, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps) ** 0.5
w = c.weight * w[:, None, None, None]
b = bn.bias - bn.running_mean * bn.weight / \
(bn.running_var + bn.eps) ** 0.5
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(
0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation,
groups=self.c.groups)
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
class BN_Linear(torch.nn.Sequential):
def __init__(self, a, b, bias=True, std=0.02):
super().__init__()
self.add_module('bn', torch.nn.BatchNorm1d(a))
self.add_module('l', torch.nn.Linear(a, b, bias=bias))
trunc_normal_(self.l.weight, std=std)
if bias:
torch.nn.init.constant_(self.l.bias, 0)
@torch.no_grad()
def fuse(self):
bn, l = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps) ** 0.5
b = bn.bias - self.bn.running_mean * \
self.bn.weight / (bn.running_var + bn.eps) ** 0.5
w = l.weight * w[None, :]
if l.bias is None:
b = b @ self.l.weight.T
else:
b = (l.weight @ b[:, None]).view(-1) + self.l.bias
m = torch.nn.Linear(w.size(1), w.size(0))
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
class PatchMerging(torch.nn.Module):
def __init__(self, dim, out_dim):
super().__init__()
hid_dim = int(dim * 4)
self.conv1 = Conv2d_BN(dim, hid_dim, 1, 1, 0, )
self.act = torch.nn.ReLU()
self.conv2 = Conv2d_BN(hid_dim, hid_dim, 3, 2, 1, groups=hid_dim,)
self.se = SqueezeExcite(hid_dim, .25)
self.conv3 = Conv2d_BN(hid_dim, out_dim, 1, 1, 0,)
def forward(self, x):
x = self.conv3(self.se(self.act(self.conv2(self.act(self.conv1(x))))))
return x
class Residual(torch.nn.Module):
def __init__(self, m, drop=0.):
super().__init__()
self.m = m
self.drop = drop
def forward(self, x):
if self.training and self.drop > 0:
return x + self.m(x) * torch.rand(x.size(0), 1, 1, 1,
device=x.device).ge_(self.drop).div(1 - self.drop).detach()
else:
return x + self.m(x)
class FFN(torch.nn.Module):
def __init__(self, ed, h):
super().__init__()
self.pw1 = Conv2d_BN(ed, h)
self.act = torch.nn.ReLU()
self.pw2 = Conv2d_BN(h, ed, bn_weight_init=0)
def forward(self, x):
x = self.pw2(self.act(self.pw1(x)))
return x
def nearest_multiple_of_16(n):
if n % 16 == 0:
return n
else:
lower_multiple = (n // 16) * 16
upper_multiple = lower_multiple + 16
if (n - lower_multiple) < (upper_multiple - n):
return lower_multiple
else:
return upper_multiple
class MobileMambaModule(torch.nn.Module):
def __init__(self, dim, global_ratio=0.25, local_ratio=0.25,
kernels=3, ssm_ratio=1, forward_type="v052d",):
super().__init__()
self.dim = dim
self.global_channels = nearest_multiple_of_16(int(global_ratio * dim))
if self.global_channels + int(local_ratio * dim) > dim:
self.local_channels = dim - self.global_channels
else:
self.local_channels = int(local_ratio * dim)
self.identity_channels = self.dim - self.global_channels - self.local_channels
if self.local_channels != 0:
self.local_op = DWConv2d_BN_ReLU(self.local_channels, self.local_channels, kernels)
else:
self.local_op = nn.Identity()
if self.global_channels != 0:
self.global_op = MBWTConv2d(self.global_channels, self.global_channels, kernels, wt_levels=1, ssm_ratio=ssm_ratio, forward_type=forward_type,)
else:
self.global_op = nn.Identity()
self.proj = torch.nn.Sequential(torch.nn.ReLU(), Conv2d_BN(
dim, dim, bn_weight_init=0,))
def forward(self, x): # x (B,C,H,W)
x1, x2, x3 = torch.split(x, [self.global_channels, self.local_channels, self.identity_channels], dim=1)
x1 = self.global_op(x1)
x2 = self.local_op(x2)
x = self.proj(torch.cat([x1, x2, x3], dim=1))
return x
class MobileMambaBlockWindow(torch.nn.Module):
def __init__(self, dim, global_ratio=0.25, local_ratio=0.25,
kernels=5, ssm_ratio=1, forward_type="v052d",):
super().__init__()
self.dim = dim
self.attn = MobileMambaModule(dim, global_ratio=global_ratio, local_ratio=local_ratio,
kernels=kernels, ssm_ratio=ssm_ratio, forward_type=forward_type,)
def forward(self, x):
x = self.attn(x)
return x
class MobileMambaBlock(torch.nn.Module):
def __init__(self, ed, global_ratio=0.25, local_ratio=0.25,
kernels=5, drop_path=0., has_skip=True, ssm_ratio=1, forward_type="v052d"):
super().__init__()
self.dw0 = Residual(Conv2d_BN(ed, ed, 3, 1, 1, groups=ed, bn_weight_init=0.))
self.ffn0 = Residual(FFN(ed, int(ed * 2)))
self.mixer = Residual(MobileMambaBlockWindow(ed, global_ratio=global_ratio, local_ratio=local_ratio, kernels=kernels, ssm_ratio=ssm_ratio,forward_type=forward_type))
self.dw1 = Residual(Conv2d_BN(ed, ed, 3, 1, 1, groups=ed, bn_weight_init=0.,))
self.ffn1 = Residual(FFN(ed, int(ed * 2)))
self.has_skip = has_skip
self.drop_path = DropPath(drop_path) if drop_path else nn.Identity()
def forward(self, x):
shortcut = x
x = self.ffn1(self.dw1(self.mixer(self.ffn0(self.dw0(x)))))
x = (shortcut + self.drop_path(x)) if self.has_skip else x
return x
def autopad(k, p=None, d=1):
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU()
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a standard bottleneck module with optional shortcut connection and configurable parameters."""
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""Applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initializes a CSP bottleneck with 2 convolutions and n Bottleneck blocks for faster processing."""
super().__init__()
self.c = int(c2 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
class C3(nn.Module):
"""CSP Bottleneck with 3 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
"""Initialize the CSP Bottleneck with given channels, number, shortcut, groups, and expansion values."""
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))
def forward(self, x):
"""Forward pass through the CSP bottleneck with 2 convolutions."""
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
class C3k(C3):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3):
"""Initializes the C3k module with specified channels, number of layers, and configurations."""
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
class C3k2(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
"""Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks."""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
)
class C3k_MobileMambaBlock(C3k):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=3):
super().__init__(c1, c2, n, shortcut, g, e, k)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(MobileMambaBlock(c_) for _ in range(n)))
class C3k2_MobileMambaBlock(C3k2):
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
super().__init__(c1, c2, n, c3k, e, g, shortcut)
self.m = nn.ModuleList(C3k_MobileMambaBlock(self.c, self.c, n, shortcut, g) if c3k else MobileMambaBlock(self.c) for _ in range(n))注册
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.mamba.C3k2_MobileMambaBlock import C3k2_MobileMambaBlock
步骤2
修改def parse_model(d, ch, verbose=True):
C3k2_MobileMambaBlock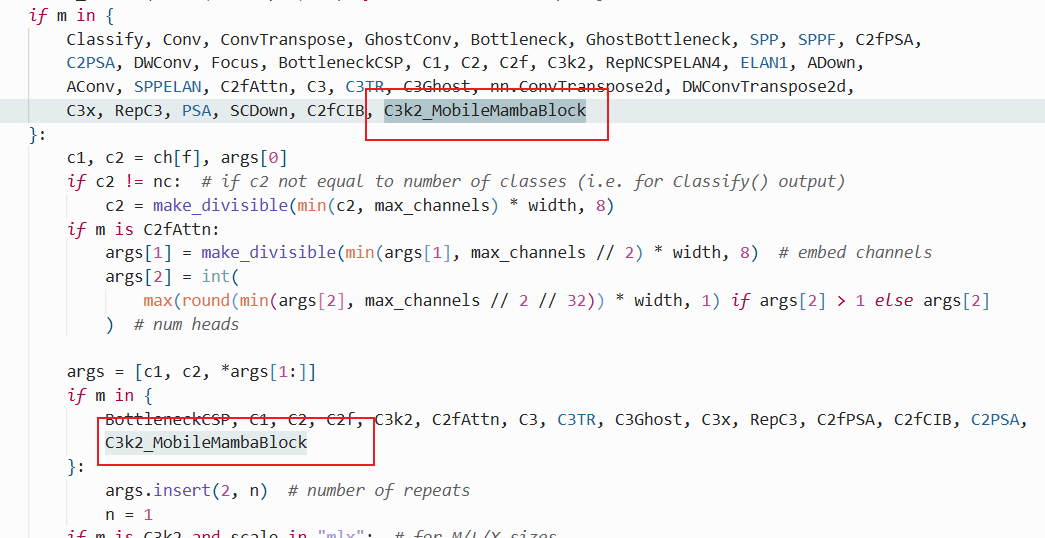
配置yolo11-C3k2_MobileMambaBlock.yaml
ultralytics/cfg/models/11/yolo11-C3k2_MobileMambaBlock.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2_MobileMambaBlock, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2_MobileMambaBlock, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2_MobileMambaBlock, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2_MobileMambaBlock, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('/root/ultralytics-8.3.9/ultralytics/cfg/models/11/yolo11-C3k2_MobileMambaBlock.yaml')
# 修改为自己的数据集地址
model.train(data='/root/ultralytics-8.3.9/ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='SGD',
amp=True,
project='runs/train',
name='C3k2_MobileMambaBlock',
)
结果