YOLOv11改进 – Mamba C3k2融合 VSS Block (Visual State Space Block) 视觉状态空间块,优化多尺度特征融合
# 前言
本文介绍了将Mamba架构与U型网络结合的Mamba - UNet,用于医学图像分割。传统CNN和ViT在建模医学图像长距离依赖关系上存在局限,而Mamba - UNet受Mamba架构启发,采用基于纯视觉曼巴(VMamba)的编解码器结构并融入跳跃连接,还引入新颖集成机制,促进全面特征学习。VSS Block是Mamba - UNet的核心功能模块,通过两条路径并行处理和融合图像特征,且无“位置编码”和“MLP层”,更省资源、精度更高。 将其引入YOLOv11,与C3k2进行融合
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
介绍

摘要
用户需要将计算机相关论文英文摘要翻译成中文,调用 zhuanyelingyufanyiAPI-fieldtranslate 函数获取专业的学术领域翻译。摘要:在医学图像分析的最新进展中,卷积神经网络(CNN)和视觉变换器(ViT)树立了重要的标杆。前者通过卷积运算在捕捉局部特征方面表现出色,而后者则利用自注意力机制实现了卓越的全局上下文理解。然而,这两种架构在有效建模医学图像中的长距离依赖关系方面都存在局限性,而长距离依赖关系对于精确分割至关重要。受曼巴(Mamba)架构的启发,该架构作为一种状态空间模型(SSM),以其在处理长序列和全局上下文信息方面的高效计算能力而闻名,我们提出了曼巴 - U 型网络(Mamba - UNet),这是一种将医学图像分割中的 U 型网络与曼巴架构能力相结合的新型架构。曼巴 - U 型网络采用了基于纯视觉曼巴(VMamba)的编解码器结构,并融入了跳跃连接,以在网络的不同尺度上保留空间信息。这种设计促进了全面的特征学习过程,能够捕捉医学图像中的复杂细节和更广泛的语义上下文。我们在 VMamba 模块中引入了一种新颖的集成机制,以确保编码器和解码器路径之间的无缝连接和信息流动,从而提高分割性能。我们在公开可用的 ACDC 磁共振心脏分割数据集和突触 CT 腹部分割数据集上进行了实验。结果表明,在相同的超参数设置下,曼巴 - U 型网络在医学图像分割方面优于多种类型的 U 型网络。源代码和基线实现可在 https://github.com/ziyangwang007/MambaUNet 上获取。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
VSS Block(Visual State Space Block,视觉状态空间块)是Mamba-UNet模型的核心功能模块,相当于模型的“特征提取核心”——整个Mamba-UNet的编码器、解码器、瓶颈层都靠它来学习医学图像的关键特征(比如器官轮廓、病变细节、全局位置关联),是模型兼顾“分割精度”和“计算效率”的关键。
用通俗的方式拆解它的核心信息:
1. 本质:给图像任务定制的“高效特征处理器”
VSS Block的核心灵感来自“状态空间模型(SSM)”——这种技术原本擅长处理文字这类长序列数据,能高效捕捉全局关联(比如一句话里前后词语的关系),还不怎么费资源。后来研究者把它改成了“视觉版”(结合Visual Mamba的设计),专门适配图像数据,就成了VSS Block。
简单说:它把医学图像转换成有序的“图像块序列”,用SSM的高效全局捕捉能力,加上卷积的局部细节捕捉能力,让模型既能看清“小病灶”,又能理清“器官之间的远距离关联”(比如心脏左右心室的位置关系)。
2. 内部工作流程
VSS Block的结构不复杂,核心是“两条路径并行处理+融合”,避免单一处理方式的短板:
- 先把输入的图像特征做一次“线性映射”(相当于统一数据格式,方便后续处理);
- 分成两条路径:
- 路径1:先做“深度卷积”(专门抓局部细节,比如病灶的边缘),再经过“激活函数”(筛选有用特征),然后进入“SS2D模块”(专门捕捉全局关联,比如器官的整体形态),最后做“层归一化”(稳定数据,避免出错);
- 路径2:直接经过“激活函数”(快速保留基础特征);
- 把两条路径的结果合并,输出处理后的特征。
3. 关键设计:为啥比传统模块更适合医学图像?
它有两个“省资源又提精度”的设计,专门针对医学图像的需求:
- 没有“位置编码”:传统视觉Transformer需要额外给图像块加“位置信息”(比如“这个块在图像左上角”),VSS Block靠“交叉扫描模块(CSM)”把图像转换成有序序列时,已经自带了位置关联,不用额外计算,省了资源;
- 没有“MLP层”:传统Transformer的“多层感知机(MLP)”虽然能增强特征,但计算量大,VSS Block直接去掉了这一步,用“卷积+SSM”的组合替代,结构更精简,能在相同计算成本下,堆叠更多模块提升性能(比如编码器、解码器各用2个VSS Block,就能达到很好的特征学习效果)。
4. 在Mamba-UNet中的作用
VSS Block不是孤立的,而是贯穿模型核心:
- 编码器里:每个阶段用2个VSS Block,配合“图像块合并”(缩小图像、提升特征维度),逐步提取高层核心特征;
- 解码器里:每个阶段也用2个VSS Block,配合“图像块扩展”(放大图像、还原细节),把核心特征转换成和原始图像尺寸匹配的分割结果;
- 瓶颈层里:用2个VSS Block,处理最浓缩的全局特征,衔接编码器和解码器,避免特征传递时丢失关键信息。
class VSSBlock(nn.Module):
def __init__(
self,
hidden_dim: int = 0,
drop_path: float = 0,
norm_layer: Callable[..., torch.nn.Module] = partial(nn.LayerNorm, eps=1e-6),
attn_drop_rate: float = 0,
d_state: int = 16,
**kwargs,
):
super().__init__()
self.ln_1 = norm_layer(hidden_dim)
self.self_attention = SS2D(d_model=hidden_dim, dropout=attn_drop_rate, d_state=d_state, **kwargs)
self.drop_path = DropPath(drop_path)
def forward(self, input: torch.Tensor):
x = input + self.drop_path(self.self_attention(self.ln_1(input)))
return xYOLO11引入代码
在根目录下的ultralytics/nn/目录,新建一个mamba目录,然后新建一个以 C3k2_VSSBlock为文件名的py文件, 把代码拷贝进去。
import torch, math
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange, repeat
from functools import partial
from typing import Optional, Callable
from timm.layers import DropPath
try:
from mamba_ssm.ops.selective_scan_interface import selective_scan_fn, selective_scan_ref
except:
pass
try:
from mamba_ssm.modules.mamba2_simple import Mamba2Simple
except:
pass
class SS2D(nn.Module):
def __init__(
self,
d_model,
d_state=16,
# d_state="auto", # 20240109
d_conv=3,
expand=2,
dt_rank="auto",
dt_min=0.001,
dt_max=0.1,
dt_init="random",
dt_scale=1.0,
dt_init_floor=1e-4,
dropout=0.,
conv_bias=True,
bias=False,
device=None,
dtype=None,
**kwargs,
):
factory_kwargs = {"device": device, "dtype": dtype}
super().__init__()
self.d_model = d_model
self.d_state = d_state
# self.d_state = math.ceil(self.d_model / 6) if d_state == "auto" else d_model # 20240109
self.d_conv = d_conv
self.expand = expand
self.d_inner = int(self.expand * self.d_model)
self.dt_rank = math.ceil(self.d_model / 16) if dt_rank == "auto" else dt_rank
self.in_proj = nn.Linear(self.d_model, self.d_inner * 2, bias=bias, **factory_kwargs)
self.conv2d = nn.Conv2d(
in_channels=self.d_inner,
out_channels=self.d_inner,
groups=self.d_inner,
bias=conv_bias,
kernel_size=d_conv,
padding=(d_conv - 1) // 2,
**factory_kwargs,
)
self.act = nn.SiLU()
self.x_proj = (
nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs),
nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs),
nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs),
nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs),
)
self.x_proj_weight = nn.Parameter(torch.stack([t.weight for t in self.x_proj], dim=0)) # (K=4, N, inner)
del self.x_proj
self.dt_projs = (
self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, **factory_kwargs),
self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, **factory_kwargs),
self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, **factory_kwargs),
self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, **factory_kwargs),
)
self.dt_projs_weight = nn.Parameter(torch.stack([t.weight for t in self.dt_projs], dim=0)) # (K=4, inner, rank)
self.dt_projs_bias = nn.Parameter(torch.stack([t.bias for t in self.dt_projs], dim=0)) # (K=4, inner)
del self.dt_projs
self.A_logs = self.A_log_init(self.d_state, self.d_inner, copies=4, merge=True) # (K=4, D, N)
self.Ds = self.D_init(self.d_inner, copies=4, merge=True) # (K=4, D, N)
self.forward_core = self.forward_corev0
self.out_norm = nn.LayerNorm(self.d_inner)
self.out_proj = nn.Linear(self.d_inner, self.d_model, bias=bias, **factory_kwargs)
self.dropout = nn.Dropout(dropout) if dropout > 0. else None
@staticmethod
def dt_init(dt_rank, d_inner, dt_scale=1.0, dt_init="random", dt_min=0.001, dt_max=0.1, dt_init_floor=1e-4, **factory_kwargs):
dt_proj = nn.Linear(dt_rank, d_inner, bias=True, **factory_kwargs)
# Initialize special dt projection to preserve variance at initialization
dt_init_std = dt_rank**-0.5 * dt_scale
if dt_init == "constant":
nn.init.constant_(dt_proj.weight, dt_init_std)
elif dt_init == "random":
nn.init.uniform_(dt_proj.weight, -dt_init_std, dt_init_std)
else:
raise NotImplementedError
# Initialize dt bias so that F.softplus(dt_bias) is between dt_min and dt_max
dt = torch.exp(
torch.rand(d_inner, **factory_kwargs) * (math.log(dt_max) - math.log(dt_min))
+ math.log(dt_min)
).clamp(min=dt_init_floor)
# Inverse of softplus: https://github.com/pytorch/pytorch/issues/72759
inv_dt = dt + torch.log(-torch.expm1(-dt))
with torch.no_grad():
dt_proj.bias.copy_(inv_dt)
# Our initialization would set all Linear.bias to zero, need to mark this one as _no_reinit
dt_proj.bias._no_reinit = True
return dt_proj
@staticmethod
def A_log_init(d_state, d_inner, copies=1, device=None, merge=True):
# S4D real initialization
A = repeat(
torch.arange(1, d_state + 1, dtype=torch.float32, device=device),
"n -> d n",
d=d_inner,
).contiguous()
A_log = torch.log(A) # Keep A_log in fp32
if copies > 1:
A_log = repeat(A_log, "d n -> r d n", r=copies)
if merge:
A_log = A_log.flatten(0, 1)
A_log = nn.Parameter(A_log)
A_log._no_weight_decay = True
return A_log
@staticmethod
def D_init(d_inner, copies=1, device=None, merge=True):
# D "skip" parameter
D = torch.ones(d_inner, device=device)
if copies > 1:
D = repeat(D, "n1 -> r n1", r=copies)
if merge:
D = D.flatten(0, 1)
D = nn.Parameter(D) # Keep in fp32
D._no_weight_decay = True
return D
def forward_corev0(self, x: torch.Tensor):
self.selective_scan = selective_scan_fn
B, C, H, W = x.shape
L = H * W
K = 4
x_hwwh = torch.stack([x.view(B, -1, L), torch.transpose(x, dim0=2, dim1=3).contiguous().view(B, -1, L)], dim=1).view(B, 2, -1, L)
xs = torch.cat([x_hwwh, torch.flip(x_hwwh, dims=[-1])], dim=1) # (b, k, d, l)
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs.view(B, K, -1, L), self.x_proj_weight)
# x_dbl = x_dbl + self.x_proj_bias.view(1, K, -1, 1)
dts, Bs, Cs = torch.split(x_dbl, [self.dt_rank, self.d_state, self.d_state], dim=2)
dts = torch.einsum("b k r l, k d r -> b k d l", dts.view(B, K, -1, L), self.dt_projs_weight)
xs = xs.float().view(B, -1, L) # (b, k * d, l)
dts = dts.contiguous().float().view(B, -1, L) # (b, k * d, l)
Bs = Bs.float().view(B, K, -1, L) # (b, k, d_state, l)
Cs = Cs.float().view(B, K, -1, L) # (b, k, d_state, l)
Ds = self.Ds.float().view(-1) # (k * d)
As = -torch.exp(self.A_logs.float()).view(-1, self.d_state) # (k * d, d_state)
dt_projs_bias = self.dt_projs_bias.float().view(-1) # (k * d)
out_y = self.selective_scan(
xs, dts,
As, Bs, Cs, Ds, z=None,
delta_bias=dt_projs_bias,
delta_softplus=True,
return_last_state=False,
).view(B, K, -1, L)
assert out_y.dtype == torch.float
inv_y = torch.flip(out_y[:, 2:4], dims=[-1]).view(B, 2, -1, L)
wh_y = torch.transpose(out_y[:, 1].view(B, -1, W, H), dim0=2, dim1=3).contiguous().view(B, -1, L)
invwh_y = torch.transpose(inv_y[:, 1].view(B, -1, W, H), dim0=2, dim1=3).contiguous().view(B, -1, L)
y = out_y[:, 0] + inv_y[:, 0] + wh_y + invwh_y
y = torch.transpose(y, dim0=1, dim1=2).contiguous().view(B, H, W, -1).to(x.dtype)
y = self.out_norm(y).to(x.dtype)
return y
def forward(self, x: torch.Tensor, **kwargs):
B, H, W, C = x.shape
xz = self.in_proj(x)
x, z = xz.chunk(2, dim=-1) # (b, h, w, d)
x = x.permute(0, 3, 1, 2).contiguous()
x = self.act(self.conv2d(x)) # (b, d, h, w)
y = self.forward_core(x)
y = y * F.silu(z)
out = self.out_proj(y)
if self.dropout is not None:
out = self.dropout(out)
return out
class VSSBlock(nn.Module):
def __init__(
self,
hidden_dim: int = 0,
drop_path: float = 0,
norm_layer: Callable[..., torch.nn.Module] = partial(nn.LayerNorm, eps=1e-6),
attn_drop_rate: float = 0,
d_state: int = 16,
**kwargs,
):
super().__init__()
self.ln_1 = norm_layer(hidden_dim)
self.self_attention = SS2D(d_model=hidden_dim, dropout=attn_drop_rate, d_state=d_state, **kwargs)
self.drop_path = DropPath(drop_path)
def forward(self, input: torch.Tensor):
input = input.permute((0, 2, 3, 1))
x = input + self.drop_path(self.self_attention(self.ln_1(input)))
return x.permute((0, 3, 1, 2))
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a standard bottleneck module with optional shortcut connection and configurable parameters."""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""Applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initializes a CSP bottleneck with 2 convolutions and n Bottleneck blocks for faster processing."""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
class C3(nn.Module):
"""CSP Bottleneck with 3 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
"""Initialize the CSP Bottleneck with given channels, number, shortcut, groups, and expansion values."""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))
def forward(self, x):
"""Forward pass through the CSP bottleneck with 2 convolutions."""
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
class C3k(C3):
"""C3k is a CSP bottleneck module with customizable kernel sizes for feature extraction in neural networks."""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3):
"""Initializes the C3k module with specified channels, number of layers, and configurations."""
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
# self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
class C3k2(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
"""Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks."""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
)
class Bottleneck_VSSBlock(Bottleneck):
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
super().__init__(c1, c2, shortcut, g, k, e)
c_ = int(c2 * e) # hidden channels
self.cv2 = VSSBlock(c2)
class C3k_VSSBlock(C3k):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=3):
super().__init__(c1, c2, n, shortcut, g, e, k)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(Bottleneck_VSSBlock(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
class C3k2_VSSBlock(C3k2):
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
super().__init__(c1, c2, n, c3k, e, g, shortcut)
self.m = nn.ModuleList(C3k_VSSBlock(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck_VSSBlock(self.c, self.c, shortcut, g, k=(3, 3), e=1.0) for _ in range(n))
注册
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.mamba.C3k2_VSSBlock import C3k2_VSSBlock
步骤2
修改def parse_model(d, ch, verbose=True):
C3k2_VSSBlock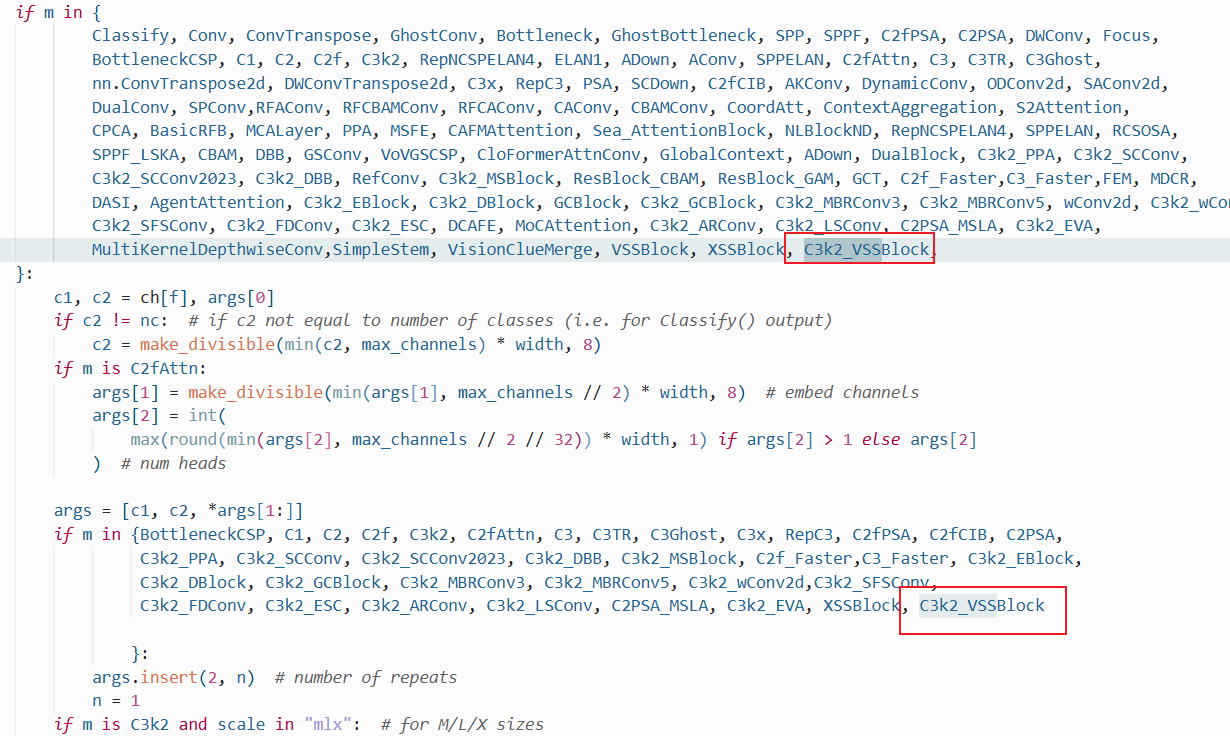
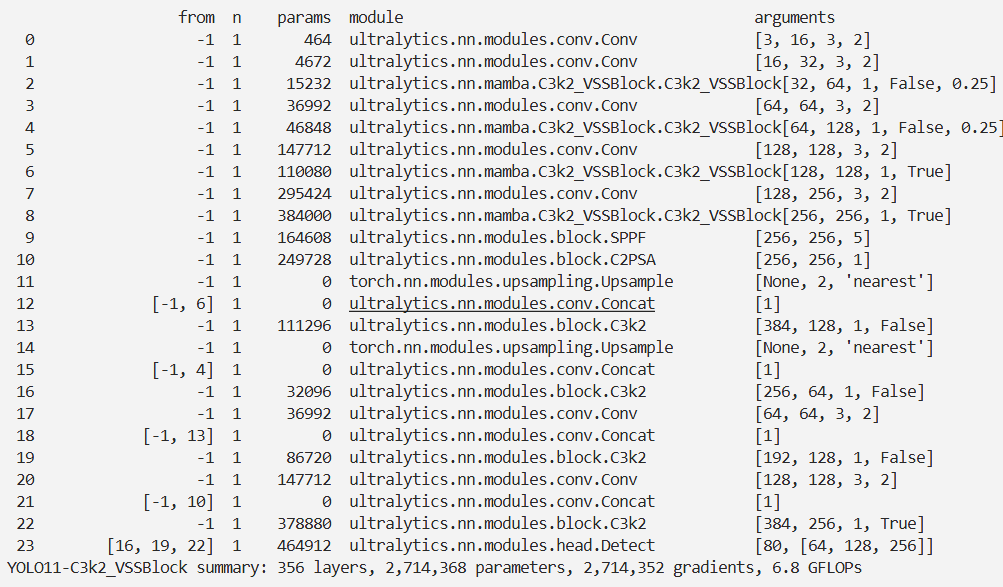
配置yolo11-C3k2_VSSBlock.yaml
ultralytics/cfg/models/11/yolo11-C3k2_VSSBlock.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2_VSSBlock, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2_VSSBlock, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2_VSSBlock, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2_VSSBlock, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('/root/ultralytics-main/ultralytics/cfg/models/11/yolo11-C3k2_VSSBlock.yaml')
# 修改为自己的数据集地址
model.train(data='/root/ultralytics-main/ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='SGD',
amp=True,
project='runs/train',
name='C3k2_VSSBlock',
)
结果