YOLO26改进 – 卷积Conv ODConv全维度动态卷积:四维注意力机制赋能特征提取,增强多尺度感知
前言
本文介绍了全方位动态卷积(ODConv)及其在YOLO26中的结合。现有动态卷积工作仅赋予卷积核一个维度动态属性,而ODConv利用新颖的多维注意力机制和并行策略,在卷积核空间的四个维度学习互补注意力。它可作为常规卷积的替代品插入多种CNN架构。我们将ODConv集成进YOLO26,在 MS - COCO数据集上的实验表明,ODConv能带来显著的准确性提升,减少额外参数。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
介绍

摘要
传统卷积神经网络(CNN)普遍采用静态卷积核训练范式,每个卷积层学习单一固定权重的卷积核。近期动态卷积研究表明,通过输入自适应的注意力机制学习多个卷积核的线性组合,可在维持推理效率的同时显著提升轻量级CNN的性能。然而,现有研究仅在卷积核数量这一维度引入动态特性,而忽略了卷积操作中的其他三个关键维度:卷积核空间大小、输入通道数和输出通道数。
针对这一局限性,本研究提出全方位动态卷积(Omni-Dimensional Dynamic Convolution, ODConv),作为一种更具普适性与优雅性的动态卷积设计范式。ODConv创新性地引入多维注意力机制及并行计算策略,实现了在卷积核四维参数空间的全方位动态学习,有效捕获不同维度上的互补表征能力。作为常规卷积的直接替代方案,ODConv可无缝集成至多种CNN架构中。
在ImageNet与MS-COCO等大规模数据集上的系统实验表明,ODConv为各类CNN骨干网络带来了显著且稳定的性能提升。具体而言,在ImageNet分类基准上,ODConv使MobileNetV2系列网络的Top-1准确率提升了3.77%~5.71%,ResNet系列网络提升了1.86%~3.72%。值得注意的是,得益于其增强的特征表达能力,即使仅配置单个卷积核的ODConv也能与现有多核动态卷积方法相媲美或超越其性能,同时大幅降低了额外参数开销。此外,与其他聚焦于输出特征调制或卷积权重调整的注意力机制相比,ODConv展现出更优的性能和更高的效率。
创新点
ODConv是一种更通用但更优雅的动态卷积设计,它利用一种新颖的多维注意力机制和并行策略来学习卷积核的补充注意力,这些注意力涉及卷积核空间在任何卷积层的所有四个维度(即每个卷积核的空间大小、输入通道数、输出通道数和卷积核数量)。作为常规卷积的直接替代品,ODConv可以嵌入到多种CNN架构中。在ImageNet基准上进行了基础实验,在MS-COCO基准上进行了下游实验。
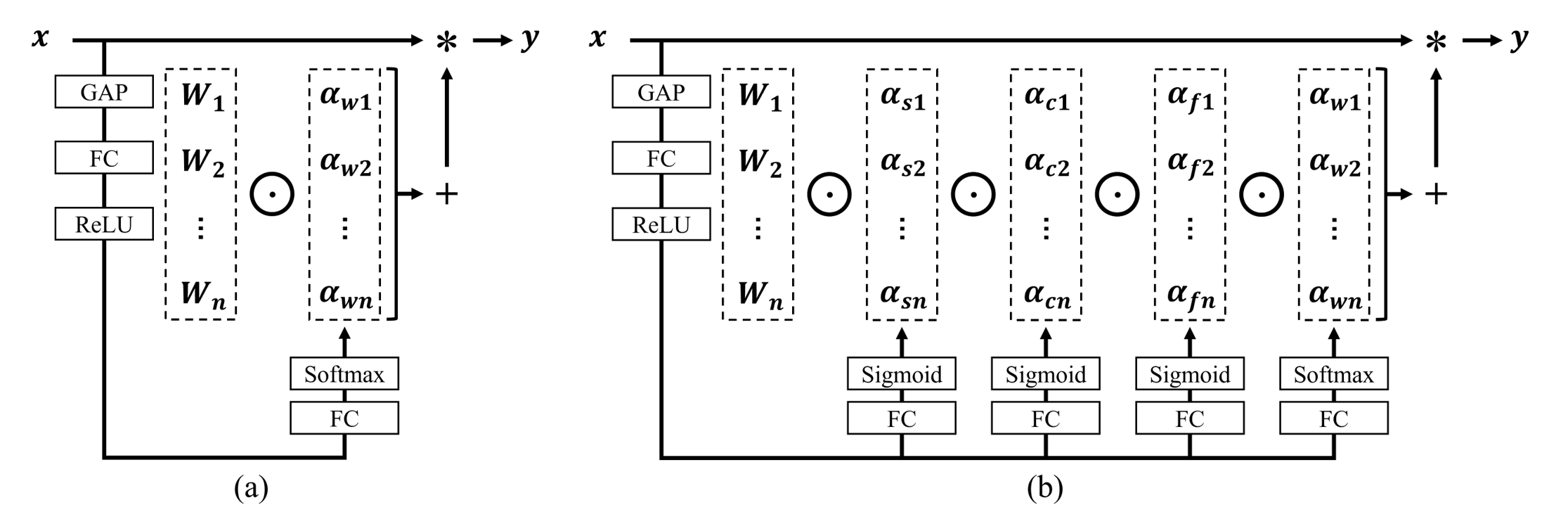
(a) DyConv(CondConv使用GAP+FC+Sigmoid)与(b) ODConv的示意性比较。与CondConv和DyConv不同,后者为卷积核 $W_{i}$计算单一的注意力标量 $α_{wi}$,ODConv利用一种新颖的多维注意力机制,以并行方式计算 ( Wi ) 在卷积核空间的所有四个维度上的四种类型的注意力 $α_{si}$, $α_{ci}$, $α_{fi}$和 $α\{wi}$。
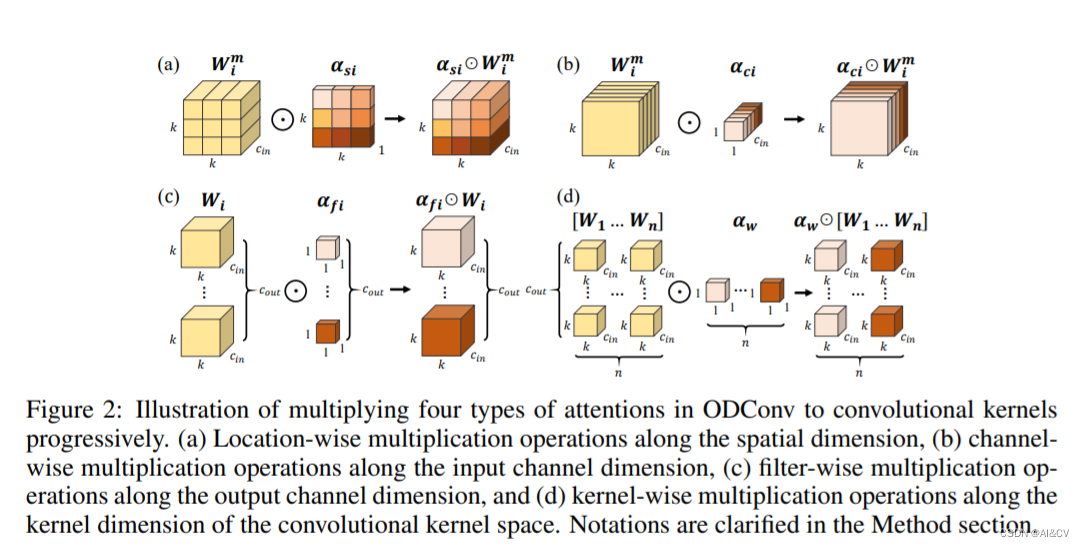
ODConv中逐步将四种类型的注意力乘以卷积核的示意图。(a) 沿空间维度的位置逐个乘法操作,(b) 沿输入通道维度的通道逐个乘法操作,(c) 沿输出通道维度的滤波器逐个乘法操作,以及 (d) 沿卷积核空间的核维度的核逐个乘法操作。
文章链接
论文地址:论文地址
代码地址:代码地址
核心代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.autograd
class Attention(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, groups=1, reduction=0.0625, kernel_num=4, min_channel=16):
super(Attention, self).__init__()
# 计算注意力通道数
attention_channel = max(int(in_planes * reduction), min_channel)
self.kernel_size = kernel_size
self.kernel_num = kernel_num
self.temperature = 1.0 # 温度参数,用于调整注意力强度
# 平均池化,用于减小空间尺寸至1x1
self.avgpool = nn.AdaptiveAvgPool2d(1)
# 全连接层,用于生成通道注意力
self.fc = nn.Conv2d(in_planes, attention_channel, 1, bias=False)
self.bn = nn.BatchNorm2d(attention_channel)
self.relu = nn.ReLU(inplace=True)
# 生成通道注意力的全连接层
self.channel_fc = nn.Conv2d(attention_channel, in_planes, 1, bias=True)
self.func_channel = self.get_channel_attention
# 如果是深度可分离卷积,使用跳过连接
if in_planes == groups and in_planes == out_planes:
self.func_filter = self.skip
else:
# 全连接层,用于生成滤波器注意力
self.filter_fc = nn.Conv2d(attention_channel, out_planes, 1, bias=True)
self.func_filter = self.get_filter_attention
# 如果是点卷积,使用跳过连接
if kernel_size == 1:
self.func_spatial = self.skip
else:
# 全连接层,用于生成空间注意力
self.spatial_fc = nn.Conv2d(attention_channel, kernel_size * kernel_size, 1, bias=True)
self.func_spatial = self.get_spatial_attention
# 如果是单核卷积,使用跳过连接
if kernel_num == 1:
self.func_kernel = self.skip
else:
# 全连接层,用于生成核注意力
self.kernel_fc = nn.Conv2d(attention_channel, kernel_num, 1, bias=True)
self.func_kernel = self.get_kernel_attention
# 初始化权重
self._initialize_weights()
def _initialize_weights(self):
# 权重初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def update_temperature(self, temperature):
self.temperature = temperature
@staticmethod
def skip(_):
return 1.0
def get_channel_attention(self, x):
# 生成通道注意力
channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)
return channel_attention
def get_filter_attention(self, x):
# 生成滤波器注意力
filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)
return filter_attention
def get_spatial_attention(self, x):
# 生成空间注意力
spatial_attention = self.spatial_fc(x).view(x.size(0), 1, 1, 1, self.kernel_size, self.kernel_size)
spatial_attention = torch.sigmoid(spatial_attention / self.temperature)
return spatial_attention
def get_kernel_attention(self, x):
# 生成核注意力
kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, 1, 1)
kernel_attention = F.softmax(kernel_attention / self.temperature, dim=1)
return kernel_attention
def forward(self, x):
# 前向传播过程
x = self.avgpool(x)
x = self.fc(x)
x = self.relu(x)
return self.func_channel(x), self.func_filter(x), self.func_spatial(x), self.func_kernel(x)
# ODConv2d类继承自nn.Module
class ODConv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1,
reduction=0.0625, kernel_num=4):
super(ODConv2d, self).__init__()
self.in_planes = in_planes # 输入通道数
self.out_planes = out_planes # 输出通道数
self.kernel_size = kernel_size # 卷积核尺寸
self.stride = stride # 步长
self.padding = padding # 填充
self.dilation = dilation # 膨胀
self.groups = groups # 分组卷积的组数
self.kernel_num = kernel_num # 核数目,用于核注意力机制
# 初始化注意力模块
self.attention = Attention(in_planes, out_planes, kernel_size, groups=groups,
reduction=reduction, kernel_num=kernel_num)
# 初始化权重参数
self.weight = nn.Parameter(torch.randn(kernel_num, out_planes, in_planes//groups, kernel_size, kernel_size),
requires_grad=True)
self._initialize_weights()
# 根据卷积核尺寸和核数目选择不同的前向传播实现
if self.kernel_size == 1 and self.kernel_num == 1:
self._forward_impl = self._forward_impl_pw1x
else:
self._forward_impl = self._forward_impl_common
def _initialize_weights(self):
# 初始化权重
for i in range(self.kernel_num):
nn.init.kaiming_normal_(self.weight[i], mode='fan_out', nonlinearity='relu')
def update_temperature(self, temperature):
# 更新注意力机制的温度参数,用于调整注意力的强度
self.attention.update_temperature(temperature)
def _forward_impl_common(self, x):
# 通用的前向传播实现,适用于多种注意力机制
channel_attention, filter_attention, spatial_attention, kernel_attention = self.attention(x)
batch_size, in_planes, height, width = x.size()
x = x * channel_attention # 应用通道注意力
x = x.reshape(1, -1, height, width)
# 合并多个注意力权重
aggregate_weight = spatial_attention * kernel_attention * self.weight.unsqueeze(dim=0)
aggregate_weight = torch.sum(aggregate_weight, dim=1).view(
[-1, self.in_planes // self.groups, self.kernel_size, self.kernel_size])
# 执行卷积操作
output = F.conv2d(x, weight=aggregate_weight, bias=None, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups * batch_size)
output = output.view(batch_size, self.out_planes, output.size(-2), output.size(-1))
output = output * filter_attention # 应用滤波器注意力
return output
def _forward_impl_pw1x(self, x):
# 点卷积1x1的特殊前向传播实现
channel_attention, filter_attention, spatial_attention, kernel_attention = self.attention(x)
x = x * channel_attention # 应用通道注意力
output = F.conv2d(x, weight=self.weight.squeeze(dim=0), bias=None, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups)
output = output * filter_attention # 应用滤波器注意力
return output
def forward(self, x):
# 根据初始化时选择的实现进行前向传播
return self._forward_impl(x)实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-ODconv.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
# optimizer='MuSGD',
optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-ODconv',
)
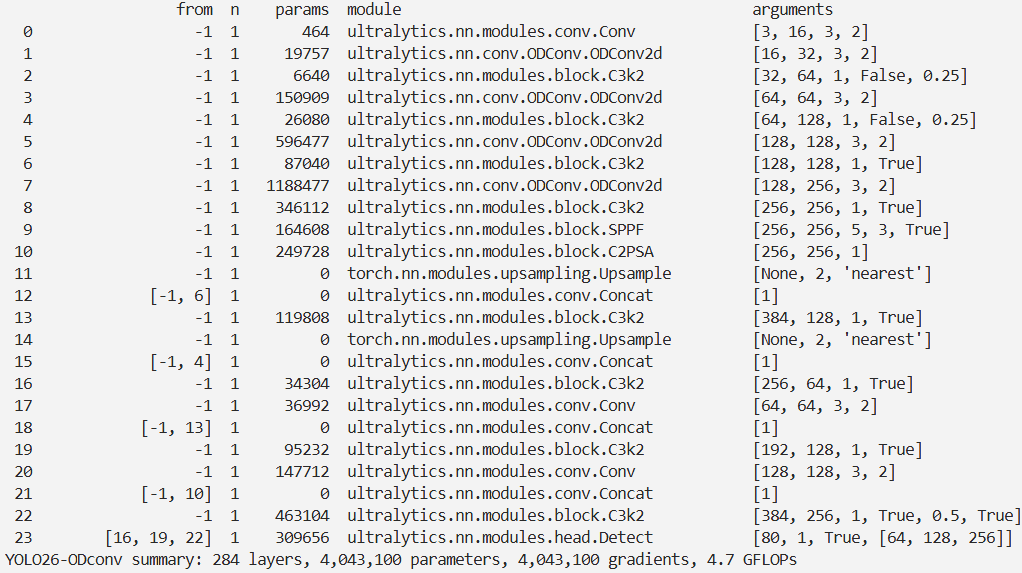
结果