YOLO26改进 – 卷积Conv DynamicConv动态卷积赋能YOLO,实现高效参数利用
前言
本文介绍了ParameterNet及其核心的动态卷积技术在YOLO26中的结合。动态卷积是一种卷积变体,通过条件生成卷积核,增强了CNN的表达和适应能力。ParameterNet方案旨在解决低FLOPs模型无法从大规模预训练受益的问题,利用动态卷积在增加参数数量的同时,将FLOPs增加最小化。复杂度分析表明,动态卷积参数量约为常规卷积的M倍,但计算量增加可忽略不计。我们将ParameterNet的动态卷积集成进YOLO26,实验显示该方案具有优越性,能提升模型性能。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
介绍

摘要
大规模视觉预训练显著提升了大型视觉模型的性能表现。然而,我们注意到,现有的低FLOPs模型却难以从中获益。为此,本文提出了一种全新的设计理念——ParameterNet,其核心在于在尽量控制FLOPs增长的前提下,有效扩展模型参数规模。我们通过引入动态卷积的方式,为网络注入额外参数,同时仅带来极小的FLOPs开销。ParameterNet的加入,使得轻量级网络亦能充分挖掘大规模视觉预训练的潜力。
不仅如此,我们还将ParameterNet的理念延伸至语言领域,实现了在维持高效推理速度的同时,进一步提升推理质量。基于大规模ImageNet-22K数据集的实验证明了ParameterNet的卓越性能。例如,ParameterNet-600M在ImageNet上的准确率达到81.6%,优于广泛采用的Swin Transformer(80.9%),且FLOPs显著更低(0.6G 对比 4.5G)。在语言任务中,集成了ParameterNet的LLaMA-1B模型比原始版本提升了2%的准确率。
相关代码将于 https://parameternet.github.io/ 发布,敬请期待。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
动态卷积
动态卷积(Dynamic Convolution)是一种卷积操作的变体,旨在增强卷积神经网络(CNN)的表达能力和适应性。与传统的静态卷积不同,动态卷积通过生成一组动态变化的卷积核来处理输入数据。这些卷积核在每次前向传播时都根据输入数据或特定的条件进行调整,从而使网络能够更好地适应不同的输入特征。
具体来说,动态卷积有以下几个特点:
-
条件生成卷积核:卷积核的权重不再是固定的,而是根据输入特征生成的。通常会使用一个辅助网络(如一个小型的MLP)来生成这些卷积核。
-
自适应性强:由于卷积核是根据每个输入数据生成的,这使得动态卷积能够更好地捕捉不同输入之间的差异,增强模型的表达能力和泛化能力。
-
计算效率:尽管动态卷积引入了额外的计算量,但通过适当的设计,这些额外的计算开销通常是可以接受的,特别是在考虑其带来的性能提升时。
-
应用场景广泛:动态卷积已经在多个任务中展示了其有效性,包括图像分类、目标检测、语义分割等。
动态卷积的一种典型实现方式如下:
- 首先,对输入特征进行处理,生成一组用于卷积的权重。
- 然后,使用这些动态生成的权重进行卷积操作,从而得到输出特征。
例如,在图像分类任务中,动态卷积可以通过根据输入图像的特征动态生成卷积核,从而使模型在处理不同类型的图像时更具适应性和鲁棒性。
ParameterNet
本文提出了一种名为ParameterNet的方案,旨在解决低FLOPs陷阱(low FLOPs pitfall)问题。其设计原则是在增加模型参数数量的同时,尽量保持低FLOPs特性。本文主要探讨了一种高效的方法,即动态卷积(Dynamic Convolution),它能够在几乎不增加额外FLOPs的情况下增加参数数量。
设输入特征为 $X \in \mathbb{R}^{C{\text{in}} \times H \times W}$,权重特征为 $W \in \mathbb{R}^{C{\text{out}} \times C_{\text{in}} \times K \times K}$,卷积操作可以表示为:
$$ Y = X * W $$
其中,$Y \in \mathbb{R}^{C_{\text{out}} \times H' \times W'}$ 是输出特征。
具有 $M$ 个动态专家的动态卷积操作可以表示为: $$ Y = X * W' $$
$$ Y = \sum_{i=1}^{M} \alpha_i (X * W_i) $$
其中,$Wi \in \mathbb{R}^{C{\text{out}} \times C_{\text{in}} \times K \times K}$ 是第 $i$ 个动态卷积核的参数,$\alpha_i$ 是对应的动态超参数,随不同的输入而动态生成。典型的生成策略如下:对于输入 $X$,应用全局平均池化将信息融合到一个向量中,然后使用具有softmax激活的两层MLP模块动态生成系数 $\alpha$。
$$ \alpha = \text{softmax}(\text{MLP}(\text{GAP}(X))) $$
其中,$\alpha \in \mathbb{R}^M$。
复杂度分析
计算动态卷积和普通卷积的参数量之比:
$$ \begin{aligned} R{param}& =\frac{C{in}^2+C{in}M+M\cdot C{out}\cdot C{in}\cdot K\cdot K}{C{out}\cdot C{in}\cdot K\cdot K} \ &=\frac{C{in}}{C{out}\cdot K\cdot K}+\frac M{C{out}\cdot K\cdot K}+M \ &\approx\frac{1}{K^{2}}+M.\quad(M<<C{out}\cdot K\cdot K, C{in}\approx C_{out}) \end{aligned} $$
计算动态卷积和普通卷积的FLOPs之比: $$ \begin{aligned} R{flops}& =\frac{C{in}^2+C{in}M+M\cdot C{out}\cdot C{in}\cdot K\cdot K+H^{\prime}\cdot W^{\prime}\cdot C{out}\cdot C{in}\cdot K\cdot K}{H^{\prime}\cdot W^{\prime}\cdot C{out}\cdot C{in}\cdot K\cdot K} \ &=\frac{C{in}}{H^{\prime}\cdot W^{\prime}\cdot C{out}\cdot K\cdot K}+\frac M{H^{\prime}\cdot W^{\prime}\cdot C{out}\cdot K\cdot K}+\frac M{H^{\prime}\cdot W^{\prime}}+1 \ &\approx1.\quad(1<M<<H'\cdot W', C{in}\approx C{out}) \end{aligned} $$
可以看到,动态卷积和普通卷积的参数量之比为 $M$,而其FLOPs基本一致。这表明,每个动态卷积的参数量大约为常规卷积的 $M$ 倍,且计算量的增加可以忽略不计。
核心代码
class DynamicConv(nn.Module):
"""动态卷积层,使用条件卷积(CondConv2d)实现。"""
def __init__(self, in_features, out_features, kernel_size=1, stride=1, padding='', dilation=1,
groups=1, bias=False, num_experts=4):
"""
初始化动态卷积层。
参数:
in_features : 输入特征通道数
out_features : 输出特征通道数
kernel_size : 卷积核大小
stride : 步长
padding : 填充
dilation : 膨胀系数
groups : 组数
bias : 是否使用偏置
num_experts : 专家数量(用于CondConv2d)
"""
super().__init__()
# 路由层,用于计算每个专家的权重
self.routing = nn.Linear(in_features, num_experts)
# 条件卷积层,实现动态卷积
self.cond_conv = CondConv2d(in_features, out_features, kernel_size, stride, padding, dilation,
groups, bias, num_experts)
def forward(self, x):
"""前向传播函数,实现动态路由和条件卷积的应用。"""
# 先对输入进行全局平均池化,并展平
pooled_inputs = F.adaptive_avg_pool2d(x, 1).flatten(1)
# 计算路由权重
routing_weights = torch.sigmoid(self.routing(pooled_inputs))
# 应用条件卷积
x = self.cond_conv(x, routing_weights)
return x实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-DynamicConv.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
# optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-DynamicConv',
)
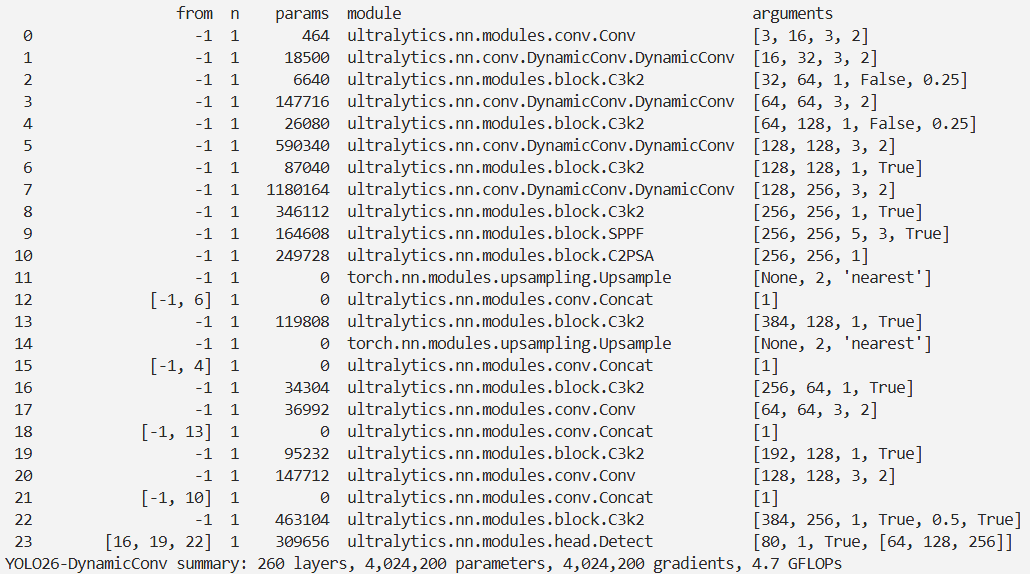
结果