YOLO26 改进 – 注意力机制 轴向注意力Axial Attention(Axial Attention)优化高分辨率特征提取
前言
本文介绍了轴向注意力(Axial Attention)机制在YOLO26中的结合应用。Axial Attention是针对高维数据张量的自注意力机制,通过对张量单个轴进行注意力计算,减少计算复杂度和内存需求,且堆叠多层可实现全局感受野。它具有计算效率高、易于实现、表达能力强等优势,适用于图像和视频处理。我们将基于Axial Attention的Axial Image Transformer集成到YOLO26的检测头中,并进行相关注册和配置。实验表明,改进后的模型在基准测试中取得了先进的结果。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
介绍

摘要
我们提出了 Axial Transformers,这是一种基于自注意力机制的自回归模型,适用于图像及其他以高维张量形式呈现的数据。现有的自回归模型在处理高维数据时,通常面临两难困境:要么需要消耗过多的计算资源,要么在降低资源需求的同时,不得不牺牲分布表达能力或实现的简便性。相比之下,我们所提出的架构不仅完整保留了对数据联合分布的表达能力,还能借助标准深度学习框架轻松实现,同时在内存和计算需求方面保持合理水平,并在标准生成建模基准测试中取得了当前最先进的成果。我们的模型以 轴向注意力(Axial Attention) 为基础,这是一种对自注意力的简单泛化设计,能自然地与张量在编码和解码过程中的多维结构相契合。值得强调的是,所提出的层结构允许在解码时以并行方式计算绝大多数上下文信息,且无需引入任何独立性假设。这种半并行结构显著提升了 Axial Transformer 在大规模模型场景下的解码适用性。我们展示了 Axial Transformer 在 ImageNet - 32 和 ImageNet - 64 图像基准以及 BAIR Robotic Pushing 视频基准上的最先进性能。此外,我们已将 Axial Transformers 的实现代码开源。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
Axial Attention是一种针对高维数据张量的自注意力机制,旨在提高计算效率和内存使用,同时保持模型的表达能力。以下是Axial Attention的详细介绍:
- 基本概念: Axial Attention的核心思想是对张量的单个轴进行注意力计算,而不是将整个张量展平。这种方法允许模型在处理高维数据时,减少计算复杂度和内存需求。例如,对于一个形状为 N=S×S 的方形图像,Axial Attention在每个轴上执行注意力计算,从而实现 O(N21) 的计算节省,相比于标准自注意力的 O(N2) 计算复杂度,显著提高了效率 。
- 实现方式: Axial Attention通过在张量的一个轴上执行注意力操作,保持其他轴的信息独立。具体实现时,可以通过转置张量的轴(除了目标轴),调用标准的注意力机制,然后再将转置恢复。这种方法简单易行,并且可以利用现有的深度学习框架中的高效矩阵乘法操作 。
- 全局感受野: 尽管单层Axial Attention只能覆盖一个轴的局部信息,但通过堆叠多个Axial Attention层,可以实现全局感受野。这意味着模型能够综合考虑整个张量的信息,从而提高生成能力和表达能力 。
- 应用场景: Axial Attention特别适用于图像和视频等高维数据的处理。通过在图像的行和列上分别应用注意力,Axial Transformer能够有效捕捉图像中的空间结构和特征,从而在多个基准测试中取得了优异的表现,如ImageNet和BAIR Robot Pushing 。
- 优势:
- 计算效率:Axial Attention在处理高维数据时,显著降低了计算和内存需求。
- 易于实现:可以利用现有的深度学习库,简化了模型的实现过程。
- 高表达能力:保持了对联合分布的完全表达能力,适用于复杂的生成任务 。
核心代码
class AxialAttention(nn.Module):
def __init__(self, dim, num_dimensions = 2, heads = 8, dim_heads = None, dim_index = -1, sum_axial_out = True):
assert (dim % heads) == 0, 'hidden dimension must be divisible by number of heads'
super().__init__()
self.dim = dim
self.total_dimensions = num_dimensions + 2
self.dim_index = dim_index if dim_index > 0 else (dim_index + self.total_dimensions)
attentions = []
for permutation in calculate_permutations(num_dimensions, dim_index):
attentions.append(PermuteToFrom(permutation, SelfAttention(dim, heads, dim_heads)))
self.axial_attentions = nn.ModuleList(attentions)
self.sum_axial_out = sum_axial_out
def forward(self, x):
assert len(x.shape) == self.total_dimensions, 'input tensor does not have the correct number of dimensions'
assert x.shape[self.dim_index] == self.dim, 'input tensor does not have the correct input dimension'
if self.sum_axial_out:
return sum(map(lambda axial_attn: axial_attn(x), self.axial_attentions))
out = x
for axial_attn in self.axial_attentions:
out = axial_attn(out)
return out
# axial image transformer
class AxialImageTransformer(nn.Module):
def __init__(self, dim, depth, heads = 8, dim_heads = None, dim_index = 1, reversible = True, axial_pos_emb_shape = None):
super().__init__()
permutations = calculate_permutations(2, dim_index)
get_ff = lambda: nn.Sequential(
ChanLayerNorm(dim),
nn.Conv2d(dim, dim * 4, 3, padding = 1),
nn.LeakyReLU(inplace=True),
nn.Conv2d(dim * 4, dim, 3, padding = 1)
)
self.pos_emb = AxialPositionalEmbedding(dim, axial_pos_emb_shape, dim_index) if exists(axial_pos_emb_shape) else nn.Identity()
layers = nn.ModuleList([])
for _ in range(depth):
attn_functions = nn.ModuleList([PermuteToFrom(permutation, PreNorm(dim, SelfAttention(dim, heads, dim_heads))) for permutation in permutations])
conv_functions = nn.ModuleList([get_ff(), get_ff()])
layers.append(attn_functions)
layers.append(conv_functions)
execute_type = ReversibleSequence if reversible else Sequential
self.layers = execute_type(layers)
def forward(self, x):
x = self.pos_emb(x)
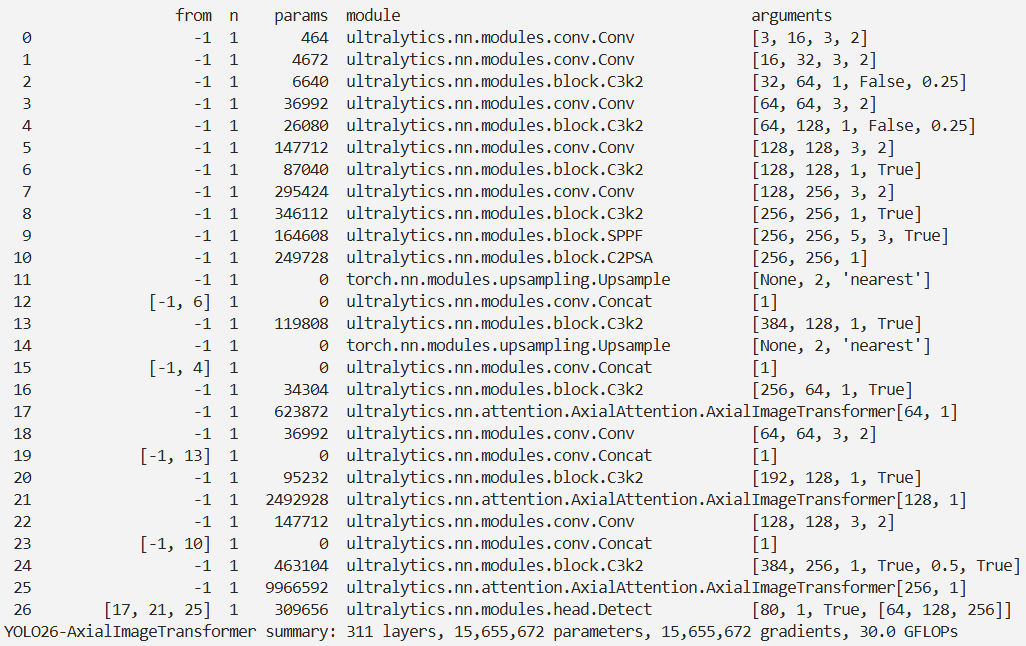
return self.layers(x)实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-AxialImageTransformer.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
amp=True,
project='runs/train',
name='yolo26-AxialImageTransformer',
)
结果