YOLO26改进 – C2PSA C2PSA融合CPIASA跨范式交互与对齐自注意力机制 交互对齐机制,提升小目标与遮挡目标判别力 ACM MM2025
前言
本文介绍了跨范式表征与对齐Transformer(CPRAformer)及其核心的跨范式交互与对齐自注意力机制(CPIA - SA),并阐述了其在YOLO26中的结合应用。传统图像去雨模型特征提取局限大,CPIA - SA通过协同“空间 - 通道”与“全局 - 局部”范式解决该问题,由SPC - SA、SPR - SA和AAFM子模块构成,经双路提取、动态过滤、空间细化、对齐融合四步工作。我们将相关代码引入指定目录,在ultralytics/nn/tasks.py中注册,配置yolo26 - C2PSA_CPIASA.yaml文件,经实验验证了该设计在检测任务中的有效性。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
介绍

摘要
基于Transformer的网络通过利用空间或通道维度的自注意力机制,在图像去雨等低层视觉任务中取得了优异性能。然而,不规则的雨纹模式和复杂的几何重叠对单一范式架构提出了挑战,亟需一种统一框架来融合互补的全局-局部与空间-通道表征。为此,我们提出了一种新颖的跨范式表征与对齐Transformer(Cross Paradigm Representation and Alignment Transformer,简称CPRAformer)。其核心思想是分层表征与对齐,充分发挥空间-通道与全局-局部两种范式的优势,以辅助图像重建。该方法弥合了范式内部及范式之间的差距,通过对齐与协调机制,实现特征的深度交互与融合。
具体而言,我们在Transformer模块中引入了两种自注意力机制:稀疏提示通道自注意力(Sparse Prompt Channel Self-Attention, SPCSA)和空间像素精炼自注意力(Spatial Pixel Refinement Self-Attention, SPR-SA)。SPCSA通过动态稀疏性增强全局通道依赖关系,而SPR-SA则聚焦于空间雨纹分布与细粒度纹理恢复。为解决两者之间存在的特征错位与知识差异问题,我们设计了自适应对齐频域模块(Adaptive Alignment Frequency Module, AAFM),以两阶段渐进方式对特征进行对齐与交互,实现自适应引导与互补,从而有效缩小范式内部及范式之间的信息鸿沟。
借助这一统一的跨范式动态交互框架,我们能够从两种范式中提取最具价值的交互融合信息。大量实验表明,我们的模型在八个基准数据集上均达到当前最先进的性能,并进一步验证了CPRAformer在其他图像复原任务及下游应用中的鲁棒性。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
CPIA-SA(跨范式交互与对齐自注意力机制)技术原理详解
CPIA-SA(Cross-Paradigm Interaction and Alignment Self-Attention)是CPRAformer模型的核心组件,其设计目标是解决传统图像去雨模型中“单一范式特征提取不全面”的痛点,通过协同“空间-通道”与“全局-局部”两种范式,实现更精准的雨痕去除与背景细节保留。以下从技术定位、核心构成、工作流程、关键创新四个维度展开详细解析:
一、技术定位:为什么需要CPIA-SA?
传统去雨模型的特征提取存在明显局限:要么仅关注全局通道信息(如识别雨痕集中的色彩通道),忽略局部像素细节;要么仅聚焦局部空间信息(如修复小区域纹理),缺乏全局雨痕分布的把控。这种“单一范式依赖”导致去雨效果顾此失彼——要么雨痕去不净,要么背景磨糊。
CPIA-SA的核心定位是“范式协同中枢”:它通过两种互补的自注意力机制分别提取“全局-通道”与“局部-空间”特征,再通过专门的对齐融合模块消除两种特征的“信息鸿沟”,让全局把控与局部修复相互配合,最终输出更全面、一致的高质量特征,为后续去雨重建提供支撑。
二、核心构成:三大子模块的分工与协作
CPIA-SA由三个功能明确且深度耦合的子模块组成,各模块既独立完成特定任务,又通过数据流形成协同闭环,具体结构如图2(文档架构图)所示:
| 子模块名称 | 核心功能 | 对应范式 | 解决的关键问题 |
|---|---|---|---|
| SPC-SA(稀疏提示通道自注意力) | 提取全局通道依赖,动态过滤无效噪声 | 全局-通道 | 传统通道注意力计算冗余、易受非雨噪声干扰 |
| SPR-SA(空间像素细化自注意力) | 建模局部空间关系,修复细粒度纹理 | 局部-空间 | 传统空间注意力计算成本高、局部细节捕捉弱 |
| AAFM(自适应对齐频率模块) | 对齐两种特征的“信息维度”,实现深度融合 | 跨范式协同 | SPC-SA与SPR-SA的特征错位、知识差异 |
三、工作流程:从特征提取到融合的四步闭环
CPIA-SA的工作流程可分为“双路提取→动态过滤→空间细化→对齐融合”四个关键步骤,全程围绕“全局不丢、局部不漏”的目标展开:
步骤1:SPC-SA——全局通道特征的“精准筛选”
SPC-SA的核心是“在通道维度上抓全局、去冗余”,通过动态稀疏机制只保留对去雨有用的通道信息,具体操作如下:
- 特征投影:将输入特征图(F \in \mathbb{R}^{H×W×C})(H=高度、W=宽度、C=通道数)通过“点卷积(PWConv)+3×3深度卷积(DWConv)”转换为查询矩阵Q、键矩阵K、值矩阵V(Transformer自注意力的标准三矩阵),其中Q/K/V均沿通道维度排列(形状为(\mathbb{R}^{C×C}))。
- 动态稀疏过滤(核心创新):
传统通道注意力会计算所有通道间的依赖关系(即稠密注意力矩阵),但很多通道间的关联与“去雨”无关(如纯色背景的通道),反而引入噪声。SPC-SA通过两个机制解决这一问题:- Top-k筛选:对注意力矩阵每行(代表一个通道的依赖关系),只保留前k%的高注意力值(即与当前通道最相关的其他通道),其余值设为0,减少冗余计算;
- EPGO(高效提示引导算子):k值并非固定(如传统方法固定k=80%),而是由输入特征动态生成——通过两层线性网络+Sigmoid激活生成“提示特征”,再结合通道数C计算出适配当前雨况的k值(如雨后天空区域k值更小,优先保留蓝色通道;雨后树叶区域k值更大,兼顾绿色与灰度通道)。
数学上,k值通过公式(算法1)计算:(Dynamic\ K = C \times p)(p为提示特征的全局平均值),确保稀疏筛选“随雨况变、按需调整”。
- 注意力计算:将筛选后的稀疏注意力矩阵与值矩阵V相乘,得到全局通道特征(F_{SPC}),该特征能清晰反映“哪些通道雨痕多、哪些通道是干净背景”。
步骤2:SPR-SA——局部空间特征的“精细修复”
SPR-SA的核心是“在空间维度上补细节、降成本”,通过CNN轻量化架构近似自注意力,高效捕捉局部像素关系:
- 局部特征压缩:对输入特征图F先通过线性层投影,再用3×3深度卷积(DWConv)捕捉局部像素关联,得到局部特征图(F_L)(形状不变,但融入周边像素信息);
- 空间权重生成:对(FL)做全局平均池化(GAP),得到每个通道的“空间重要性权重”(F{SP}),再通过点卷积(PWConv)和GELU激活函数,生成与原特征图尺寸一致的空间权重图;
- 细节增强:将空间权重图与(FL)逐元素相乘,对雨痕覆盖的局部区域(如文字边缘、树叶纹理)进行权重强化,最终输出局部空间特征(F{SPR}),该特征能精准修复被雨痕遮挡的细粒度细节。
步骤3:AAFM——两种特征的“维度对齐”
此时,(F{SPC})(全局通道)与(F{SPR})(局部空间)的“信息维度”不一致:前者关注“通道间的全局关联”,后者关注“像素间的局部关联”,直接拼接会导致信息冲突。AAFM通过两阶段策略实现对齐与融合:
- 第一阶段:特征权重对齐(空间/通道适配)
根据两种特征的属性,动态调整权重:- 对(F_{SPC})(全局通道特征),沿空间维度生成权重图(Map_C),强化雨痕集中区域的通道信息;
- 对(F_{SPR})(局部空间特征),沿通道维度生成权重图(Map_S),突出干净背景区域的空间细节;
- 通过“特征×权重图”的逐元素相乘,让两种特征在“空间-通道”维度上达成一致。
- 第二阶段:频率域融合(深层信息交互)
传统空间域融合易丢失高频细节(如边缘纹理),AAFM引入傅里叶变换(FFT) ,在频率域实现更细腻的融合:- 将对齐后的特征(\hat{F})((F_{SPC} \odot MapC + F{SPR} \odot Map_S))通过线性层投影,放大高频信号(对应雨痕边缘、背景纹理);
- 对投影后的特征做FFT,分解为实部(R)和虚部(I),捕捉全局频率分布(如大面积雨痕的低频特征、细节纹理的高频特征);
- 将R和I沿通道拼接,再通过逆FFT(IFFT)转换回空间域,得到跨范式融合特征F,该特征同时包含全局雨痕分布与局部细节信息。
步骤4:特征输出与反馈
融合后的特征F将传入CPRAformer的下一级模块(如MSGN多尺度门控网络),进一步优化多尺度雨痕处理;同时,F的部分信息会反馈给SPC-SA的EPGO,为下一轮动态k值调整提供参考,形成“自适应迭代”。
核心代码
class Attention(nn.Module):
def __init__(self, dim, num_heads, bias):
super(Attention, self).__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
self.spr_sa=spr_sa(dim//2,2)
self.linear_0 = nn.Conv2d(dim, dim , 1, 1, 0)
self.linear_2 = nn.Conv2d(dim, dim, 1, 1, 0)
self.qkv = nn.Conv2d(dim//2, dim//2 * 3, kernel_size=1, bias=bias)
self.qkv_dwconv = nn.Conv2d(dim//2 * 3, dim//2 * 3, kernel_size=3, stride=1, padding=1, groups=dim//2 * 3, bias=bias)
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
self.attn_drop = nn.Dropout(0.)
self.attn1 = torch.nn.Parameter(torch.tensor([0.2]), requires_grad=True)
self.attn2 = torch.nn.Parameter(torch.tensor([0.2]), requires_grad=True)
self.attn3 = torch.nn.Parameter(torch.tensor([0.2]), requires_grad=True)
self.attn4 = torch.nn.Parameter(torch.tensor([0.2]), requires_grad=True)
self.channel_interaction = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(dim//2, dim // 8, kernel_size=1),
nn.BatchNorm2d(dim // 8),
nn.GELU(),
nn.Conv2d(dim // 8, dim//2, kernel_size=1),
)
self.spatial_interaction = nn.Sequential(
nn.Conv2d(dim//2, dim // 16, kernel_size=1),
nn.BatchNorm2d(dim // 16),
nn.GELU(),
nn.Conv2d(dim // 16, 1, kernel_size=1)
)
self.fft=Stage2_fft(in_channels=dim)
self.gate = nn.Sequential(
nn.Conv2d(dim//2, dim // 4, kernel_size=1),
nn.ReLU(),
nn.Conv2d(dim // 4, 1, kernel_size=1), # 输出动态 K
nn.Sigmoid()
)
def forward(self, x):
b, c, h, w = x.shape
y, x = self.linear_0(x).chunk(2, dim=1)
y_d = self.spr_sa(y)
qkv = self.qkv_dwconv(self.qkv(x))
q, k, v = qkv.chunk(3, dim=1)
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
q = torch.nn.functional.normalize(q, dim=-1)
k = torch.nn.functional.normalize(k, dim=-1)
_, _, C, _ = q.shape
dynamic_k = int(C * self.gate(x).view(b, -1).mean())
attn = (q @ k.transpose(-2, -1)) * self.temperature
mask = torch.zeros(b, self.num_heads, C, C, device=x.device, requires_grad=False)
index = torch.topk(attn, k=dynamic_k, dim=-1, largest=True)[1]
mask.scatter_(-1, index, 1.)
attn = torch.where(mask > 0, attn, torch.full_like(attn, float('-inf')))
attn = attn.softmax(dim=-1)
out1 = (attn @ v)
out2 = (attn @ v)
out3 = (attn @ v)
out4 = (attn @ v)
out = out1 * self.attn1 + out2 * self.attn2 + out3 * self.attn3 + out4 * self.attn4
out_att = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)
# Frequency Adaptive Interaction Module (FAIM)
# stage1
# C-Map (before sigmoid)
channel_map = self.channel_interaction(out_att)
# S-Map (before sigmoid)
spatial_map = self.spatial_interaction(y_d)
# S-I
attened_x = out_att * torch.sigmoid(spatial_map)
# C-I
conv_x = y_d * torch.sigmoid(channel_map)
x = torch.cat([attened_x, conv_x], dim=1)
out = self.project_out(x)
# stage 2
out=self.fft(out)
return out实验
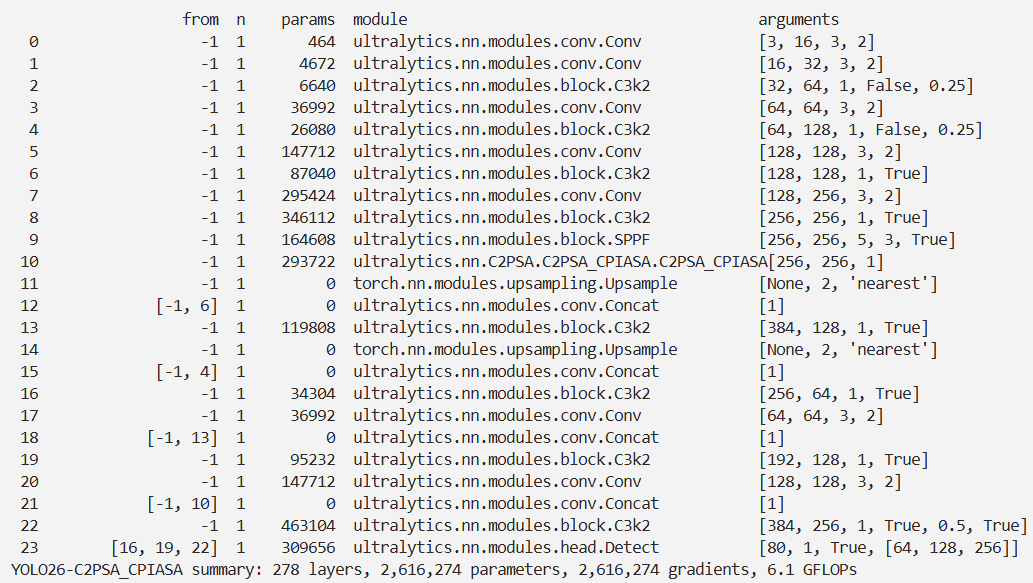
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
#
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/11/YOLO26-C2PSA_CPIASA.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='SGD',
amp=True,
project='runs/train',
name='C2PSA_CPIASA',
)
结果