YOLO26改进 – 注意力机制 STA超级令牌注意力机制:超级令牌采样实现高效全局依赖捕获,优化多尺度感知
前言
本文介绍了超级令牌注意力(STA)机制及其在YOLO26中的结合。STA机制通过引入超级令牌,将原始标记聚合成有语义意义的单元,减少自注意力计算复杂度,提高全局信息捕获效率。它包括超级令牌采样、多头自注意力和标记上采样等步骤,实现全局与局部的高效信息交互。基于此,设计了层次化的视觉Transformer结构。我们将StokenAttention集成进YOLO26的模型结构中,在骨干网络和检测头部分引入该模块。实验表明,该方法在图像分类、目标检测和语义分割等视觉任务上表现优异。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
介绍

摘要
视觉Transformer在众多视觉任务中展现出卓越的表现,然而在浅层阶段捕捉局部特征时,往往面临信息高度冗余的问题。为缓解这一问题,研究者尝试在早期阶段引入局部自注意力或卷积操作,以降低冗余程度,但这在一定程度上牺牲了对长距离依赖关系的建模能力。由此引出一个关键挑战:能否在网络初期,既高效又有效地实现全局上下文建模?
为应对此问题,我们从超像素(Superpixel)的设计理念中汲取灵感。超像素通过减少图像基元的数量,简化了后续处理流程。受此启发,我们在视觉Transformer中引入了超级令牌(Super Token),以实现对视觉内容更具语义性的划分。这一设计既有效降低了自注意力模块中的令牌数量,又保留了强大的全局建模能力。
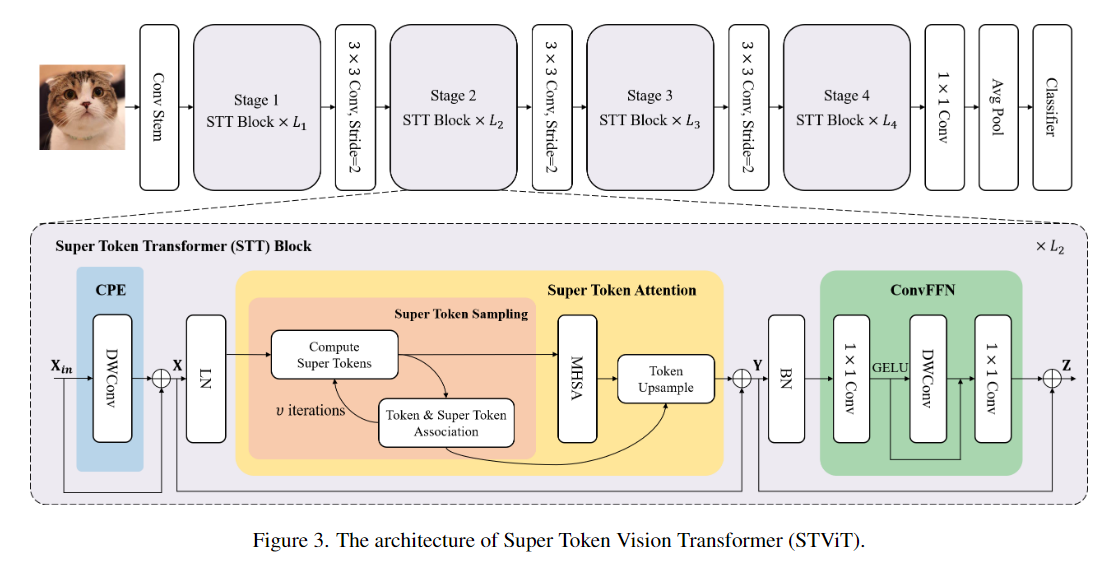
具体而言,我们提出了一种简洁而高效的超级令牌注意力机制(Super Token Attention, STA),其核心包括三个步骤:首先,通过稀疏关联学习从原始视觉令牌中抽取出代表性超级令牌;其次,对这些超级令牌施加自注意力操作,以建模全局依赖关系;最后,再将处理结果映射回原始令牌空间,实现细粒度特征的精确表达。STA巧妙地将传统全局注意力操作分解为稀疏关联图与低维度注意力的乘积,大幅提升了建模效率。
基于STA,我们进一步构建了一个层次化的视觉Transformer架构。大量实验验证了其在多个视觉任务中的卓越性能。特别是在无需额外预训练数据或辅助标签的前提下,该模型在ImageNet-1K图像分类任务中达成86.4%的Top-1准确率,在COCO目标检测任务中取得53.9的box AP与46.8的mask AP,在ADE20K语义分割任务中实现了51.9的mIoU,充分展现出其强大的泛化能力与实际应用潜力。
创新点
-
引入超级标记(super tokens):通过引入超级标记的概念,实现了在视觉Transformer中的全局上下文建模。超级标记将原始标记聚合成具有语义意义的单元,从而减少了自注意力计算的复杂度,提高了全局信息的捕获效率。
-
Super Token Attention(STA)机制:提出了一种简单而强大的超级标记注意力机制,包括超级标记采样、多头自注意力和标记上采样等步骤。STA通过稀疏映射和自注意力计算,在全局和局部之间实现了高效的信息交互,有效地学习全局表示。
-
Hierarchical Vision Transformer:设计了一种层次化的视觉Transformer结构,结合了卷积层和超级标记Transformer块,以在不同层次上实现高效和有效的表示学习。这种结构在各种视觉任务上展现了出色的性能,包括图像分类、目标检测和语义分割等。
-
性能优越性:在多个视觉任务上进行了广泛的实验验证,包括ImageNet图像分类、COCO目标检测和ADE20K语义分割等。实验结果表明,基于超级标记的视觉Transformer在各项任务上均取得了优异的性能,超越了其他Transformer模型的表现。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
Super Token Attention (STA)是文章中提出的关键算法,其核心包括三个过程:Super Token Sampling (STS)、Multi-Head Self-Attention (MHSA)和Token Upsampling (TU)。STA的创新点在于通过超级标记(super tokens)实现了稀疏映射,通过软关联在标记和超级标记之间进行自注意力计算,从而在超级标记空间中实现了自注意力机制,有效地学习全局表示。STA的基本原理包括以下几个步骤:
-
Super Token Sampling (STS):在这一步骤中,通过软关联学习将标记(tokens)聚合成超级标记(super tokens)。这个过程类似于超像素算法,将原始标记聚合成具有语义意义的超级标记,从而减少了后续自注意力计算的标记数量。
-
Multi-Head Self-Attention (MHSA):在超级标记空间中进行多头自注意力计算,以建模全局依赖关系。通过在超级标记之间进行自注意力计算,模型可以有效地捕获全局信息,从而提高对图像整体语义的理解能力。
-
Token Upsampling (TU):将经过自注意力计算得到的超级标记映射回原始标记空间,以保留全局信息并提高局部特征的表征能力。这一步骤有助于在保持全局信息的同时,维持对局部细节的敏感性。
通过这些步骤,STA利用超级标记的概念,通过稀疏映射和自注意力计算,在全局和局部之间实现了有效的信息交互,从而提高了视觉任务中的全局建模能力和特征表征效果。
核心代码
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义 Unfold 类,用于将输入张量展开
class Unfold(nn.Module):
def __init__(self, kernel_size=3):
super().__init__()
self.kernel_size = kernel_size
# 创建卷积核权重,初始化为单位矩阵,展开为所需的形状
weights = torch.eye(kernel_size ** 2)
weights = weights.reshape(kernel_size ** 2, 1, kernel_size, kernel_size)
self.weights = nn.Parameter(weights, requires_grad=False)
def forward(self, x):
# 获取输入张量的形状
b, c, h, w = x.shape
# 使用2D卷积展开输入张量
x = F.conv2d(x.reshape(b * c, 1, h, w), self.weights, stride=1, padding=self.kernel_size // 2)
return x.reshape(b, c * 9, h * w) # 将输出张量重新形状化并返回
# 定义 Fold 类,用于将展开后的张量折叠回去
class Fold(nn.Module):
def __init__(self, kernel_size=3):
super().__init__()
self.kernel_size = kernel_size
# 创建卷积核权重,初始化为单位矩阵,展开为所需的形状
weights = torch.eye(kernel_size ** 2)
weights = weights.reshape(kernel_size ** 2, 1, kernel_size, kernel_size)
self.weights = nn.Parameter(weights, requires_grad=False)
def forward(self, x):
# 获取输入张量的形状
b, _, h, w = x.shape
# 使用2D反卷积将张量折叠回去
x = F.conv_transpose2d(x, self.weights, stride=1, padding=self.kernel_size // 2)
return x # 返回折叠后的张量
# 定义 StAttention 类,用于计算空间注意力机制
class StAttention(nn.Module):
def __init__(self, dim, window_size=None, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim # 输入通道数
self.num_heads = num_heads # 注意力头数
head_dim = dim // num_heads
self.window_size = window_size
self.scale = qk_scale or head_dim ** -0.5 # 缩放因子
# 定义卷积层,用于生成查询、键和值
self.qkv = nn.Conv2d(dim, dim * 3, 1, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Conv2d(dim, dim, 1)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, C, H, W = x.shape
N = H * W
# 计算查询、键和值,并分割成三部分
q, k, v = self.qkv(x).reshape(B, self.num_heads, C // self.num_heads * 3, N).chunk(3, dim=2)
# 计算注意力权重
attn = (k.transpose(-1, -2) @ q) * self.scale
attn = attn.softmax(dim=-2) # 对注意力权重进行softmax操作
attn = self.attn_drop(attn)
# 计算输出
x = (v @ attn).reshape(B, C, H, W)
x = self.proj(x)
x = self.proj_drop(x)
return x # 返回注意力机制处理后的张量
# 定义 StokenAttention 类,用于基于空间令牌的注意力机制
class StokenAttention(nn.Module):
def __init__(self, dim, stoken_size=[8,8], n_iter=1, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.n_iter = n_iter # 迭代次数
self.stoken_size = stoken_size # 空间令牌的大小
self.scale = dim ** - 0.5 # 缩放因子
self.unfold = Unfold(3) # 定义Unfold实例
self.fold = Fold(3) # 定义Fold实例
# 定义空间注意力机制
self.stoken_refine = StAttention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=proj_drop)
def stoken_forward(self, x):
'''
x: (B, C, H, W)
'''
B, C, H0, W0 = x.shape
h, w = self.stoken_size
pad_l = pad_t = 0
pad_r = (w - W0 % w) % w
pad_b = (h - H0 % h) % h
if pad_r > 0 or pad_b > 0:
x = F.pad(x, (pad_l, pad_r, pad_t, pad_b)) # 对输入张量进行填充
_, _, H, W = x.shape
hh, ww = H // h, W // w
stoken_features = F.adaptive_avg_pool2d(x, (hh, ww)) # 自适应平均池化
pixel_features = x.reshape(B, C, hh, h, ww, w).permute(0, 2, 4, 3, 5, 1).reshape(B, hh * ww, h * w, C)
with torch.no_grad():
for idx in range(self.n_iter):
stoken_features = self.unfold(stoken_features) # 展开空间令牌特征
stoken_features = stoken_features.transpose(1, 2).reshape(B, hh * ww, C, 9)
affinity_matrix = pixel_features @ stoken_features * self.scale # 计算亲和矩阵
affinity_matrix = affinity_matrix.softmax(-1) # 对亲和矩阵进行softmax
affinity_matrix_sum = affinity_matrix.sum(2).transpose(1, 2).reshape(B, 9, hh, ww)
affinity_matrix_sum = self.fold(affinity_matrix_sum)
if idx < self.n_iter - 1:
stoken_features = pixel_features.transpose(-1, -2) @ affinity_matrix
stoken_features = self.fold(stoken_features.permute(0, 2, 3, 1).reshape(B * C, 9, hh, ww)).reshape(B, C, hh, ww)
stoken_features = stoken_features / (affinity_matrix_sum + 1e-12) # 归一化
stoken_features = pixel_features.transpose(-1, -2) @ affinity_matrix
stoken_features = self.fold(stoken_features.permute(0, 2, 3, 1).reshape(B * C, 9, hh, ww)).reshape(B, C, hh, ww)
stoken_features = stoken_features / (affinity_matrix_sum.detach() + 1e-12) # 归一化
stoken_features = self.stoken_refine(stoken_features) # 细化空间令牌特征
stoken_features = self.unfold(stoken_features) # 展开细化后的特征
stoken_features = stoken_features.transpose(1, 2).reshape(B, hh * ww, C, 9)
pixel_features = stoken_features @ affinity_matrix.transpose(-1, -2) # 计算最终的像素特征
pixel_features = pixel_features.reshape(B, hh, ww, C, h, w).permute(0, 3, 1, 4, 2, 5).reshape(B, C, H, W)
if pad_r > 0 or pad_b > 0:
pixel_features = pixel_features[:, :, :H0, :W0] # 去除填充部分
return pixel_features # 返回最终的像素特征
def direct_forward(self, x):
B, C, H, W = x.shape
stoken_features = x
stoken_features = self.stoken_refine(stoken_features)
return stoken_features # 返回直接计算的空间令牌特征
def forward(self, x):
if self.stoken_size[0] > 1 or self.stoken_size[1] > 1:
return self.stoken_forward(x) # 使用空间令牌前向计算
else:
return self.direct_forward(x) # 直接前向计算实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-StokenAttention.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
# optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-StokenAttention',
)