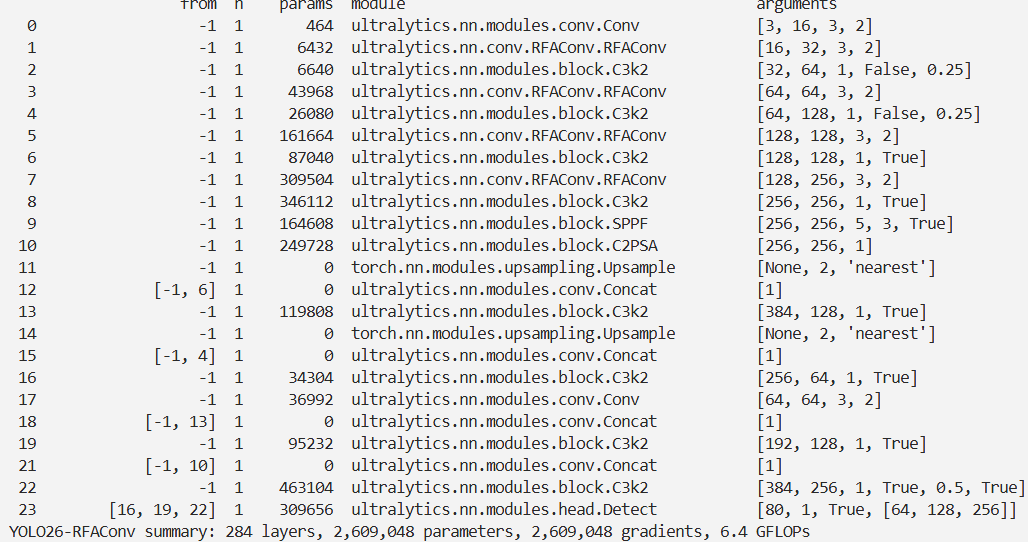
YOLO26改进 – 卷积Conv RFAConv:感受野注意力卷积动态调整感受野,提升小目标检出精度
前言
本文介绍了感受野注意力卷积(RFAConv)及其在 YOLO26中的结合。空间注意力虽广泛应用但有局限,RFAConv 是将空间注意力与卷积操作融合的新型注意力机制,通过强化感受野空间特征关注、解决卷积核参数共享挑战、增强大尺寸卷积核处理能力等策略优化卷积核功能。它有基于 Group Conv 和 Unfold 两种实现方式,实验表明前者性能更好。我们将 RFAConv 集成进 YOLO26,在数据集实验证明了方法优越性 。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
介绍

摘要
空间注意力机制已在提升卷积神经网络性能方面得到广泛应用,但其存在一定局限。本文提出了关于空间注意力有效性的全新视角,即空间注意力机制本质上旨在解决卷积核参数共享问题。然而,空间注意力所生成的注意力图中包含的信息,对于大尺寸卷积核而言并不充分。基于此,我们提出了一种名为感受野注意力(Receptive - Field Attention,简称RFA)的新型注意力机制。现有的空间注意力方法,如卷积块注意力模块(Convolutional Block Attention Module,简称CBAM)和协调注意力(Coordinated Attention,简称CA)仅关注空间特征,未能完全解决卷积核参数共享问题。与之不同的是,RFA不仅关注感受野空间特征,还能为大尺寸卷积核提供有效的注意力权重。RFA所开发的感受野注意力卷积操作(Receptive - Field Attention convolutional operation,简称RFAConv)代表了一种可替代标准卷积操作的新途径,其在几乎不增加计算成本和参数的情况下,能够显著提升网络性能。我们在ImageNet - 1k、COCO和VOC数据集上开展了一系列实验,以证实所提方法的优越性。尤为重要的是,我们认为当下应从关注空间特征转向关注感受野空间特征,以此改进现有的空间注意力机制,进而进一步提高网络性能并获取更优结果。
创新点
感受野注意力卷积(Receptive-Field Attention Convolution,简称RFAConv)的主要创新在于将空间注意力机制与卷积操作相融合,旨在提升卷积神经网络(CNN)的性能。该方法通过以下关键策略,对卷积核的功能进行优化,特别强调处理感受野内部的空间特征:
-
对感受野空间特征的强化关注: RFAConv着重于感受野内的空间特征,超越了传统空间维度的限制。此方法使得网络能够更高效地识别和处理图像中的局部区域,进而提升特征提取的准确性。
-
解决卷积核参数共享的挑战: 在传统CNN结构中,卷积核在处理图像的不同区域时采用相同的参数,这可能会限制模型对复杂模式的识别能力。RFAConv通过整合注意力机制,实现了卷积核参数的灵活调整,为不同的图像区域提供了定制化的处理方案。
-
增强大尺寸卷积核的处理能力: 对于大尺寸的卷积核,单纯依赖传统空间注意力机制可能无法充分捕捉所有关键信息。RFAConv通过赋予有效的注意力权重,确保大尺寸卷积核能够更加精确地处理图像信息。
综上所述,感受野注意力卷积代表了对传统卷积操作的革新性改进,它不仅提升了网络对图像细节的处理能力,还为处理更复杂的视觉任务提供了强有力的支持。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
-
标准卷积运算的分析:在传统方法中,每个感受野特征共享卷积核,这导致对位置信息的不敏感性。由于图像信息在不同位置存在差异,共享参数的卷积无法充分识别这些差异。相关的图表展示了卷积核在不同感受野中的共享情况。
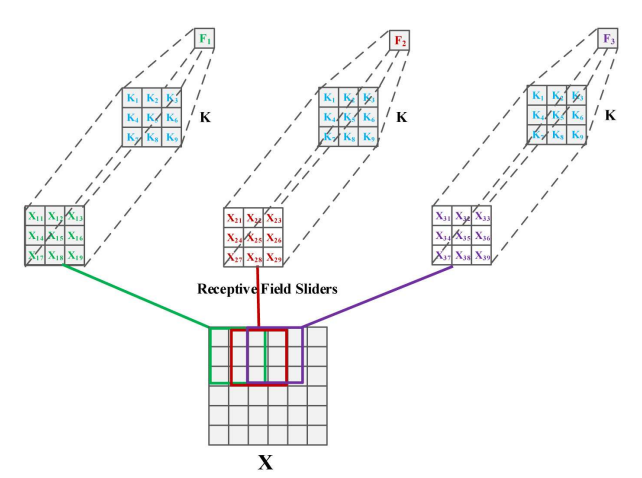
-
空间注意力的回顾: 文章分析了空间注意力机制,举例说明了具有单一通道数的特征图通过与注意力图加权的过程。空间注意力的注意力图与特征图形状相同,意味着每个特征图上的像素点会乘以相应的注意力权重。
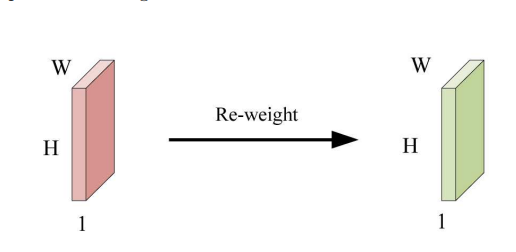
-
结合空间注意力与卷积运算的分析: 作者探讨了在卷积网络中加入空间注意力的常见做法,通常是接一个1x1或3x3的卷积运算。作者通过详细分析这两种情况,提出将注意力权重和卷积核参数的乘积视为新的卷积参数,从而解决了卷积核参数共享的问题。
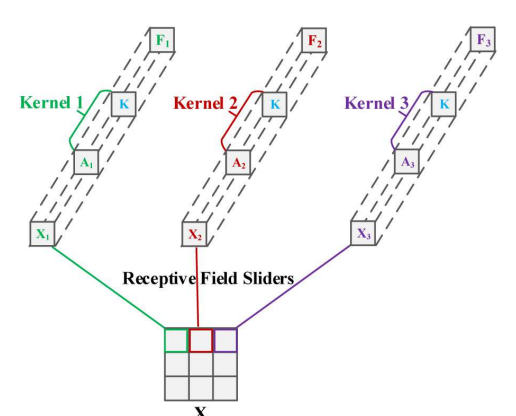
-
空间注意力机制的局限性与解决方案: 尽管空间注意力机制解决了一些问题,但作者指出其局限性在于感受野特征的重叠导致注意力权重在不同感受野中共享。为解决此问题,作者提出关注感受野空间特征,并通过Unfold方法提取这些特征。在VisDrone数据集上的实验验证了这种方法的有效性。由于Unfold方法较慢,作者采用分组卷积提取感受野空间特征,并设计了RFA和RFAConv。
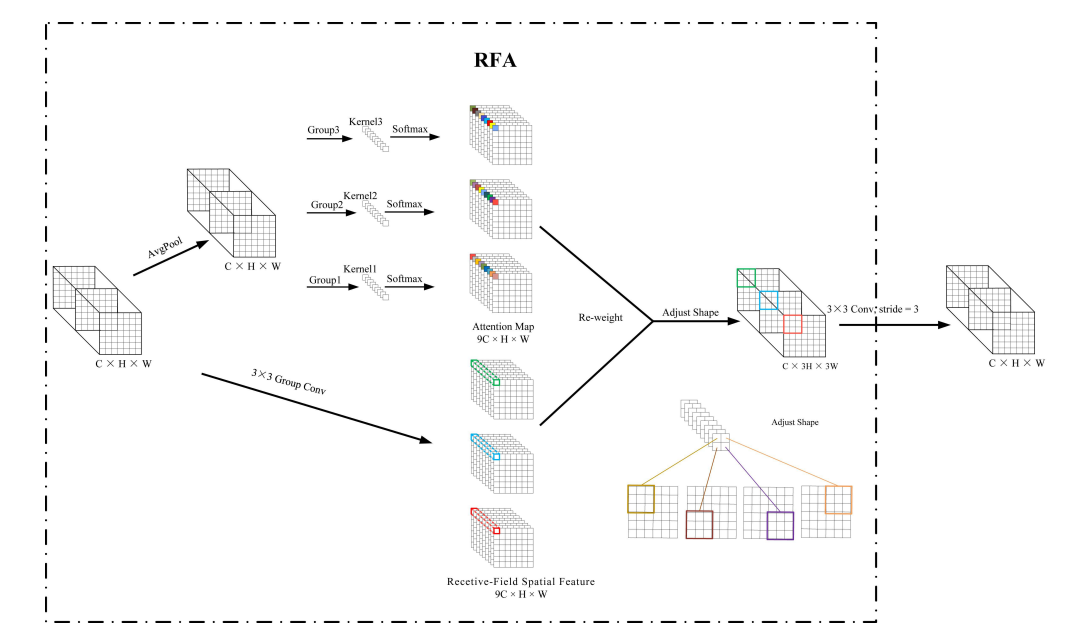
-
对CBAM和CA的改进: 作者考虑将空间注意力机制的特性应用于如CBAM和CA等模块,并关注感受野空间特征以提高性能。因此,他们设计了RFCBAM和RFCA,并进一步结合卷积操作设计了RFCBAMConv和RFCAConv。在设计RFCBAM时,作者考虑同时加权通道和空间注意力,以确保每个通道在空间上的注意力权重不同。CBAM在加权通道注意力时,每个通道的空间注意力权重是相同的,这一点在空间注意力加权时也适用。
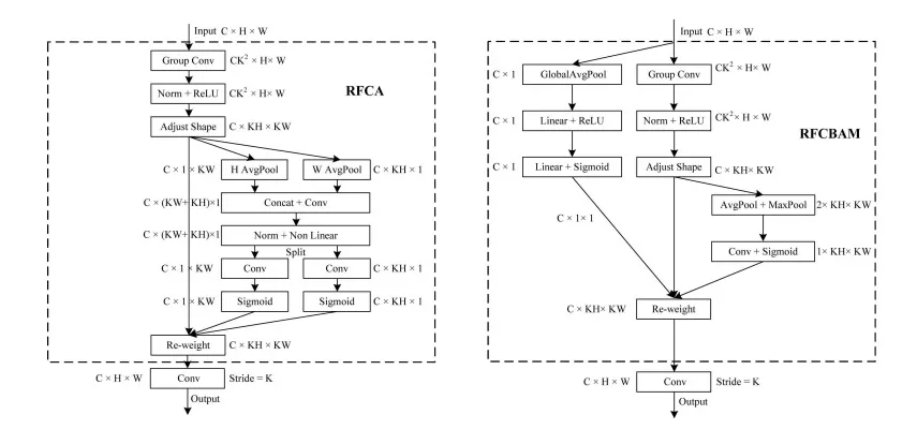
核心代码
基于Group Conv实现的RFAConv
import torch
from torch import nn
from einops import rearrange
class RFAConv(nn.Module): # 定义RFAConv类,继承自nn.Module,基于分组卷积(Group Convolution)实现
def __init__(self, in_channel, out_channel, kernel_size, stride=1):
super().__init__()
self.kernel_size = kernel_size # 卷积核的大小
# 权重生成模块,使用平均池化和分组卷积来计算权重
self.get_weight = nn.Sequential(
# 首先使用平均池化减少特征图尺寸
nn.AvgPool2d(kernel_size=kernel_size, padding=kernel_size // 2, stride=stride),
# 然后通过分组卷积生成权重,卷积核大小为1,无偏置项
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=1, groups=in_channel, bias=False)
)
# 特征生成模块,使用分组卷积生成特征
self.generate_feature = nn.Sequential(
# 分组卷积,用于提取每个分组的感受野特征
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=kernel_size, padding=kernel_size//2, stride=stride, groups=in_channel, bias=False),
# 批量归一化层
nn.BatchNorm2d(in_channel * (kernel_size ** 2)),
# ReLU激活函数
nn.ReLU()
)
# 最终卷积层,将加权特征图转换为输出特征图
self.conv = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size),
nn.BatchNorm2d(out_channel),
nn.ReLU()
)
def forward(self, x):
b, c = x.shape[0:2] # 获取输入特征图的批次大小和通道数
weight = self.get_weight(x) # 计算每个位置的权重
h, w = weight.shape[2:] # 获取权重特征图的高和宽
# 重塑权重特征图,并应用Softmax函数进行归一化
weighted = weight.view(b, c, self.kernel_size ** 2, h, w).softmax(2) # b c*kernel**2,h,w -> b c k**2 h w
# 通过特征生成模块获得感受野空间特征
feature = self.generate_feature(x).view(b, c, self.kernel_size ** 2, h, w) #b c*kernel**2,h,w -> b c k**2 h w
# 将权重应用到特征上,进行加权
weighted_data = feature * weighted
# 重排加权后的特征图,以适应最终的卷积操作
conv_data = rearrange(weighted_data, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size, # b c k**2 h w -> b c h*k w*k
n2=self.kernel_size)
# 通过卷积层生成最终的输出特征图
return self.conv(conv_data)基于Unfold实现的RFAConv
from torch import nn
from einops import rearrange
class RFAConv(nn.Module): # 基于Unfold实现的RFAConv类
def __init__(self, in_channel, out_channel, kernel_size=3):
super().__init__()
self.kernel_size = kernel_size # 卷积核大小
# 使用Unfold操作提取感受野特征,padding为kernel_size的一半以保持特征尺寸
self.unfold = nn.Unfold(kernel_size=(kernel_size, kernel_size), padding=kernel_size // 2)
# 生成权重的卷积层,用于计算每个位置的权重
self.get_weights = nn.Sequential(
nn.Conv2d(in_channel * (kernel_size ** 2), in_channel * (kernel_size ** 2), kernel_size=1,
groups=in_channel),
nn.BatchNorm2d(in_channel * (kernel_size ** 2))
)
# 标准卷积层,用于融合加权后的特征
self.conv = nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, padding=0, stride=kernel_size)
self.bn = nn.BatchNorm2d(out_channel) # 批量归一化层
self.act = nn.ReLU() # 激活函数
def forward(self, x):
b, c, h, w = x.shape # 输入特征的维度
unfold_feature = self.unfold(x) # 获得感受野空间特征,维度为b * c * kernel_size^2 * h * w
x = unfold_feature
data = unfold_feature.unsqueeze(-1) # 为权重添加一个维度
# 计算每个位置的注意力权重
weight = self.get_weights(data).view(b, c, self.kernel_size ** 2, h, w).permute(0, 1, 3, 4, 2).softmax(-1)
# 重排权重的维度,使其与输入特征对应
weight_out = rearrange(weight, 'b c h w (n1 n2) -> b c (h n1) (w n2)', n1=self.kernel_size,
n2=self.kernel_size)
# 重排感受野特征的维度,使其与权重对应
receptive_field_data = rearrange(x, 'b (c n1) l -> b c n1 l', n1=self.kernel_size ** 2).permute(0, 1, 3,
2).reshape(b, c,
h, w,
self.kernel_size ** 2)
# 重排感受野特征的维度,使其与权重对应
data_out = rearrange(receptive_field_data, 'b c h w (n1 n2) -> b c (h n1) (w n2)', n1=self.kernel_size,
n2=self.kernel_size)
# 将权重应用于感受野特征
conv_data = data_out * weight_out
# 通过卷积层融合特征
conv_out = self.conv(conv_data)
# 应用批量归一化和激活函数
return self.act(self.bn(conv_out))完整代码
#-------------------------------------------------------------------#
# Author : 章鑫
# Date : 2023-10-11 20:22:56
# LastEditTime : 2023-10-12 17:02:50
# Description : RFAConv系列
#-------------------------------------------------------------------#
import torch
from torch import nn
from einops import rearrange
class RFAConv(nn.Module): # 基于Group Conv实现的RFAConv
def __init__(self,in_channel,out_channel,kernel_size,stride=1):
super().__init__()
self.kernel_size = kernel_size
self.get_weight = nn.Sequential(nn.AvgPool2d(kernel_size=kernel_size, padding=kernel_size // 2, stride=stride),
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=1, groups=in_channel,bias=False))
self.generate_feature = nn.Sequential(
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=kernel_size,padding=kernel_size//2,stride=stride, groups=in_channel, bias=False),
nn.BatchNorm2d(in_channel * (kernel_size ** 2)),
nn.ReLU())
self.conv = nn.Sequential(nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size),
nn.BatchNorm2d(out_channel),
nn.ReLU())
def forward(self,x):
b,c = x.shape[0:2]
weight = self.get_weight(x)
h,w = weight.shape[2:]
weighted = weight.view(b, c, self.kernel_size ** 2, h, w).softmax(2) # b c*kernel**2,h,w -> b c k**2 h w
feature = self.generate_feature(x).view(b, c, self.kernel_size ** 2, h, w) #b c*kernel**2,h,w -> b c k**2 h w 获得感受野空间特征
weighted_data = feature * weighted
conv_data = rearrange(weighted_data, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size, # b c k**2 h w -> b c h*k w*k
n2=self.kernel_size)
return self.conv(conv_data)
class RFAConv(nn.Module): # 基于Unfold实现的RFAConv
def __init__(self, in_channel, out_channel, kernel_size=3):
super().__init__()
self.kernel_size = kernel_size
self.unfold = nn.Unfold(kernel_size=(kernel_size, kernel_size), padding=kernel_size // 2)
self.get_weights = nn.Sequential(
nn.Conv2d(in_channel * (kernel_size ** 2), in_channel * (kernel_size ** 2), kernel_size=1,
groups=in_channel),
nn.BatchNorm2d(in_channel * (kernel_size ** 2)))
self.conv = nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, padding=0, stride=kernel_size)
self.bn = nn.BatchNorm2d(out_channel)
self.act = nn.ReLU()
def forward(self, x):
b, c, h, w = x.shape
unfold_feature = self.unfold(x) # 获得感受野空间特征 b c*kernel**2,h*w
x = unfold_feature
data = unfold_feature.unsqueeze(-1)
weight = self.get_weights(data).view(b, c, self.kernel_size ** 2, h, w).permute(0, 1, 3, 4, 2).softmax(-1)
weight_out = rearrange(weight, 'b c h w (n1 n2) -> b c (h n1) (w n2)', n1=self.kernel_size, n2=self.kernel_size) # b c h w k**2 -> b c h*k w*k
receptive_field_data = rearrange(x, 'b (c n1) l -> b c n1 l', n1=self.kernel_size ** 2).permute(0, 1, 3, 2).reshape(b, c, h, w, self.kernel_size ** 2) # b c*kernel**2,h*w -> b c h w k**2
data_out = rearrange(receptive_field_data, 'b c h w (n1 n2) -> b c (h n1) (w n2)', n1=self.kernel_size,n2=self.kernel_size) # b c h w k**2 -> b c h*k w*k
conv_data = data_out * weight_out
conv_out = self.conv(conv_data)
return self.act(self.bn(conv_out))
# 在Visdrone数据集中,基于Unfold和Group Conv的RFAConv进行了对比实验,检测模型为YOLOv5n,学习率为0.1,batch-size为8,epoch为300,其他超参数为默认参数。 其中RFAConv替换了C3瓶颈中的3*3卷积运算。
# 实验表明,基于Group Conv的RFAConv性能更好,因为Unfold提取感受野空间特征时,一定程度上消耗时间比较严重。因此全文选择了Group Conv的方法进行实验,并通过这种方式对CBAM和CA进行改进。
""" 一个小白写给读者的一些启发:
(1)基于局部窗口的自注意力,最后通过softmax进行加权,然后进行sum融合特征。以这种角度理解RFAConv,同样通过Softmax进行加权,然后通过卷积核参数进行sum融合局部窗口的信息。
那么是否可以将局部窗口的自注意力最后的sum也通过高效的卷积参数或者全连接参数进行融合。
(2)除去论文外的其他的空间注意力是否可以把关注度放到感受野空间特征中呢,我觉得这是可行的。
"""
class SE(nn.Module):
def __init__(self, in_channel, ratio=16):
super(SE, self).__init__()
self.gap = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Sequential(
nn.Linear(in_channel, ratio, bias=False), # 从 c -> c/r
nn.ReLU(),
nn.Linear(ratio, in_channel, bias=False), # 从 c/r -> c
nn.Sigmoid()
)
def forward(self, x):
b, c= x.shape[0:2]
y = self.gap(x).view(b, c)
y = self.fc(y).view(b, c,1, 1)
return y
class RFCBAMConv(nn.Module):
def __init__(self,in_channel,out_channel,kernel_size=3,stride=1,dilation=1):
super().__init__()
if kernel_size % 2 == 0:
assert("the kernel_size must be odd.")
self.kernel_size = kernel_size
self.generate = nn.Sequential(nn.Conv2d(in_channel,in_channel * (kernel_size**2),kernel_size,padding=kernel_size//2,
stride=stride,groups=in_channel,bias =False),
nn.BatchNorm2d(in_channel * (kernel_size**2)),
nn.ReLU()
)
self. get_weight = nn.Sequential(nn.Conv2d(2,1,kernel_size=3,padding=1,bias=False),nn.Sigmoid())
self.se = SE(in_channel)
self.conv = nn.Sequential(nn.Conv2d(in_channel,out_channel,kernel_size,stride=kernel_size),nn.BatchNorm2d(out_channel),nn.ReLu())
def forward(self,x):
b,c = x.shape[0:2]
channel_attention = self.se(x)
generate_feature = self.generate(x)
h,w = generate_feature.shape[2:]
generate_feature = generate_feature.view(b,c,self.kernel_size**2,h,w)
generate_feature = rearrange(generate_feature, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size,
n2=self.kernel_size)
unfold_feature = generate_feature * channel_attention
max_feature,_ = torch.max(generate_feature,dim=1,keepdim=True)
mean_feature = torch.mean(generate_feature,dim=1,keepdim=True)
receptive_field_attention = self.get_weight(torch.cat((max_feature,mean_feature),dim=1))
conv_data = unfold_feature * receptive_field_attention
return self.conv(conv_data)
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class RFCAConv(nn.Module):
def __init__(self, inp, oup,kernel_size,stride, reduction=32):
super(RFCAConv, self).__init__()
self.kernel_size = kernel_size
self.generate = nn.Sequential(nn.Conv2d(inp,inp * (kernel_size**2),kernel_size,padding=kernel_size//2,
stride=stride,groups=inp,
bias =False),
nn.BatchNorm2d(inp * (kernel_size**2)),
nn.ReLU()
)
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
self.conv = nn.Sequential(nn.Conv2d(inp,oup,kernel_size,stride=kernel_size))
def forward(self, x):
b,c = x.shape[0:2]
generate_feature = self.generate(x)
h,w = generate_feature.shape[2:]
generate_feature = generate_feature.view(b,c,self.kernel_size**2,h,w)
generate_feature = rearrange(generate_feature, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size,
n2=self.kernel_size)
x_h = self.pool_h(generate_feature)
x_w = self.pool_w(generate_feature).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
h,w = generate_feature.shape[2:]
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
return self.conv(generate_feature * a_w * a_h)
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-RFAConv.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
# optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-RFAConv',
)
结果