YOLOv11 改进 – 基础知识 为什么SPPF比SPP更快?深入解析YOLO中多尺度特征提取的效率优化与代码实现
# 前言
本文为深度学习和目标检测实践者提供了一份关于SPP(空间金字塔池化) 及其高效版本SPPF模块的详细解析。内容从模块的设计动机出发,深入剖析了二者在多尺度特征提取方式上的根本区别:SPP采用并行多核池化,而SPPF通过串联小核池化实现近似的感受野,从而显著提升计算效率。文章通过清晰的结构图解、感受野计算演示和完整的代码分析,直观展示了SPPF为何能在YOLO等模型中实现速度的倍增。同时,文中包含详细的对比表格和常见问题解答,旨在帮助读者全面理解其原理,并能在自定义模型中进行有效的应用与选择。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
说明
本文基于版本:tag = 8.3.0,最早版本的YOLOv11代码,可能新版本有区别。但基本没啥影响。
🚀 快速理解:SPP和SPPF是什么?
用一句话概括
SPPF(快速空间金字塔池化层,Spatial Pyramid Pooling Fast)模块是SPP(传统空间金字塔池化,Spatial Pyramid Pooling)模块的优化版本,旨在保留多尺度特征提取能力的同时,显著提升计算效率。
形象比喻
想象你在观察一幅画:
- SPP:同时用3个不同大小的放大镜(5×5、9×9、13×13)观察,每个放大镜独立工作
- SPPF:用一个5×5的放大镜连续观察3次,每次观察的结果都保存下来,最终得到类似的效果,但速度更快
为什么需要SPPF?
SPP模块通过并行多个不同尺度的池化操作来融合多尺度特征,但多个大尺寸池化核的计算开销较高。因此促成了SPPF模块的诞生,它通过串联小池化核(如5×5)实现等效的大感受野,减少计算量并加速推理。
📐 SPP模块详解
2.1 SPP模块定义
SPP模块是一种用于增强多尺度特征提取能力的关键组件,尤其在YOLOv4、YOLOv5等后续版本中被广泛采用。
代码实现
class SPP(nn.Module):
"""Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729."""
def __init__(self, c1, c2, k=(5, 9, 13)):
"""Initialize the SPP layer with input/output channels and pooling kernel sizes."""
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
"""Forward pass of the SPP layer, performing spatial pyramid pooling."""
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))代码位置:ultralytics/nn/modules/block.py:152-166
结构图解
输入特征图 (c1通道)
↓
[cv1: 1×1卷积] → 压缩到c_通道
↓
├─→ 原始特征图 (c_通道)
├─→ MaxPool(5×5) → 池化特征1 (c_通道)
├─→ MaxPool(9×9) → 池化特征2 (c_通道)
└─→ MaxPool(13×13) → 池化特征3 (c_通道)
↓
[拼接] → 4×c_通道
↓
[cv2: 1×1卷积] → 输出 (c2通道)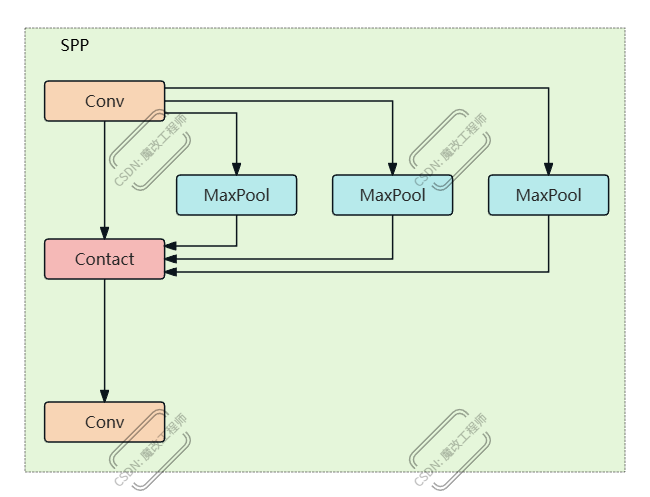
2.2 SPP模块工作原理
并行多尺度池化
SPP模块使用了多个不同尺寸的最大池化层(MaxPool),其池化核(k)的大小分别为$5\times 5$、$9\times 9$和$13\times 13$。每个池化层的参数设置:
- 步长(s):1
- 填充(p):池化核大小的一半(
padding=x // 2) - 作用:保证输入输出特征图的尺寸一致
多尺度特征融合
池化完成后,将池化特征图和池化前的特征图按通道拼接,形成了更丰富的多尺度特征。最后用一个卷积模块,实现了多尺度特征的融合,以及通道数量的变换。
2.3 SPP模块的作用
-
多尺度特征融合:通过不同大小的池化核,捕捉从细粒度到粗粒度的上下文信息,增强模型对不同尺寸目标的敏感度。
-
提升感受野:大尺寸池化核(如 $13 \times 13$)扩大了特征图的感受野,有助于检测大物体。
-
保持空间信息:与原始SPPNet不同,YOLO中的SPP模块不改变特征图尺寸,保留空间信息以支持像素级检测任务。
⚡ SPPF模块详解
3.1 SPPF模块定义
SPPF模块通过串联小池化核(如5×5)实现等效的大感受野,减少计算量并加速推理。
代码实现
class SPPF(nn.Module):
"""Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher."""
def __init__(self, c1, c2, k=5):
"""
Initializes the SPPF layer with given input/output channels and kernel size.
This module is equivalent to SPP(k=(5, 9, 13)).
"""
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
"""Forward pass through Ghost Convolution block."""
y = [self.cv1(x)]
y.extend(self.m(y[-1]) for _ in range(3))
return self.cv2(torch.cat(y, 1))代码位置:ultralytics/nn/modules/block.py:169-188
结构图解
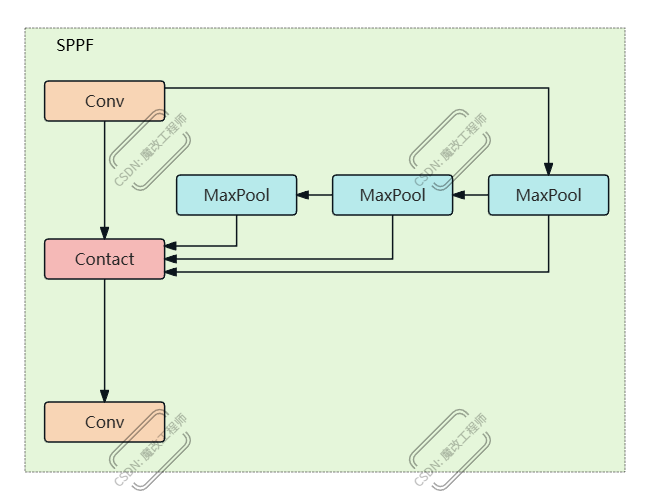
输入特征图 (c1通道)
↓
[cv1: 1×1卷积] → 压缩到c_通道
↓
├─→ 原始特征图 (c_通道) → y[0]
├─→ MaxPool(5×5) → 池化特征1 (c_通道) → y[1]
│ ↓
├─→ MaxPool(5×5) → 池化特征2 (c_通道) → y[2]
│ ↓
└─→ MaxPool(5×5) → 池化特征3 (c_通道) → y[3]
↓
[拼接] → 4×c_通道
↓
[cv2: 1×1卷积] → 输出 (c2通道)3.2 SPPF模块工作原理
串联小池化核
相较于SPP,SPPF的核心思想是用串联的小池化核替代并行的大池化核。3次连续的$5\times 5$池化操作(每次步长=1,padding=2)在感受野范围上近似于一次$13\times 13$池化的感受野,但计算量更低。
重要说明:虽然感受野范围相似,但特征表示方式不同:
- SPP:并行池化,每个池化核独立处理原始特征
- SPPF:串联池化,每次池化基于前一次的结果,保留了中间特征图
感受野计算
对于3次连续的$5\times 5$池化(stride=1, padding=2),感受野的计算公式为: $$RF{new} = RF{old} + (kernel_size - 1) \times stride$$
具体计算过程:
- 第1次池化后:感受野 = $5$(kernel_size=5)
- 第2次池化后:感受野 = $5 + (5-1) \times 1 = 9$
- 第3次池化后:感受野 = $9 + (5-1) \times 1 = 13$
因此,3次$5\times 5$池化的累积感受野为$13$,与单次$13\times 13$池化在感受野范围上近似。但需要注意的是,虽然感受野范围相同,但特征提取方式不同:SPPF是串联累积,SPP是并行独立。
3.3 SPPF模块的优势
1. 减少参数量和计算量
MaxPool2d的计算复杂度主要取决于池化核大小和特征图尺寸:
-
SPP的总计算量:
- 5×5池化:$O(25 \times H \times W \times C)$
- 9×9池化:$O(81 \times H \times W \times C)$
- 13×13池化:$O(169 \times H \times W \times C)$
- 总计:$O((25 + 81 + 169) \times H \times W \times C) = O(275 \times H \times W \times C)$
-
SPPF的总计算量:
- 3次5×5池化:$O(3 \times 25 \times H \times W \times C) = O(75 \times H \times W \times C)$
结论:SPPF的计算量(75)明显低于SPP的总计算量(275),约为SPP的27%,但实际加速效果还受硬件实现、内存访问模式、缓存效率等因素影响。
2. 保留多尺度特征能力
通过叠加池化操作,仍能捕捉从局部到全局的上下文信息,提升模型对不同尺寸目标的检测能力。这是因为每一次池化的特征图都保存下来了,最终对3次池化的3张特征图和池化前的特征图进行了拼接。
关键区别:
- SPP:并行多尺度,每个尺度独立提取特征
- SPPF:串联累积,保留中间尺度信息
3. 硬件友好性
串联的池化操作更容易被GPU等硬件加速,尤其适合实时推理场景。小核池化对缓存更友好,能够更好地利用硬件资源。
📊 SPP vs SPPF对比
4.1 详细对比表
| 特性 | SPP | SPPF |
|---|---|---|
| 池化方式 | 并行不同尺寸池化核(5×5, 9×9, 13×13) | 串联相同小池化核(3次5×5) |
| 计算量 | 较高(需计算多个大核) | 较低(小核重复利用) |
| 感受野 | 多尺度(直接覆盖不同范围) | 等效大感受野(叠加实现,但特征表示不同) |
| 特征表示 | 并行多尺度特征 | 串联累积特征 |
| 内存占用 | 较高(需要存储多个大核池化结果) | 较低(中间结果可复用) |
| 适用场景 | 需要显式多尺度融合的任务 | 实时检测、计算资源受限的场景 |
| 代码复杂度 | 需要多个池化层 | 单个池化层重复使用 |
4.2 性能对比
根据YOLOv5的官方测试,SPPF相比SPP能够:
- 速度提升:推理速度提升2倍以上
- 精度保持:在大多数任务上精度基本不变
- 资源消耗:显存占用和计算量显著降低
4.3 选择建议
使用SPP的场景:
- 需要显式的多尺度特征表示
- 对精度要求极高,可以接受更高的计算成本
- 有充足的计算资源
使用SPPF的场景:
- 实时检测应用
- 移动设备部署
- 计算资源受限
- 需要平衡精度和速度
💻 代码实现分析
5.1 SPP模块源码解析
class SPP(nn.Module):
"""Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729."""
def __init__(self, c1, c2, k=(5, 9, 13)):
"""Initialize the SPP layer with input/output channels and pooling kernel sizes."""
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1) # 输入通道压缩
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1) # 输出通道调整
# 创建多个不同尺寸的池化层
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
"""Forward pass of the SPP layer, performing spatial pyramid pooling."""
x = self.cv1(x) # 先压缩通道
# 并行池化:原始特征 + 3个不同尺寸的池化结果
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))关键点:
c_ = c1 // 2:隐藏通道数是输入通道数的一半len(k) + 1:原始特征图 + k个池化结果,共len(k)+1个特征图padding=x // 2:保证池化后特征图尺寸不变
5.2 SPPF模块源码解析
class SPPF(nn.Module):
"""Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher."""
def __init__(self, c1, c2, k=5):
"""
Initializes the SPPF layer with given input/output channels and kernel size.
This module is equivalent to SPP(k=(5, 9, 13)).
"""
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1) # 输入通道压缩
self.cv2 = Conv(c_ * 4, c2, 1, 1) # 输出通道调整(4个特征图:原始+3次池化)
# 只创建一个池化层,重复使用
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
"""Forward pass through Ghost Convolution block."""
y = [self.cv1(x)] # 保存原始特征图
# 串联池化:每次池化基于前一次的结果
y.extend(self.m(y[-1]) for _ in range(3))
return self.cv2(torch.cat(y, 1)) # 拼接4个特征图关键点:
c_ * 4:固定4个特征图(原始 + 3次池化)self.m(y[-1]):每次池化基于前一次的结果(串联)y.extend(...):将每次池化的结果添加到列表中
5.3 关键差异对比
| 方面 | SPP | SPPF |
|---|---|---|
| 池化层数量 | 3个独立的池化层 | 1个池化层重复使用3次 |
| 池化方式 | 并行:所有池化都作用于原始特征 | 串联:每次池化基于前一次结果 |
| 特征图数量 | 4个(原始 + 3个池化结果) | 4个(原始 + 3个池化结果) |
| 通道计算 | c_ * (len(k) + 1) |
c_ * 4(固定) |
| 内存占用 | 较高(需要存储多个大核池化结果) | 较低(中间结果可复用) |
❓ 常见问题解答
Q1: SPPF真的和SPP效果一样吗?
A: 不完全一样,但效果相近:
- 感受野范围:SPPF通过3次5×5池化,累积感受野为13,与SPP的13×13池化在感受野范围上近似
- 特征表示:SPP是并行多尺度特征,SPPF是串联累积特征,表示方式不同
- 实际效果:在大多数检测任务上,SPPF的精度与SPP基本相当,但速度显著提升
Q2: 为什么3次5×5池化等效于1次13×13池化?
A: 这是基于感受野的计算:
- 3次连续的5×5池化(stride=1, padding=2)的累积感受野为13
- 计算公式:$RF{new} = RF{old} + (kernel_size - 1) \times stride$
- 第1次:RF=5,第2次:RF=5+(5-1)=9,第3次:RF=9+(5-1)=13
- 但需要注意的是,虽然感受野范围相同,但特征表示方式不同:SPPF是串联累积,SPP是并行独立
Q3: SPPF的计算量真的更少吗?
A: 是的,但需要具体分析:
- 理论计算量:
- SPP:3个池化核(5×5, 9×9, 13×13)总计算量 = 25 + 81 + 169 = 275
- SPPF:3次5×5池化总计算量 = 3 × 25 = 75
- SPPF约为SPP的27%,计算量显著降低
- 实际加速:还受硬件实现、内存访问、缓存效率等因素影响
- 整体效果:根据YOLOv5测试,SPPF整体速度提升2倍以上
Q4: 什么时候应该用SPP,什么时候用SPPF?
A: 选择建议:
使用SPP:
- 需要显式的多尺度特征表示
- 对精度要求极高,可以接受更高的计算成本
- 有充足的计算资源
使用SPPF:
- 实时检测应用
- 移动设备部署
- 计算资源受限
- 需要平衡精度和速度(推荐)
Q5: SPPF中的padding为什么是k//2?
A: 这是为了保持特征图尺寸不变:
- 对于kernel_size=k,stride=1的MaxPool2d,输出尺寸公式为: $$output_size = input_size + 2 \times padding - kernel_size + 1$$
- 要保证输出尺寸 = 输入尺寸,需要:$2 \times padding = kernel_size - 1$
- 因此:$padding = (kernel_size - 1) / 2$
- 对于奇数kernel_size(如5, 9, 13),
k//2等价于(k-1)/2,所以padding=k//2是正确的 - 例如:k=5时,padding=2,输出尺寸 = H + 2×2 - 5 + 1 = H(假设输入为H×W)
Q6: SPPF的forward中为什么用y[-1]?
A: 这是实现串联池化的关键:
y[-1]表示列表y中的最后一个元素- 第一次迭代:
y[-1]是原始特征图(y[0]) - 第二次迭代:
y[-1]是第一次池化的结果(y[1]) - 第三次迭代:
y[-1]是第二次池化的结果(y[2]) - 这样实现了串联池化:每次池化基于前一次的结果
Q7: SPP和SPPF的通道数计算为什么不同?
A: 虽然计算方式不同,但结果相同:
- SPP:
c_ * (len(k) + 1)=c_ * (3 + 1)=c_ * 4 - SPPF:
c_ * 4(固定) - 两者都是4个特征图拼接,所以通道数相同
📋 总结
核心要点
-
SPPF是SPP的优化版本:通过串联小池化核替代并行大池化核,在保持多尺度特征提取能力的同时提升计算效率
-
感受野等效性:3次5×5池化(stride=1)的累积感受野为13,与1次13×13池化在感受野范围上近似,但特征表示方式不同(串联累积 vs 并行独立)
-
计算效率提升:SPPF的计算量明显低于SPP,实际速度提升2倍以上
-
特征保留:SPPF通过保存每次池化的中间结果,保留了多尺度信息
-
适用场景:SPPF更适合实时检测和资源受限的场景,SPP更适合需要显式多尺度表示的场景
📁 相关文件位置
- SPP定义:
ultralytics/nn/modules/block.py:152-166 - SPPF定义:
ultralytics/nn/modules/block.py:169-188 - Conv定义:
ultralytics/nn/modules/conv.py - 配置文件示例:
ultralytics/cfg/models/11/yolo11.yaml