YOLO26 改进 – 注意力机制 HaloNet 局部自注意力 (Local Self-Attention) 以分块交互策略实现高效全局上下文建模
前言
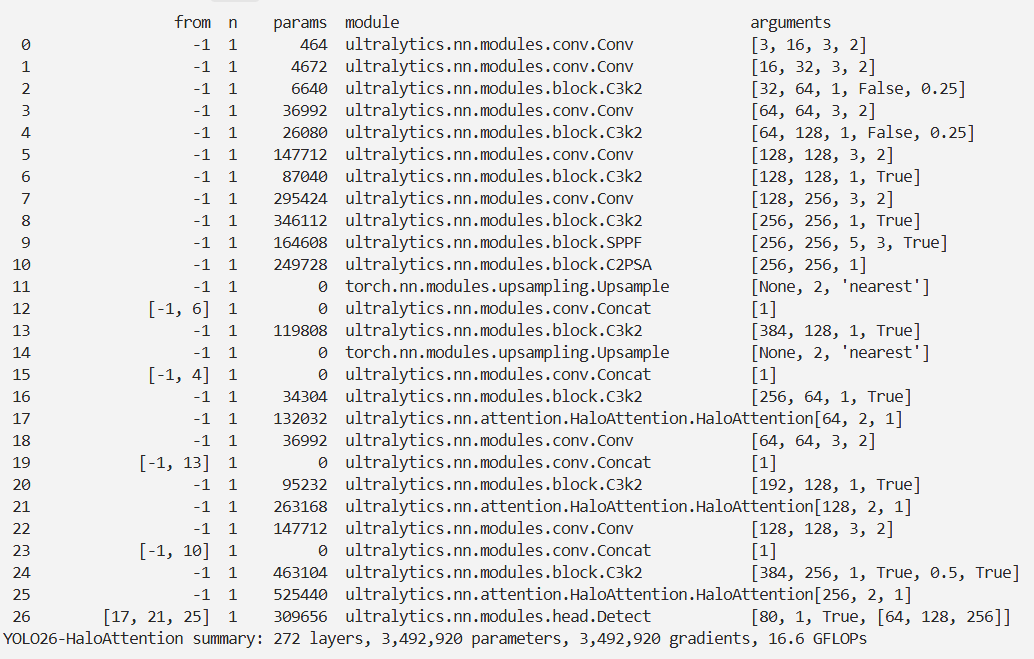
本文介绍了局部自注意力机制(HaloAttention)在YOLO26中的结合应用。局部自注意力通过关注输入数据局部区域来捕捉特征关系,能降低计算复杂度、增强局部特征捕捉,且可与CNN结合。其计算时先定义局部窗口,再计算注意力权重并加权求和。我们将HaloAttention集成到YOLO26的检测头中,并进行相关注册和配置。实验表明,改进后的模型在目标检测和实例分割等任务中表现更佳,证明了自注意力模型在传统卷积主导领域的有效性。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
介绍

摘要
自注意力机制凭借其与参数无关的感受野扩展能力以及基于内容的交互方式,被视作具有提升计算机视觉系统性能的潜力,这与卷积的参数依赖型感受野扩展以及与内容无关的交互方式形成了显著差异。近期研究显示,相较于基线卷积模型(如 ResNet - 50),自注意力模型在“精度 - 参数权衡”方面取得了令人振奋的改进。在本项工作中,我们致力于开发不仅能够超越经典基线模型,还能超越高性能卷积模型的自注意力模型。我们提出了两种自注意力的扩展方法,并结合一种更为高效的自注意力实现方式,提高了这些模型的速度、内存使用效率和准确性。基于这些改进,我们研发了一个新的自注意力模型家族,名为 HaloNets,其在参数受限的 ImageNet 分类基准测试中达到了当前最先进的精度水平。在初步的迁移学习实验中,我们发现 HaloNet 模型的表现优于规模更大的模型,且在推理性能方面更为出色。在诸如目标检测和实例分割等更具挑战性的任务中,我们提出的简单局部自注意力与卷积混合模型相较于非常强劲的基线模型也展现出性能改进。这些结果进一步证实了自注意力模型在传统上由卷积模型占据主导地位的领域中的有效性。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
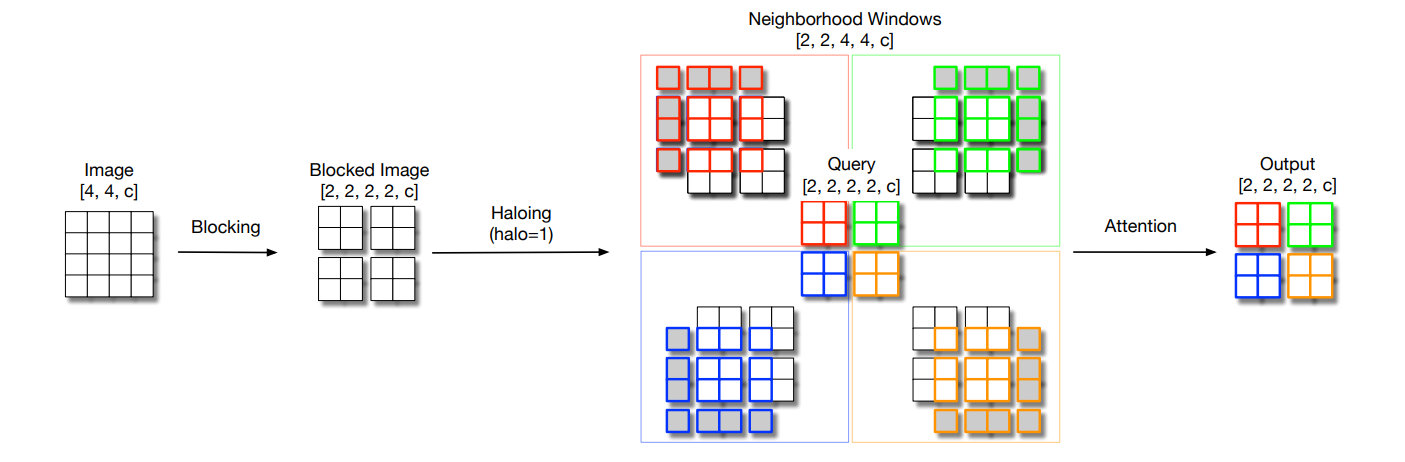
局部自注意力(Local Self-Attention)是一种自注意力机制的变体,主要用于处理图像和其他高维数据。它通过关注输入数据的局部区域来捕捉特征之间的关系,具有以下几个关键特点和优势:
1. 基本原理
局部自注意力的核心思想是计算输入数据中每个位置与其邻近位置之间的关系,而不是像全局自注意力那样考虑所有位置。这种方法通过限制注意力的范围来减少计算复杂度,同时仍然能够有效地捕捉局部特征。
2. 计算过程
在局部自注意力中,对于输入的每个位置,模型只计算该位置与其周围一定范围内的其他位置的注意力权重。这通常涉及以下步骤:
- 定义局部窗口:为每个位置定义一个局部窗口,窗口的大小可以根据任务需求进行调整。
- 计算注意力权重:在局部窗口内,计算每个位置的注意力权重,通常使用点积或其他相似性度量。
- 加权求和:使用计算得到的注意力权重对局部窗口内的特征进行加权求和,生成新的特征表示。
3. 优势
- 计算效率:局部自注意力显著降低了计算复杂度,因为它只关注局部区域,而不是整个输入。这使得在处理高分辨率图像时,模型能够更高效地运行。
- 增强局部特征捕捉:局部自注意力能够更好地捕捉图像中的局部特征,如边缘、纹理等,这对于图像分类、目标检测等任务非常重要。
- 灵活性:局部自注意力可以与卷积神经网络(CNN)等其他网络结构结合使用,形成混合模型,进一步提升性能。
4. 应用
局部自注意力在多个计算机视觉任务中得到了广泛应用,包括:
- 图像分类:通过捕捉局部特征来提高分类准确性。
- 目标检测:在检测过程中,局部自注意力可以帮助模型更好地理解对象的局部结构。
- 实例分割:在分割任务中,局部自注意力能够有效地处理不同对象之间的关系。
5. 局限性
尽管局部自注意力具有许多优势,但它也存在一些局限性:
- 信息丢失:由于只关注局部区域,可能会丢失全局上下文信息,影响模型的整体性能。
- 窗口大小选择:局部窗口的大小需要根据具体任务进行调整,过小可能导致信息不足,过大则可能增加计算负担。
核心代码
class HaloAttention(nn.Module):
def __init__(
self,
*,
dim,
block_size,
halo_size,
dim_head = 64,
heads = 8
):
super().__init__()
assert halo_size > 0, 'halo size must be greater than 0'
self.dim = dim
self.heads = heads
self.scale = dim_head ** -0.5
self.block_size = block_size
self.halo_size = halo_size
inner_dim = dim_head * heads
self.rel_pos_emb = RelPosEmb(
block_size = block_size,
rel_size = block_size + (halo_size * 2),
dim_head = dim_head
)
self.to_q = nn.Linear(dim, inner_dim, bias = False)
self.to_kv = nn.Linear(dim, inner_dim * 2, bias = False)
self.to_out = nn.Linear(inner_dim, dim)
def forward(self, x):
b, c, h, w, block, halo, heads, device = *x.shape, self.block_size, self.halo_size, self.heads, x.device
assert h % block == 0 and w % block == 0, 'fmap dimensions must be divisible by the block size'
assert c == self.dim, f'channels for input ({c}) does not equal to the correct dimension ({self.dim})'
# get block neighborhoods, and prepare a halo-ed version (blocks with padding) for deriving key values
q_inp = rearrange(x, 'b c (h p1) (w p2) -> (b h w) (p1 p2) c', p1 = block, p2 = block)
kv_inp = F.unfold(x, kernel_size = block + halo * 2, stride = block, padding = halo)
kv_inp = rearrange(kv_inp, 'b (c j) i -> (b i) j c', c = c)
# derive queries, keys, values
q = self.to_q(q_inp)
k, v = self.to_kv(kv_inp).chunk(2, dim = -1)
# split heads
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h = heads), (q, k, v))
# scale
q *= self.scale
# attention
sim = einsum('b i d, b j d -> b i j', q, k)
# add relative positional bias
sim += self.rel_pos_emb(q)
# mask out padding (in the paper, they claim to not need masks, but what about padding?)
mask = torch.ones(1, 1, h, w, device = device)
mask = F.unfold(mask, kernel_size = block + (halo * 2), stride = block, padding = halo)
mask = repeat(mask, '() j i -> (b i h) () j', b = b, h = heads)
mask = mask.bool()
max_neg_value = -torch.finfo(sim.dtype).max
sim.masked_fill_(mask, max_neg_value)
# attention
attn = sim.softmax(dim = -1)
# aggregate
out = einsum('b i j, b j d -> b i d', attn, v)
# merge and combine heads
out = rearrange(out, '(b h) n d -> b n (h d)', h = heads)
out = self.to_out(out)
# merge blocks back to original feature map
out = rearrange(out, '(b h w) (p1 p2) c -> b c (h p1) (w p2)', b = b, h = (h // block), w = (w // block), p1 = block, p2 = block)
return out实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-HaloAttention.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
amp=True,
project='runs/train',
name='yolo26-HaloAttention',
)
结果