YOLO26改进 – 注意力机制 ParNet并行子网络:多分支协同优化特征表达,增强模型判别能
前言
本文介绍了ParNet注意力机制及其在YOLO26中的应用。ParNet注意力通过并行子网络结构,将网络层组织成多个子网络并行处理输入特征,降低了传统注意力机制在处理长序列时的计算复杂度。该机制采用VGG风格的块和特征融合策略,具有低深度高性能、参数效率高、可扩展性强和并行化能力好等创新点。我们将ParNet注意力引入YOLO26,在检测头部分应用该机制。通过实验训练改进后的模型,有望提升YOLO26在目标检测任务中的性能。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@[TOC]
介绍

摘要
深度是深度神经网络的核心特征,然而网络深度的增加往往伴随着顺序计算量的上升和延迟时间的增长。这引发了一个关键性问题:是否能够构建出具有高性能的"非深度"神经网络?本文证实了这一可能性。为实现此目标,我们采用了并行子网络架构而非传统的层级堆叠方式,从而在维持高性能的同时显著降低了网络深度。通过充分利用并行子结构,我们首次展示了深度仅为12的网络能够在ImageNet数据集上实现超过80%的Top-1准确率,在CIFAR10上达到96%的准确率,在CIFAR100上达到81%的准确率。此外,我们还证明了深度为12的骨干网络在MS-COCO数据集上能够实现48%的平均精度(AP)。我们对这一设计的扩展规律进行了深入分析,并阐明了如何在保持网络深度不变的前提下提升性能表现。最后,我们提供了一个概念验证,展示了非深度网络在构建低延迟识别系统方面的应用潜力。相关代码已发布于https://github.com/imankgoyal/NonDeepNetworks。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
ParNet注意力是一种用于自然语言处理任务的注意力机制,它是由谷歌在2019年提出的。ParNet注意力旨在解决传统注意力机制在处理长序列时的效率问题。
传统的注意力机制在计算注意力权重时,需要对所有输入序列的位置进行逐一计算,这导致了在长序列上的计算复杂度较高。而ParNet注意力通过将序列分割成多个子序列,并对每个子序列进行独立的注意力计算,从而降低了计算复杂度。
技术原理
-
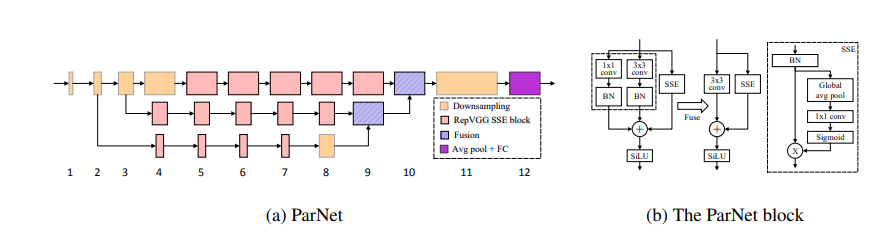
并行子网络结构:
- ParNet的核心设计是将网络层以并行的方式组织成多个子网络(或称为流)。每个子网络可以独立处理输入特征,并在后期阶段将这些特征融合。这种设计使得网络能够同时处理不同分辨率和特征的输入,从而提高了计算效率和性能。
-
VGG风格的块:
- ParNet采用了VGG风格的网络块,这种结构在特征提取方面表现良好。与ResNet风格的块相比,VGG块在训练时更容易收敛,尽管其训练难度相对较高。
-
特征融合:
- 在网络的后期阶段,来自不同子网络的特征会被融合,以便进行最终的分类或检测任务。这种特征融合策略使得网络能够综合不同流的信息,从而提高了模型的表现。
创新点
-
低深度高性能:
- ParNet展示了在仅有12层深度的情况下,仍然能够在多个基准测试中实现高于80%的准确率。这一发现挑战了传统深度学习的观念,表明深度并不是唯一的性能决定因素。
-
参数效率:
- ParNet在参数数量上与当前最先进的深度网络相当,但其深度显著减少。这使得ParNet在计算资源有限的情况下,仍能实现良好的性能。
-
可扩展性:
- ParNet的设计允许通过增加宽度、分辨率和分支数量来有效扩展性能,而不需要增加网络的深度。这种特性使得ParNet在处理大规模数据集时具有更好的灵活性。
-
并行化能力:
- 由于其并行结构,ParNet能够在多个处理器上高效并行化,尽管存在通信延迟的问题。这为未来的高效识别系统提供了可能性。
参考代码
https://blog.csdn.net/DM_zx/article/details/132381800
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ParNetAttention(nn.Module):
def __init__(self, channel=512):
super().__init__()
self.sse = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channel, channel, kernel_size=1),
nn.Sigmoid()
)
self.conv1x1 = nn.Sequential(
nn.Conv2d(channel, channel, kernel_size=1),
nn.BatchNorm2d(channel)
)
self.conv3x3 = nn.Sequential(
nn.Conv2d(channel, channel, kernel_size=3, padding=1),
nn.BatchNorm2d(channel)
)
self.silu = nn.SiLU()
def forward(self, x):
b, c, _, _ = x.size()
x1 = self.conv1x1(x)
x2 = self.conv3x3(x)
x3 = self.sse(x) * x
y = self.silu(x1 + x2 + x3)
return y
if __name__ == '__main__':
input = torch.randn(50, 512, 7, 7)
pna = ParNetAttention(channel=512)
output = pna(input)
print(output.shape)
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-ParNetAttention.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
# optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-ParNetAttention',
)