


前言
在机器学习模型的开发过程中,准确拟合特定数据分布是实现高性能模型的核心目标之一。然而,为了确保模型在未见数据上的泛化能力,构建高质量的训练数据集显得尤为关键。特别是在监督学习任务中,标注数据的精确性在很大程度上决定了模型性能的上限。
即便模型具备复杂的架构、包含数亿参数,或使用了大量的数据增强策略,若输入数据质量低劣,仍然难以获得令人满意的输出结果。因而,高质量数据构建被视为模型成功部署的基础。
在应对特定任务时,理想情形是能够直接利用已有的公开数据集。然而,现实场景往往缺乏完备、适配的公开资源,此时,开发者通常需要自行构建符合任务需求的专属数据集。这一过程中,原始数据往往处于未标注状态,标注过程成为不可或缺的一环。
演示
本文以一个由移动设备拍摄的图像数据集为例,旨在演示如何快速搭建一个轻量级图像分类标注工具,以便高效地将未标注图像按类别分类。本任务聚焦于区分四种常见的 USB 接口类型:USB-A、USB-C、Micro USB 以及 Mini USB。最初,所有图像文件存放于未标注的输入目录中,标注工具的职责是逐一展示这些图像,允许用户通过键盘操作对其进行分类,并将其移动至相应的输出子目录中。
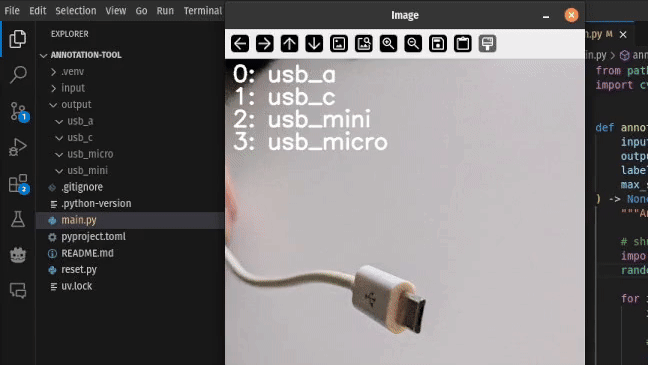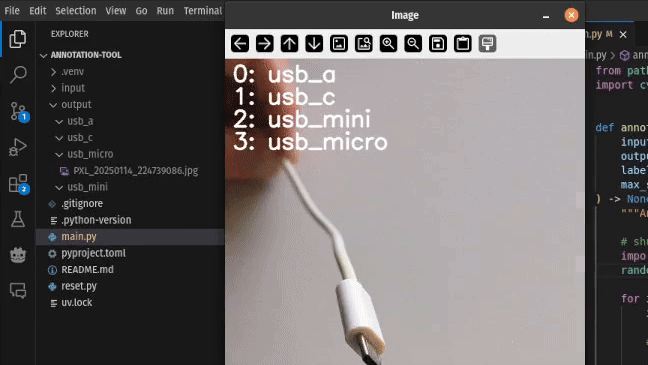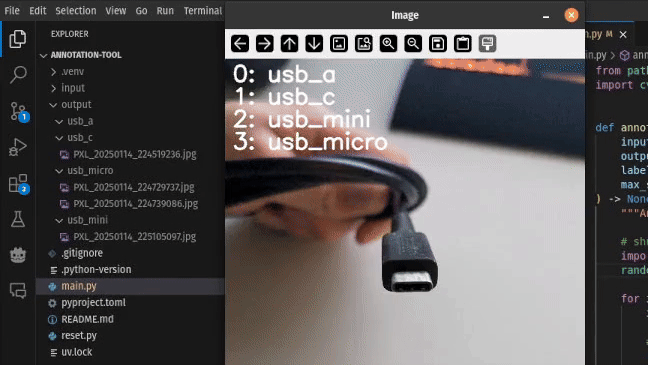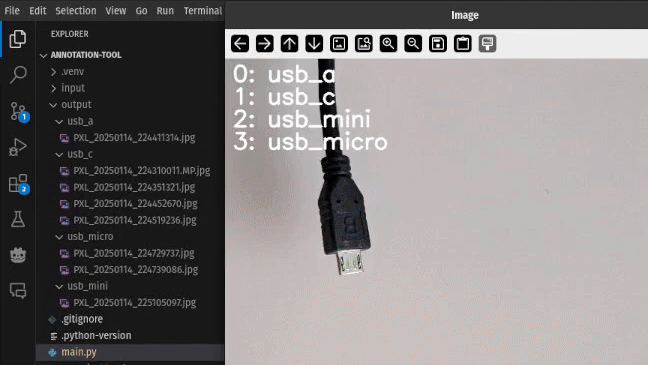
数据加载
标注过程的第一步是批量加载输入目录中的图像文件。借助 pathlib 库中的 glob 方法,程序可高效检索所有 .jpg 格式图像,并使用 sorted 进行排序,以确保处理顺序的一致性:
from pathlib import Path
input_path = Path("input")
input_img_paths = sorted(input_path.glob("*.jpg"))
在标注开始前,还需确保输出目录以及分类子目录的存在,以避免在写入操作时出现路径不存在的错误:
output_path = Path("output")
output_path.mkdir(parents=True, exist_ok=True)
接下来,程序将逐图加载图像并使用 OpenCV 显示在窗口中,等待用户输入分类指令。通过设置 cv2.waitKey(0),程序将阻塞执行,直至检测到按键输入。当检测到用户按下 Q 键时,标注流程优雅地终止,并关闭所有窗口:
import cv2
...
def annotate_images(
input_img_paths: list[Path],
output_path: Path,
)-> None:
for img_path in input_img_paths:
img = cv2.imread(str(img_path))
cv2.imshow("Image", img)
while True:
key = cv2.waitKey(0)
# Quit Annotation Tool
if key == ord("q"):
return
cv2.destroyAllWindows()
为了精确识别按键输入,推荐结合按位操作 & 0xFF 使用 ord() 函数,从而避免特殊按键状态(如 NumLock)对识别结果的干扰。

标注
任务中涉及的标签预先定义为一个字符串列表,与所需分类任务一一对应:
...
annotate_images(
input_img_paths=input_img_paths,
output_path=output_path,
labels=["usb_a", "usb_c", "usb_mini", "usb_micro"],
)
用户可通过按下数字键 0–3,将当前图像分配至对应的标签目录。具体地,waitKey() 返回的整数可与 ord(str(i)) 进行匹配判断,确定输入类别:
while True:
...
for i in range(len(labels)):
if key == ord(str(i)):
label = labels[i]
print(f"Classified as {label}")
# TODO: move to correct label folder
break
图像移动操作通过 pathlib 的 / 运算符实现路径拼接,配合 rename() 函数完成重定位:
output_img_path = output_path / label / img_path.name
img_path.rename(output_img_path)
所有输出目录需在程序启动时一次性创建完成:
for label in labels:
label_dir = output_path / label
label_dir.mkdir(parents=True, exist_ok=True)
为提高标注效率,可通过构建从按键值到标签名的映射字典来加速分类过程:
labels_key_dict = {ord(str(i)): label for i, label in enumerate(labels)}
if key in labels_key_dict:
label = labels_key_dict[key]
...
此外,为用户提供视觉提示,在图像上动态叠加数字键与标签的对应关系,有助于提升交互体验:
for i, label in enumerate(labels):
cv2.putText(
img,
f"{i}: {label}",
(10, 30 + 30 * i),
cv2.FONT_HERSHEY_SIMPLEX,
1,
(255, 255, 255),
2,
cv2.LINE_AA,
)
结论
本文介绍了一种简洁而高效的图像分类标注工具,适用于数据集构建的初始阶段。尽管功能相对基础,但该工具具有良好的扩展性。例如,后续可集成图像分割功能,实现同时生成掩码标签,拓展至语义分割等任务场景。
在项目早期阶段,特别是进行探索性数据分析或概念验证时,使用轻量化工具往往更具优势。它们能够以最小的开发成本,实现对核心问题的快速验证,为后续更大规模的数据处理与建模打下坚实基础。
完整代码
# 导入标准库 pathlib 中的 Path 类,用于处理文件路径
from pathlib import Path
# 导入 OpenCV 库用于图像处理
import cv2
def annotate_images(
input_img_paths: list[Path], # 输入图像路径列表
output_path: Path, # 输出目录路径
labels: list[str], # 标签列表,例如 ["usb_a", "usb_c", ...]
max_size_display: int = 640, # 图像最大显示尺寸(像素)
) -> None:
"""对图像进行分类标注,通过键盘输入将图像归入指定类别。"""
# 遍历每张待标注的图像路径
for img_path in input_img_paths:
# 读取图像为 BGR 格式的 NumPy 数组
img = cv2.imread(str(img_path))
# 计算缩放比例,使图像最长边为 max_size_display 像素
ratio = max_size_display / max(img.shape[:2])
# 按比例缩放图像
img = cv2.resize(img, None, fx=ratio, fy=ratio)
# 在图像上添加每个类别的键位提示文字(例如 "0: usb_a")
for i, label in enumerate(labels):
cv2.putText(
img,
f"{i}: {label}", # 显示文本:编号 + 标签名
(10, 30 + 30 * i), # 文本左上角坐标,逐行显示
cv2.FONT_HERSHEY_SIMPLEX, # 字体样式
1, # 字体大小
(255, 255, 255), # 字体颜色:白色
2, # 字体线宽
cv2.LINE_AA, # 抗锯齿绘制
)
# 构造按键与标签之间的映射字典,例如:{ord("0"): "usb_a"}
labels_key_dict = {ord(str(i)): label for i, label in enumerate(labels)}
# 为每个类别预创建输出文件夹(如果不存在则创建)
for label in labels:
label_dir = output_path / label
label_dir.mkdir(parents=True, exist_ok=True)
# 打开一个图像窗口显示当前图像
cv2.imshow("Image", img)
# 等待用户按键输入进行标注
while True:
key = cv2.waitKey(0) # 无限等待,直到有键被按下
# 如果按下的是 "q",则退出整个标注工具
if key == ord("q"):
return
# 如果按下的是有效的标签键(如 0/1/2/3)
if key in labels_key_dict:
label = labels_key_dict[key] # 获取对应标签名
print(f"Classified as {label}")
# 构造输出图像路径:output/标签名/原图名
output_img_path = output_path / label / img_path.name
# 将图像移动到对应类别目录中
img_path.rename(output_img_path)
break # 跳出当前图像循环,开始标注下一张图像
# 关闭所有 OpenCV 打开的图像窗口
cv2.destroyAllWindows()
def main():
# 设置输入目录路径为 "input"
input_path = Path("input")
# 加载所有 JPG 图像并按文件名排序
input_img_paths = sorted(input_path.glob("*.jpg"))
# 设置输出目录路径为 "output"
output_path = Path("output")
# 若输出目录不存在则递归创建
output_path.mkdir(parents=True, exist_ok=True)
# 调用标注函数,传入图像路径、输出路径和标签列表
annotate_images(
input_img_paths=input_img_paths,
output_path=output_path,
labels=["usb_a", "usb_c", "usb_mini", "usb_micro"], # 定义 4 个类别
)
# 判断当前脚本是否为主程序入口,若是则调用 main 函数
if __name__ == "__main__":
main()
评论区